 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRunning the Gauntlet: Re-evaluating the Capabilities of Agents Beyond Familiar Environments
Jun 12, 2026As agentic systems continue to evolve and are widely deployed in real-world scenarios, there is a growing demand to faithfully evaluate their capabilities. However, current benchmarks are typically built on popular applications with relatively simple tasks and focus on a narrow set of capabilities while overlooking broader dimensions, resulting in saturated performance on modern agents and failing to probe their limitations. To this end, we introduce GauntletBench, a web-based benchmark for evaluating agent generalisation in challenging scenarios, focusing on three underexplored capabilities (temporal perception, graphical understanding, and 3D reasoning), across five less-covered professional applications (Video Editor, Workflow Builder, 3D Modeller, Flight Analyser, and Circuit Designer), each with 20 vision-intensive tasks (100 in total). Our benchmark provides a modular pipeline that comprises an environment compatible with both open- and closed-source agent frameworks, a controlled web-based application, a well-structured task suite, and an automated evaluation engine with diverse metrics. Contrary to widespread expectations, our empirical results reveal that frontier agentic systems remain far from achieving human-level performance. Even the state-of-the-art agent achieves only a 19.1% success rate on our GauntletBench, highlighting the limitations in these overlooked capabilities and generalisation. By comparison, non-expert human annotators achieve over 80% success on our challenging yet feasible tasks, revealing the substantial gap between current agent capabilities and those required for complex real-world scenarios.
Disparities In Negation Understanding Across Languages In Vision-Language Models
Apr 21, 2026Vision-language models (VLMs) exhibit affirmation bias: a systematic tendency to select positive captions ("X is present") even when the correct description contains negation ("no X"). While prior work has documented this failure mode in English and proposed solutions, negation manifests differently across languages through varying morphology, word order, and cliticization patterns, raising the question of whether these solutions serve all linguistic communities equitably. We introduce the first human-verified multilingual negation benchmark, spanning seven typologically diverse languages: English, Mandarin Chinese, Arabic, Greek, Russian, Tagalog, and Spanish. Evaluating three VLMs - CLIP, SigLIP, and MultiCLIP - we find that standard CLIP performs at or below chance on non-Latin-script languages, while MultiCLIP achieves the highest and most uniform accuracy. We also evaluate SpaceVLM, a proposed negation correction, and find that it produces substantial improvements for several languages - particularly English, Greek, Spanish, and Tagalog - while showing varied effectiveness across typologically different languages. This variation reveals that linguistic properties like morphology, script, and negation structure interact with model improvements in fairness-relevant ways. As VLMs are deployed globally, multilingual benchmarks are essential for understanding not just whether solutions work, but for whom.
SpaceVLM: Sub-Space Modeling of Negation in Vision-Language Models
Nov 15, 2025Vision-Language Models (VLMs) struggle with negation. Given a prompt like "retrieve (or generate) a street scene without pedestrians," they often fail to respect the "not." Existing methods address this limitation by fine-tuning on large negation datasets, but such retraining often compromises the model's zero-shot performance on affirmative prompts. We show that the embedding space of VLMs, such as CLIP, can be divided into semantically consistent subspaces. Based on this property, we propose a training-free framework that models negation as a subspace in the joint embedding space rather than a single point (Figure 1). To find the matching image for a caption such as "A but not N," we construct two spherical caps around the embeddings of A and N, and we score images by the central direction of the region that is close to A and far from N. Across retrieval, MCQ, and text-to-image tasks, our method improves negation understanding by about 30% on average over prior methods. It closes the gap between affirmative and negated prompts while preserving the zero-shot performance that fine-tuned models fail to maintain. Code will be released upon publication.
Train Long, Think Short: Curriculum Learning for Efficient Reasoning
Aug 12, 2025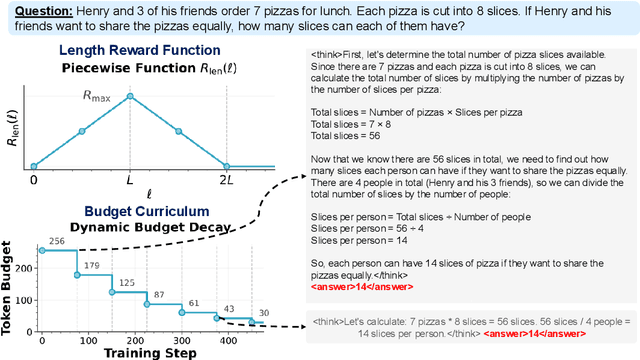



Recent work on enhancing the reasoning abilities of large language models (LLMs) has introduced explicit length control as a means of constraining computational cost while preserving accuracy. However, existing approaches rely on fixed-length training budgets, which do not take advantage of the natural progression from exploration to compression during learning. In this work, we propose a curriculum learning strategy for length-controlled reasoning using Group Relative Policy Optimization (GRPO). Our method starts with generous token budgets and gradually tightens them over training, encouraging models to first discover effective solution strategies and then distill them into more concise reasoning traces. We augment GRPO with a reward function that balances three signals: task correctness (via verifier feedback), length efficiency, and formatting adherence (via structural tags). Experiments on GSM8K, MATH500, SVAMP, College Math, and GSM+ demonstrate that curriculum-based training consistently outperforms fixed-budget baselines at the same final budget, achieving higher accuracy and significantly improved token efficiency. We further ablate the impact of reward weighting and decay schedule design, showing that progressive constraint serves as a powerful inductive bias for training efficient reasoning models. Our code and checkpoints are released at: https://github.com/hammoudhasan/curriculum_grpo.
MedPAIR: Measuring Physicians and AI Relevance Alignment in Medical Question Answering
May 29, 2025Large Language Models (LLMs) have demonstrated remarkable performance on various medical question-answering (QA) benchmarks, including standardized medical exams. However, correct answers alone do not ensure correct logic, and models may reach accurate conclusions through flawed processes. In this study, we introduce the MedPAIR (Medical Dataset Comparing Physicians and AI Relevance Estimation and Question Answering) dataset to evaluate how physician trainees and LLMs prioritize relevant information when answering QA questions. We obtain annotations on 1,300 QA pairs from 36 physician trainees, labeling each sentence within the question components for relevance. We compare these relevance estimates to those for LLMs, and further evaluate the impact of these "relevant" subsets on downstream task performance for both physician trainees and LLMs. We find that LLMs are frequently not aligned with the content relevance estimates of physician trainees. After filtering out physician trainee-labeled irrelevant sentences, accuracy improves for both the trainees and the LLMs. All LLM and physician trainee-labeled data are available at: http://medpair.csail.mit.edu/.
Vision-Language Models Do Not Understand Negation
Jan 16, 2025



Many practical vision-language applications require models that understand negation, e.g., when using natural language to retrieve images which contain certain objects but not others. Despite advancements in vision-language models (VLMs) through large-scale training, their ability to comprehend negation remains underexplored. This study addresses the question: how well do current VLMs understand negation? We introduce NegBench, a new benchmark designed to evaluate negation understanding across 18 task variations and 79k examples spanning image, video, and medical datasets. The benchmark consists of two core tasks designed to evaluate negation understanding in diverse multimodal settings: Retrieval with Negation and Multiple Choice Questions with Negated Captions. Our evaluation reveals that modern VLMs struggle significantly with negation, often performing at chance level. To address these shortcomings, we explore a data-centric approach wherein we finetune CLIP models on large-scale synthetic datasets containing millions of negated captions. We show that this approach can result in a 10% increase in recall on negated queries and a 40% boost in accuracy on multiple-choice questions with negated captions.
FedMedICL: Towards Holistic Evaluation of Distribution Shifts in Federated Medical Imaging
Jul 11, 2024



For medical imaging AI models to be clinically impactful, they must generalize. However, this goal is hindered by (i) diverse types of distribution shifts, such as temporal, demographic, and label shifts, and (ii) limited diversity in datasets that are siloed within single medical institutions. While these limitations have spurred interest in federated learning, current evaluation benchmarks fail to evaluate different shifts simultaneously. However, in real healthcare settings, multiple types of shifts co-exist, yet their impact on medical imaging performance remains unstudied. In response, we introduce FedMedICL, a unified framework and benchmark to holistically evaluate federated medical imaging challenges, simultaneously capturing label, demographic, and temporal distribution shifts. We comprehensively evaluate several popular methods on six diverse medical imaging datasets (totaling 550 GPU hours). Furthermore, we use FedMedICL to simulate COVID-19 propagation across hospitals and evaluate whether methods can adapt to pandemic changes in disease prevalence. We find that a simple batch balancing technique surpasses advanced methods in average performance across FedMedICL experiments. This finding questions the applicability of results from previous, narrow benchmarks in real-world medical settings.
Real-Time Evaluation in Online Continual Learning: A New Paradigm
Feb 02, 2023



Current evaluations of Continual Learning (CL) methods typically assume that there is no constraint on training time and computation. This is an unrealistic assumption for any real-world setting, which motivates us to propose: a practical real-time evaluation of continual learning, in which the stream does not wait for the model to complete training before revealing the next data for predictions. To do this, we evaluate current CL methods with respect to their computational costs. We hypothesize that under this new evaluation paradigm, computationally demanding CL approaches may perform poorly on streams with a varying distribution. We conduct extensive experiments on CLOC, a large-scale dataset containing 39 million time-stamped images with geolocation labels. We show that a simple baseline outperforms state-of-the-art CL methods under this evaluation, questioning the applicability of existing methods in realistic settings. In addition, we explore various CL components commonly used in the literature, including memory sampling strategies and regularization approaches. We find that all considered methods fail to be competitive against our simple baseline. This surprisingly suggests that the majority of existing CL literature is tailored to a specific class of streams that is not practical. We hope that the evaluation we provide will be the first step towards a paradigm shift to consider the computational cost in the development of online continual learning methods.
PIVOT: Prompting for Video Continual Learning
Dec 09, 2022



Modern machine learning pipelines are limited due to data availability, storage quotas, privacy regulations, and expensive annotation processes. These constraints make it difficult or impossible to maintain a large-scale model trained on growing annotation sets. Continual learning directly approaches this problem, with the ultimate goal of devising methods where a neural network effectively learns relevant patterns for new (unseen) classes without significantly altering its performance on previously learned ones. In this paper, we address the problem of continual learning for video data. We introduce PIVOT, a novel method that leverages the extensive knowledge in pre-trained models from the image domain, thereby reducing the number of trainable parameters and the associated forgetting. Unlike previous methods, ours is the first approach that effectively uses prompting mechanisms for continual learning without any in-domain pre-training. Our experiments show that PIVOT improves state-of-the-art methods by a significant 27% on the 20-task ActivityNet setup.
Generalizability of Adversarial Robustness Under Distribution Shifts
Sep 29, 2022
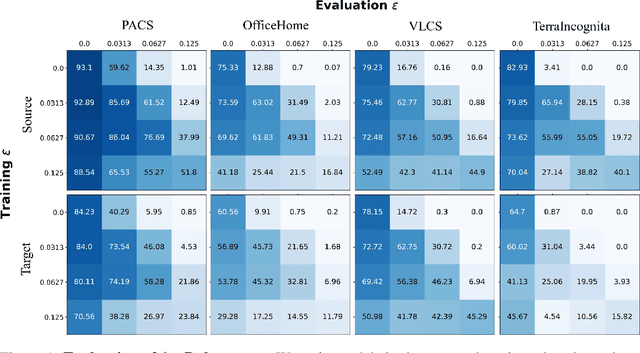
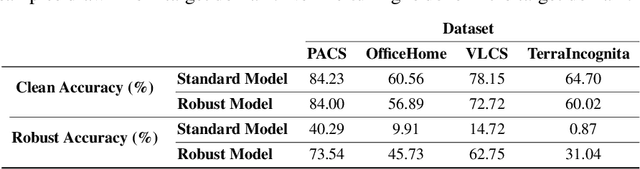
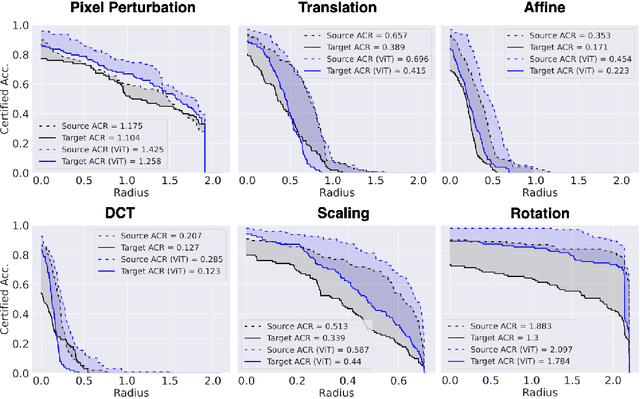
Recent progress in empirical and certified robustness promises to deliver reliable and deployable Deep Neural Networks (DNNs). Despite that success, most existing evaluations of DNN robustness have been done on images sampled from the same distribution that the model was trained on. Yet, in the real world, DNNs may be deployed in dynamic environments that exhibit significant distribution shifts. In this work, we take a first step towards thoroughly investigating the interplay between empirical and certified adversarial robustness on one hand and domain generalization on another. To do so, we train robust models on multiple domains and evaluate their accuracy and robustness on an unseen domain. We observe that: (1) both empirical and certified robustness generalize to unseen domains, and (2) the level of generalizability does not correlate well with input visual similarity, measured by the FID between source and target domains. We also extend our study to cover a real-world medical application, in which adversarial augmentation enhances both the robustness and generalization accuracy in unseen domains.