 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Binary Rewards: Training LMs to Reason About Their Uncertainty
Jul 22, 2025When language models (LMs) are trained via reinforcement learning (RL) to generate natural language "reasoning chains", their performance improves on a variety of difficult question answering tasks. Today, almost all successful applications of RL for reasoning use binary reward functions that evaluate the correctness of LM outputs. Because such reward functions do not penalize guessing or low-confidence outputs, they often have the unintended side-effect of degrading calibration and increasing the rate at which LMs generate incorrect responses (or "hallucinate") in other problem domains. This paper describes RLCR (Reinforcement Learning with Calibration Rewards), an approach to training reasoning models that jointly improves accuracy and calibrated confidence estimation. During RLCR, LMs generate both predictions and numerical confidence estimates after reasoning. They are trained to optimize a reward function that augments a binary correctness score with a Brier score -- a scoring rule for confidence estimates that incentivizes calibrated prediction. We first prove that this reward function (or any analogous reward function that uses a bounded, proper scoring rule) yields models whose predictions are both accurate and well-calibrated. We next show that across diverse datasets, RLCR substantially improves calibration with no loss in accuracy, on both in-domain and out-of-domain evaluations -- outperforming both ordinary RL training and classifiers trained to assign post-hoc confidence scores. While ordinary RL hurts calibration, RLCR improves it. Finally, we demonstrate that verbalized confidence can be leveraged at test time to improve accuracy and calibration via confidence-weighted scaling methods. Our results show that explicitly optimizing for calibration can produce more generally reliable reasoning models.
A System for Accurate Tracking and Video Recordings of Rodent Eye Movements using Convolutional Neural Networks for Biomedical Image Segmentation
Jun 09, 2025Research in neuroscience and vision science relies heavily on careful measurements of animal subject's gaze direction. Rodents are the most widely studied animal subjects for such research because of their economic advantage and hardiness. Recently, video based eye trackers that use image processing techniques have become a popular option for gaze tracking because they are easy to use and are completely noninvasive. Although significant progress has been made in improving the accuracy and robustness of eye tracking algorithms, unfortunately, almost all of the techniques have focused on human eyes, which does not account for the unique characteristics of the rodent eye images, e.g., variability in eye parameters, abundance of surrounding hair, and their small size. To overcome these unique challenges, this work presents a flexible, robust, and highly accurate model for pupil and corneal reflection identification in rodent gaze determination that can be incrementally trained to account for variability in eye parameters encountered in the field. To the best of our knowledge, this is the first paper that demonstrates a highly accurate and practical biomedical image segmentation based convolutional neural network architecture for pupil and corneal reflection identification in eye images. This new method, in conjunction with our automated infrared videobased eye recording system, offers the state of the art technology in eye tracking for neuroscience and vision science research for rodents.
CoFrNets: Interpretable Neural Architecture Inspired by Continued Fractions
Jun 05, 2025In recent years there has been a considerable amount of research on local post hoc explanations for neural networks. However, work on building interpretable neural architectures has been relatively sparse. In this paper, we present a novel neural architecture, CoFrNet, inspired by the form of continued fractions which are known to have many attractive properties in number theory, such as fast convergence of approximations to real numbers. We show that CoFrNets can be efficiently trained as well as interpreted leveraging their particular functional form. Moreover, we prove that such architectures are universal approximators based on a proof strategy that is different than the typical strategy used to prove universal approximation results for neural networks based on infinite width (or depth), which is likely to be of independent interest. We experiment on nonlinear synthetic functions and are able to accurately model as well as estimate feature attributions and even higher order terms in some cases, which is a testament to the representational power as well as interpretability of such architectures. To further showcase the power of CoFrNets, we experiment on seven real datasets spanning tabular, text and image modalities, and show that they are either comparable or significantly better than other interpretable models and multilayer perceptrons, sometimes approaching the accuracies of state-of-the-art models.
MedPAIR: Measuring Physicians and AI Relevance Alignment in Medical Question Answering
May 29, 2025Large Language Models (LLMs) have demonstrated remarkable performance on various medical question-answering (QA) benchmarks, including standardized medical exams. However, correct answers alone do not ensure correct logic, and models may reach accurate conclusions through flawed processes. In this study, we introduce the MedPAIR (Medical Dataset Comparing Physicians and AI Relevance Estimation and Question Answering) dataset to evaluate how physician trainees and LLMs prioritize relevant information when answering QA questions. We obtain annotations on 1,300 QA pairs from 36 physician trainees, labeling each sentence within the question components for relevance. We compare these relevance estimates to those for LLMs, and further evaluate the impact of these "relevant" subsets on downstream task performance for both physician trainees and LLMs. We find that LLMs are frequently not aligned with the content relevance estimates of physician trainees. After filtering out physician trainee-labeled irrelevant sentences, accuracy improves for both the trainees and the LLMs. All LLM and physician trainee-labeled data are available at: http://medpair.csail.mit.edu/.
A Probabilistic Inference Approach to Inference-Time Scaling of LLMs using Particle-Based Monte Carlo Methods
Feb 04, 2025Large language models (LLMs) have achieved significant performance gains via scaling up model sizes and/or data. However, recent evidence suggests diminishing returns from such approaches, motivating scaling the computation spent at inference time. Existing inference-time scaling methods, usually with reward models, cast the task as a search problem, which tends to be vulnerable to reward hacking as a consequence of approximation errors in reward models. In this paper, we instead cast inference-time scaling as a probabilistic inference task and leverage sampling-based techniques to explore the typical set of the state distribution of a state-space model with an approximate likelihood, rather than optimize for its mode directly. We propose a novel inference-time scaling approach by adapting particle-based Monte Carlo methods to this task. Our empirical evaluation demonstrates that our methods have a 4-16x better scaling rate over our deterministic search counterparts on various challenging mathematical reasoning tasks. Using our approach, we show that Qwen2.5-Math-1.5B-Instruct can surpass GPT-4o accuracy in only 4 rollouts, while Qwen2.5-Math-7B-Instruct scales to o1 level accuracy in only 32 rollouts. Our work not only presents an effective method to inference-time scaling, but also connects the rich literature in probabilistic inference with inference-time scaling of LLMs to develop more robust algorithms in future work. Code and further information is available at https://probabilistic-inference-scaling.github.io.
Can AI Relate: Testing Large Language Model Response for Mental Health Support
May 20, 2024



Large language models (LLMs) are already being piloted for clinical use in hospital systems like NYU Langone, Dana-Farber and the NHS. A proposed deployment use case is psychotherapy, where a LLM-powered chatbot can treat a patient undergoing a mental health crisis. Deployment of LLMs for mental health response could hypothetically broaden access to psychotherapy and provide new possibilities for personalizing care. However, recent high-profile failures, like damaging dieting advice offered by the Tessa chatbot to patients with eating disorders, have led to doubt about their reliability in high-stakes and safety-critical settings. In this work, we develop an evaluation framework for determining whether LLM response is a viable and ethical path forward for the automation of mental health treatment. Using human evaluation with trained clinicians and automatic quality-of-care metrics grounded in psychology research, we compare the responses provided by peer-to-peer responders to those provided by a state-of-the-art LLM. We show that LLMs like GPT-4 use implicit and explicit cues to infer patient demographics like race. We then show that there are statistically significant discrepancies between patient subgroups: Responses to Black posters consistently have lower empathy than for any other demographic group (2%-13% lower than the control group). Promisingly, we do find that the manner in which responses are generated significantly impacts the quality of the response. We conclude by proposing safety guidelines for the potential deployment of LLMs for mental health response.
Improving Black-box Robustness with In-Context Rewriting
Feb 15, 2024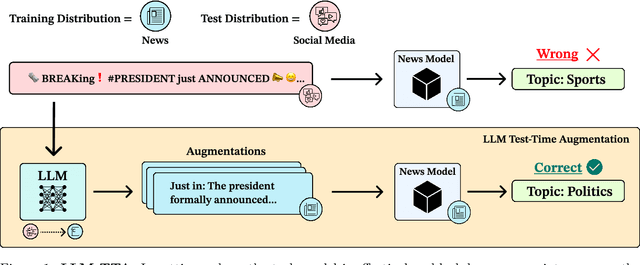
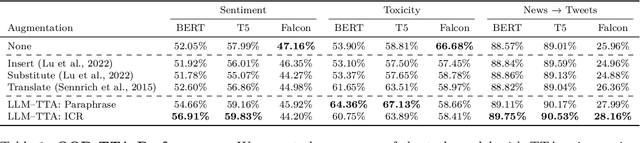
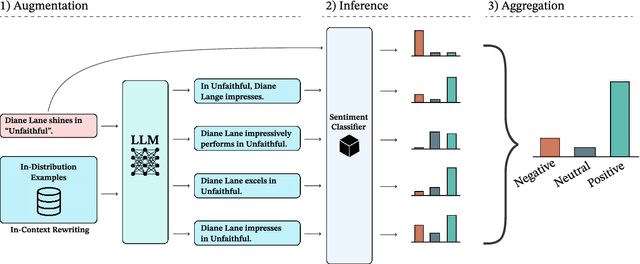
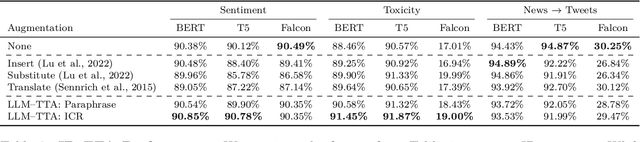
Machine learning models often excel on in-distribution (ID) data but struggle with unseen out-of-distribution (OOD) inputs. Most techniques for improving OOD robustness are not applicable to settings where the model is effectively a black box, such as when the weights are frozen, retraining is costly, or the model is leveraged via an API. Test-time augmentation (TTA) is a simple post-hoc technique for improving robustness that sidesteps black-box constraints by aggregating predictions across multiple augmentations of the test input. TTA has seen limited use in NLP due to the challenge of generating effective natural language augmentations. In this work, we propose LLM-TTA, which uses LLM-generated augmentations as TTA's augmentation function. LLM-TTA outperforms conventional augmentation functions across sentiment, toxicity, and news classification tasks for BERT and T5 models, with BERT's OOD robustness improving by an average of 4.30 percentage points without regressing average ID performance. We explore selectively augmenting inputs based on prediction entropy to reduce the rate of expensive LLM augmentations, allowing us to maintain performance gains while reducing the average number of generated augmentations by 57.76%. LLM-TTA is agnostic to the task model architecture, does not require OOD labels, and is effective across low and high-resource settings. We share our data, models, and code for reproducibility.
OpenXAI: Towards a Transparent Evaluation of Model Explanations
Jun 22, 2022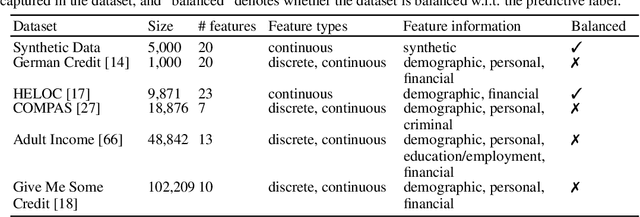
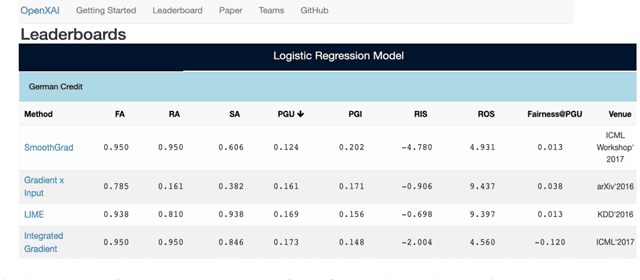
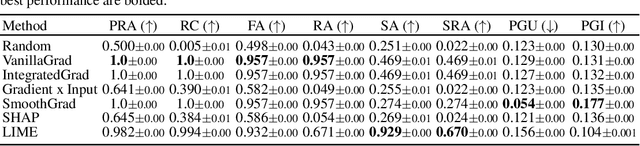
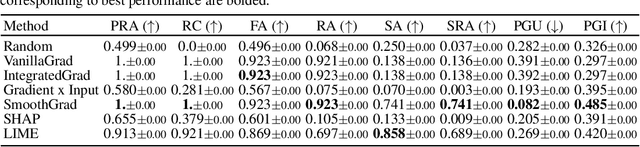
While several types of post hoc explanation methods (e.g., feature attribution methods) have been proposed in recent literature, there is little to no work on systematically benchmarking these methods in an efficient and transparent manner. Here, we introduce OpenXAI, a comprehensive and extensible open source framework for evaluating and benchmarking post hoc explanation methods. OpenXAI comprises of the following key components: (i) a flexible synthetic data generator and a collection of diverse real-world datasets, pre-trained models, and state-of-the-art feature attribution methods, (ii) open-source implementations of twenty-two quantitative metrics for evaluating faithfulness, stability (robustness), and fairness of explanation methods, and (iii) the first ever public XAI leaderboards to benchmark explanations. OpenXAI is easily extensible, as users can readily evaluate custom explanation methods and incorporate them into our leaderboards. Overall, OpenXAI provides an automated end-to-end pipeline that not only simplifies and standardizes the evaluation of post hoc explanation methods, but also promotes transparency and reproducibility in benchmarking these methods. OpenXAI datasets and data loaders, implementations of state-of-the-art explanation methods and evaluation metrics, as well as leaderboards are publicly available at https://open-xai.github.io/.