 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Role-Playing Agents Practice What They Preach? Belief-Behavior Consistency in LLM-Based Simulations of Human Trust
Jul 02, 2025As LLMs are increasingly studied as role-playing agents to generate synthetic data for human behavioral research, ensuring that their outputs remain coherent with their assigned roles has become a critical concern. In this paper, we investigate how consistently LLM-based role-playing agents' stated beliefs about the behavior of the people they are asked to role-play ("what they say") correspond to their actual behavior during role-play ("how they act"). Specifically, we establish an evaluation framework to rigorously measure how well beliefs obtained by prompting the model can predict simulation outcomes in advance. Using an augmented version of the GenAgents persona bank and the Trust Game (a standard economic game used to quantify players' trust and reciprocity), we introduce a belief-behavior consistency metric to systematically investigate how it is affected by factors such as: (1) the types of beliefs we elicit from LLMs, like expected outcomes of simulations versus task-relevant attributes of individual characters LLMs are asked to simulate; (2) when and how we present LLMs with relevant information about Trust Game; and (3) how far into the future we ask the model to forecast its actions. We also explore how feasible it is to impose a researcher's own theoretical priors in the event that the originally elicited beliefs are misaligned with research objectives. Our results reveal systematic inconsistencies between LLMs' stated (or imposed) beliefs and the outcomes of their role-playing simulation, at both an individual- and population-level. Specifically, we find that, even when models appear to encode plausible beliefs, they may fail to apply them in a consistent way. These findings highlight the need to identify how and when LLMs' stated beliefs align with their simulated behavior, allowing researchers to use LLM-based agents appropriately in behavioral studies.
Distilling Tool Knowledge into Language Models via Back-Translated Traces
Jun 23, 2025Large language models (LLMs) often struggle with mathematical problems that require exact computation or multi-step algebraic reasoning. Tool-integrated reasoning (TIR) offers a promising solution by leveraging external tools such as code interpreters to ensure correctness, but it introduces inference-time dependencies that hinder scalability and deployment. In this work, we propose a new paradigm for distilling tool knowledge into LLMs purely through natural language. We first construct a Solver Agent that solves math problems by interleaving planning, symbolic tool calls, and reflective reasoning. Then, using a back-translation pipeline powered by multiple LLM-based agents, we convert interleaved TIR traces into natural language reasoning traces. A Translator Agent generates explanations for individual tool calls, while a Rephrase Agent merges them into a fluent and globally coherent narrative. Empirically, we show that fine-tuning a small open-source model on these synthesized traces enables it to internalize both tool knowledge and structured reasoning patterns, yielding gains on competition-level math benchmarks without requiring tool access at inference.
OWL: Optimized Workforce Learning for General Multi-Agent Assistance in Real-World Task Automation
May 29, 2025Large Language Model (LLM)-based multi-agent systems show promise for automating real-world tasks but struggle to transfer across domains due to their domain-specific nature. Current approaches face two critical shortcomings: they require complete architectural redesign and full retraining of all components when applied to new domains. We introduce Workforce, a hierarchical multi-agent framework that decouples strategic planning from specialized execution through a modular architecture comprising: (i) a domain-agnostic Planner for task decomposition, (ii) a Coordinator for subtask management, and (iii) specialized Workers with domain-specific tool-calling capabilities. This decoupling enables cross-domain transferability during both inference and training phases: During inference, Workforce seamlessly adapts to new domains by adding or modifying worker agents; For training, we introduce Optimized Workforce Learning (OWL), which improves generalization across domains by optimizing a domain-agnostic planner with reinforcement learning from real-world feedback. To validate our approach, we evaluate Workforce on the GAIA benchmark, covering various realistic, multi-domain agentic tasks. Experimental results demonstrate Workforce achieves open-source state-of-the-art performance (69.70%), outperforming commercial systems like OpenAI's Deep Research by 2.34%. More notably, our OWL-trained 32B model achieves 52.73% accuracy (+16.37%) and demonstrates performance comparable to GPT-4o on challenging tasks. To summarize, by enabling scalable generalization and modular domain transfer, our work establishes a foundation for the next generation of general-purpose AI assistants.
VLMs Play StarCraft II: A Benchmark and Multimodal Decision Method
Mar 07, 2025We introduce VLM-Attention, a multimodal StarCraft II environment that aligns artificial agent perception with the human gameplay experience. Traditional frameworks such as SMAC rely on abstract state representations that diverge significantly from human perception, limiting the ecological validity of agent behavior. Our environment addresses this limitation by incorporating RGB visual inputs and natural language observations that more closely simulate human cognitive processes during gameplay. The VLM-Attention framework consists of three integrated components: (1) a vision-language model enhanced with specialized self-attention mechanisms for strategic unit targeting and battlefield assessment, (2) a retrieval-augmented generation system that leverages domain-specific StarCraft II knowledge to inform tactical decisions, and (3) a dynamic role-based task distribution system that enables coordinated multi-agent behavior. Our experimental evaluation across 21 custom scenarios demonstrates that VLM-based agents powered by foundation models (specifically Qwen-VL and GPT-4o) can execute complex tactical maneuvers without explicit training, achieving comparable performance to traditional MARL methods that require substantial training iterations. This work establishes a foundation for developing human-aligned StarCraft II agents and advances the broader research agenda of multimodal game AI. Our implementation is available at https://github.com/camel-ai/VLM-Play-StarCraft2.
ScoreFlow: Mastering LLM Agent Workflows via Score-based Preference Optimization
Feb 06, 2025Recent research has leveraged large language model multi-agent systems for complex problem-solving while trying to reduce the manual effort required to build them, driving the development of automated agent workflow optimization methods. However, existing methods remain inflexible due to representational limitations, a lack of adaptability, and poor scalability when relying on discrete optimization techniques. We address these challenges with ScoreFlow, a simple yet high-performance framework that leverages efficient gradient-based optimization in a continuous space. ScoreFlow incorporates Score-DPO, a novel variant of the direct preference optimization method that accounts for quantitative feedback. Across six benchmarks spanning question answering, coding, and mathematical reasoning, ScoreFlow achieves an 8.2% improvement over existing baselines. Moreover, it empowers smaller models to outperform larger ones with lower inference costs. Project: https://github.com/Gen-Verse/ScoreFlow
Vision-Language Models Do Not Understand Negation
Jan 16, 2025



Many practical vision-language applications require models that understand negation, e.g., when using natural language to retrieve images which contain certain objects but not others. Despite advancements in vision-language models (VLMs) through large-scale training, their ability to comprehend negation remains underexplored. This study addresses the question: how well do current VLMs understand negation? We introduce NegBench, a new benchmark designed to evaluate negation understanding across 18 task variations and 79k examples spanning image, video, and medical datasets. The benchmark consists of two core tasks designed to evaluate negation understanding in diverse multimodal settings: Retrieval with Negation and Multiple Choice Questions with Negated Captions. Our evaluation reveals that modern VLMs struggle significantly with negation, often performing at chance level. To address these shortcomings, we explore a data-centric approach wherein we finetune CLIP models on large-scale synthetic datasets containing millions of negated captions. We show that this approach can result in a 10% increase in recall on negated queries and a 40% boost in accuracy on multiple-choice questions with negated captions.
OS-Genesis: Automating GUI Agent Trajectory Construction via Reverse Task Synthesis
Dec 27, 2024



Graphical User Interface (GUI) agents powered by Vision-Language Models (VLMs) have demonstrated human-like computer control capability. Despite their utility in advancing digital automation, a critical bottleneck persists: collecting high-quality trajectory data for training. Common practices for collecting such data rely on human supervision or synthetic data generation through executing pre-defined tasks, which are either resource-intensive or unable to guarantee data quality. Moreover, these methods suffer from limited data diversity and significant gaps between synthetic data and real-world environments. To address these challenges, we propose OS-Genesis, a novel GUI data synthesis pipeline that reverses the conventional trajectory collection process. Instead of relying on pre-defined tasks, OS-Genesis enables agents first to perceive environments and perform step-wise interactions, then retrospectively derive high-quality tasks to enable trajectory-level exploration. A trajectory reward model is then employed to ensure the quality of the generated trajectories. We demonstrate that training GUI agents with OS-Genesis significantly improves their performance on highly challenging online benchmarks. In-depth analysis further validates OS-Genesis's efficiency and its superior data quality and diversity compared to existing synthesis methods. Our codes, data, and checkpoints are available at \href{https://qiushisun.github.io/OS-Genesis-Home/}{OS-Genesis Homepage}.
Generating Editable Head Avatars with 3D Gaussian GANs
Dec 26, 2024



Generating animatable and editable 3D head avatars is essential for various applications in computer vision and graphics. Traditional 3D-aware generative adversarial networks (GANs), often using implicit fields like Neural Radiance Fields (NeRF), achieve photorealistic and view-consistent 3D head synthesis. However, these methods face limitations in deformation flexibility and editability, hindering the creation of lifelike and easily modifiable 3D heads. We propose a novel approach that enhances the editability and animation control of 3D head avatars by incorporating 3D Gaussian Splatting (3DGS) as an explicit 3D representation. This method enables easier illumination control and improved editability. Central to our approach is the Editable Gaussian Head (EG-Head) model, which combines a 3D Morphable Model (3DMM) with texture maps, allowing precise expression control and flexible texture editing for accurate animation while preserving identity. To capture complex non-facial geometries like hair, we use an auxiliary set of 3DGS and tri-plane features. Extensive experiments demonstrate that our approach delivers high-quality 3D-aware synthesis with state-of-the-art controllability. Our code and models are available at https://github.com/liguohao96/EGG3D.
OASIS: Open Agent Social Interaction Simulations with One Million Agents
Nov 26, 2024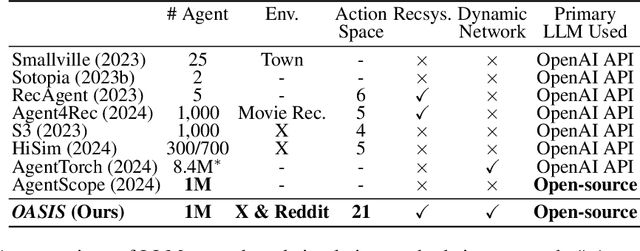
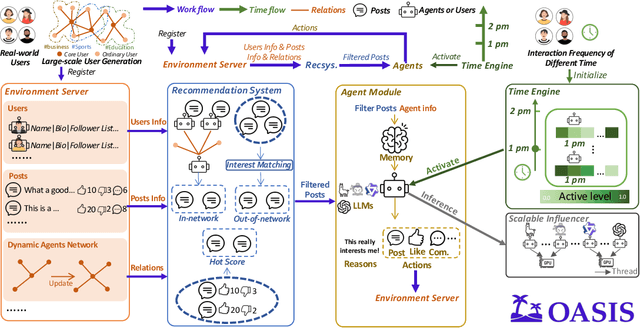

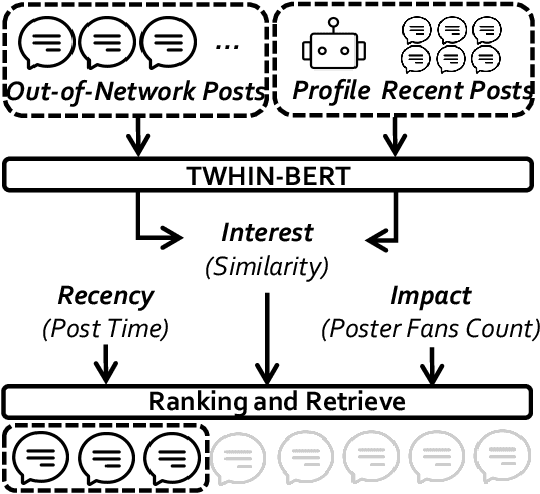
There has been a growing interest in enhancing rule-based agent-based models (ABMs) for social media platforms (i.e., X, Reddit) with more realistic large language model (LLM) agents, thereby allowing for a more nuanced study of complex systems. As a result, several LLM-based ABMs have been proposed in the past year. While they hold promise, each simulator is specifically designed to study a particular scenario, making it time-consuming and resource-intensive to explore other phenomena using the same ABM. Additionally, these models simulate only a limited number of agents, whereas real-world social media platforms involve millions of users. To this end, we propose OASIS, a generalizable and scalable social media simulator. OASIS is designed based on real-world social media platforms, incorporating dynamically updated environments (i.e., dynamic social networks and post information), diverse action spaces (i.e., following, commenting), and recommendation systems (i.e., interest-based and hot-score-based). Additionally, OASIS supports large-scale user simulations, capable of modeling up to one million users. With these features, OASIS can be easily extended to different social media platforms to study large-scale group phenomena and behaviors. We replicate various social phenomena, including information spreading, group polarization, and herd effects across X and Reddit platforms. Moreover, we provide observations of social phenomena at different agent group scales. We observe that the larger agent group scale leads to more enhanced group dynamics and more diverse and helpful agents' opinions. These findings demonstrate OASIS's potential as a powerful tool for studying complex systems in digital environments.
OASIS: Open Agents Social Interaction Simulations on One Million Agents
Nov 21, 2024There has been a growing interest in enhancing rule-based agent-based models (ABMs) for social media platforms (i.e., X, Reddit) with more realistic large language model (LLM) agents, thereby allowing for a more nuanced study of complex systems. As a result, several LLM-based ABMs have been proposed in the past year. While they hold promise, each simulator is specifically designed to study a particular scenario, making it time-consuming and resource-intensive to explore other phenomena using the same ABM. Additionally, these models simulate only a limited number of agents, whereas real-world social media platforms involve millions of users. To this end, we propose OASIS, a generalizable and scalable social media simulator. OASIS is designed based on real-world social media platforms, incorporating dynamically updated environments (i.e., dynamic social networks and post information), diverse action spaces (i.e., following, commenting), and recommendation systems (i.e., interest-based and hot-score-based). Additionally, OASIS supports large-scale user simulations, capable of modeling up to one million users. With these features, OASIS can be easily extended to different social media platforms to study large-scale group phenomena and behaviors. We replicate various social phenomena, including information spreading, group polarization, and herd effects across X and Reddit platforms. Moreover, we provide observations of social phenomena at different agent group scales. We observe that the larger agent group scale leads to more enhanced group dynamics and more diverse and helpful agents' opinions. These findings demonstrate OASIS's potential as a powerful tool for studying complex systems in digital environments.