 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReaching Beyond the Mode: RL for Distributional Reasoning in Language Models
Mar 25, 2026Given a question, a language model (LM) implicitly encodes a distribution over possible answers. In practice, post-training procedures for LMs often collapse this distribution onto a single dominant mode. While this is generally not a problem for benchmark-style evaluations that assume one correct answer, many real-world tasks inherently involve multiple valid answers or irreducible uncertainty. Examples include medical diagnosis, ambiguous question answering, and settings with incomplete information. In these cases, we would like LMs to generate multiple plausible hypotheses, ideally with confidence estimates for each one, and without computationally intensive repeated sampling to generate non-modal answers. This paper describes a multi-answer reinforcement learning approach for training LMs to perform distributional reasoning over multiple answers during inference. We modify the RL objective to enable models to explicitly generate multiple candidate answers in a single forward pass, internalizing aspects of inference-time search into the model's generative process. Across question-answering, medical diagnostic, and coding benchmarks, we observe improved diversity, coverage, and set-level calibration scores compared to single answer trained baselines. Models trained with our approach require fewer tokens to generate multiple answers than competing approaches. On coding tasks, they are also substantially more accurate. These results position multi-answer RL as a principled and compute-efficient alternative to inference-time scaling procedures such as best-of-k. Code and more information can be found at https://multi-answer-rl.github.io/.
Robustness Beyond Known Groups with Low-rank Adaptation
Feb 09, 2026Deep learning models trained to optimize average accuracy often exhibit systematic failures on particular subpopulations. In real world settings, the subpopulations most affected by such disparities are frequently unlabeled or unknown, thereby motivating the development of methods that are performant on sensitive subgroups without being pre-specified. However, existing group-robust methods typically assume prior knowledge of relevant subgroups, using group annotations for training or model selection. We propose Low-rank Error Informed Adaptation (LEIA), a simple two-stage method that improves group robustness by identifying a low-dimensional subspace in the representation space where model errors concentrate. LEIA restricts adaptation to this error-informed subspace via a low-rank adjustment to the classifier logits, directly targeting latent failure modes without modifying the backbone or requiring group labels. Using five real-world datasets, we analyze group robustness under three settings: (1) truly no knowledge of subgroup relevance, (2) partial knowledge of subgroup relevance, and (3) full knowledge of subgroup relevance. Across all settings, LEIA consistently improves worst-group performance while remaining fast, parameter-efficient, and robust to hyperparameter choice.
Explainable AI as a Double-Edged Sword in Dermatology: The Impact on Clinicians versus The Public
Dec 14, 2025Artificial intelligence (AI) is increasingly permeating healthcare, from physician assistants to consumer applications. Since AI algorithm's opacity challenges human interaction, explainable AI (XAI) addresses this by providing AI decision-making insight, but evidence suggests XAI can paradoxically induce over-reliance or bias. We present results from two large-scale experiments (623 lay people; 153 primary care physicians, PCPs) combining a fairness-based diagnosis AI model and different XAI explanations to examine how XAI assistance, particularly multimodal large language models (LLMs), influences diagnostic performance. AI assistance balanced across skin tones improved accuracy and reduced diagnostic disparities. However, LLM explanations yielded divergent effects: lay users showed higher automation bias - accuracy boosted when AI was correct, reduced when AI erred - while experienced PCPs remained resilient, benefiting irrespective of AI accuracy. Presenting AI suggestions first also led to worse outcomes when the AI was incorrect for both groups. These findings highlight XAI's varying impact based on expertise and timing, underscoring LLMs as a "double-edged sword" in medical AI and informing future human-AI collaborative system design.
SpaceVLM: Sub-Space Modeling of Negation in Vision-Language Models
Nov 15, 2025Vision-Language Models (VLMs) struggle with negation. Given a prompt like "retrieve (or generate) a street scene without pedestrians," they often fail to respect the "not." Existing methods address this limitation by fine-tuning on large negation datasets, but such retraining often compromises the model's zero-shot performance on affirmative prompts. We show that the embedding space of VLMs, such as CLIP, can be divided into semantically consistent subspaces. Based on this property, we propose a training-free framework that models negation as a subspace in the joint embedding space rather than a single point (Figure 1). To find the matching image for a caption such as "A but not N," we construct two spherical caps around the embeddings of A and N, and we score images by the central direction of the region that is close to A and far from N. Across retrieval, MCQ, and text-to-image tasks, our method improves negation understanding by about 30% on average over prior methods. It closes the gap between affirmative and negated prompts while preserving the zero-shot performance that fine-tuned models fail to maintain. Code will be released upon publication.
Train Long, Think Short: Curriculum Learning for Efficient Reasoning
Aug 12, 2025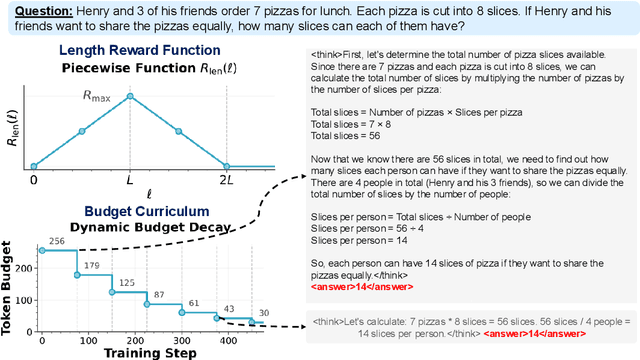



Recent work on enhancing the reasoning abilities of large language models (LLMs) has introduced explicit length control as a means of constraining computational cost while preserving accuracy. However, existing approaches rely on fixed-length training budgets, which do not take advantage of the natural progression from exploration to compression during learning. In this work, we propose a curriculum learning strategy for length-controlled reasoning using Group Relative Policy Optimization (GRPO). Our method starts with generous token budgets and gradually tightens them over training, encouraging models to first discover effective solution strategies and then distill them into more concise reasoning traces. We augment GRPO with a reward function that balances three signals: task correctness (via verifier feedback), length efficiency, and formatting adherence (via structural tags). Experiments on GSM8K, MATH500, SVAMP, College Math, and GSM+ demonstrate that curriculum-based training consistently outperforms fixed-budget baselines at the same final budget, achieving higher accuracy and significantly improved token efficiency. We further ablate the impact of reward weighting and decay schedule design, showing that progressive constraint serves as a powerful inductive bias for training efficient reasoning models. Our code and checkpoints are released at: https://github.com/hammoudhasan/curriculum_grpo.
Tiered Agentic Oversight: A Hierarchical Multi-Agent System for AI Safety in Healthcare
Jun 14, 2025Current large language models (LLMs), despite their power, can introduce safety risks in clinical settings due to limitations such as poor error detection and single point of failure. To address this, we propose Tiered Agentic Oversight (TAO), a hierarchical multi-agent framework that enhances AI safety through layered, automated supervision. Inspired by clinical hierarchies (e.g., nurse, physician, specialist), TAO conducts agent routing based on task complexity and agent roles. Leveraging automated inter- and intra-tier collaboration and role-playing, TAO creates a robust safety framework. Ablation studies reveal that TAO's superior performance is driven by its adaptive tiered architecture, which improves safety by over 3.2% compared to static single-tier configurations; the critical role of its lower tiers, particularly tier 1, whose removal most significantly impacts safety; and the strategic assignment of more advanced LLM to these initial tiers, which boosts performance by over 2% compared to less optimal allocations while achieving near-peak safety efficiently. These mechanisms enable TAO to outperform single-agent and multi-agent frameworks in 4 out of 5 healthcare safety benchmarks, showing up to an 8.2% improvement over the next-best methods in these evaluations. Finally, we validate TAO via an auxiliary clinician-in-the-loop study where integrating expert feedback improved TAO's accuracy in medical triage from 40% to 60%.
When Style Breaks Safety: Defending Language Models Against Superficial Style Alignment
Jun 09, 2025Large language models (LLMs) can be prompted with specific styles (e.g., formatting responses as lists), including in jailbreak queries. Although these style patterns are semantically unrelated to the malicious intents behind jailbreak queries, their safety impact remains unclear. In this work, we seek to understand whether style patterns compromise LLM safety, how superficial style alignment increases model vulnerability, and how best to mitigate these risks during alignment. We evaluate 32 LLMs across seven jailbreak benchmarks, and find that malicious queries with style patterns inflate the attack success rate (ASR) for nearly all models. Notably, ASR inflation correlates with both the length of style patterns and the relative attention an LLM exhibits on them. We then investigate superficial style alignment, and find that fine-tuning with specific styles makes LLMs more vulnerable to jailbreaks of those same styles. Finally, we propose SafeStyle, a defense strategy that incorporates a small amount of safety training data augmented to match the distribution of style patterns in the fine-tuning data. Across three LLMs and five fine-tuning style settings, SafeStyle consistently outperforms baselines in maintaining LLM safety.
KScope: A Framework for Characterizing the Knowledge Status of Language Models
Jun 09, 2025Characterizing a large language model's (LLM's) knowledge of a given question is challenging. As a result, prior work has primarily examined LLM behavior under knowledge conflicts, where the model's internal parametric memory contradicts information in the external context. However, this does not fully reflect how well the model knows the answer to the question. In this paper, we first introduce a taxonomy of five knowledge statuses based on the consistency and correctness of LLM knowledge modes. We then propose KScope, a hierarchical framework of statistical tests that progressively refines hypotheses about knowledge modes and characterizes LLM knowledge into one of these five statuses. We apply KScope to nine LLMs across four datasets and systematically establish: (1) Supporting context narrows knowledge gaps across models. (2) Context features related to difficulty, relevance, and familiarity drive successful knowledge updates. (3) LLMs exhibit similar feature preferences when partially correct or conflicted, but diverge sharply when consistently wrong. (4) Context summarization constrained by our feature analysis, together with enhanced credibility, further improves update effectiveness and generalizes across LLMs.
MedPAIR: Measuring Physicians and AI Relevance Alignment in Medical Question Answering
May 29, 2025Large Language Models (LLMs) have demonstrated remarkable performance on various medical question-answering (QA) benchmarks, including standardized medical exams. However, correct answers alone do not ensure correct logic, and models may reach accurate conclusions through flawed processes. In this study, we introduce the MedPAIR (Medical Dataset Comparing Physicians and AI Relevance Estimation and Question Answering) dataset to evaluate how physician trainees and LLMs prioritize relevant information when answering QA questions. We obtain annotations on 1,300 QA pairs from 36 physician trainees, labeling each sentence within the question components for relevance. We compare these relevance estimates to those for LLMs, and further evaluate the impact of these "relevant" subsets on downstream task performance for both physician trainees and LLMs. We find that LLMs are frequently not aligned with the content relevance estimates of physician trainees. After filtering out physician trainee-labeled irrelevant sentences, accuracy improves for both the trainees and the LLMs. All LLM and physician trainee-labeled data are available at: http://medpair.csail.mit.edu/.
MOSAIC: Modeling Social AI for Content Dissemination and Regulation in Multi-Agent Simulations
Apr 10, 2025



We present a novel, open-source social network simulation framework, MOSAIC, where generative language agents predict user behaviors such as liking, sharing, and flagging content. This simulation combines LLM agents with a directed social graph to analyze emergent deception behaviors and gain a better understanding of how users determine the veracity of online social content. By constructing user representations from diverse fine-grained personas, our system enables multi-agent simulations that model content dissemination and engagement dynamics at scale. Within this framework, we evaluate three different content moderation strategies with simulated misinformation dissemination, and we find that they not only mitigate the spread of non-factual content but also increase user engagement. In addition, we analyze the trajectories of popular content in our simulations, and explore whether simulation agents' articulated reasoning for their social interactions truly aligns with their collective engagement patterns. We open-source our simulation software to encourage further research within AI and social sciences.