 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Role-Playing Agents Practice What They Preach? Belief-Behavior Consistency in LLM-Based Simulations of Human Trust
Jul 02, 2025As LLMs are increasingly studied as role-playing agents to generate synthetic data for human behavioral research, ensuring that their outputs remain coherent with their assigned roles has become a critical concern. In this paper, we investigate how consistently LLM-based role-playing agents' stated beliefs about the behavior of the people they are asked to role-play ("what they say") correspond to their actual behavior during role-play ("how they act"). Specifically, we establish an evaluation framework to rigorously measure how well beliefs obtained by prompting the model can predict simulation outcomes in advance. Using an augmented version of the GenAgents persona bank and the Trust Game (a standard economic game used to quantify players' trust and reciprocity), we introduce a belief-behavior consistency metric to systematically investigate how it is affected by factors such as: (1) the types of beliefs we elicit from LLMs, like expected outcomes of simulations versus task-relevant attributes of individual characters LLMs are asked to simulate; (2) when and how we present LLMs with relevant information about Trust Game; and (3) how far into the future we ask the model to forecast its actions. We also explore how feasible it is to impose a researcher's own theoretical priors in the event that the originally elicited beliefs are misaligned with research objectives. Our results reveal systematic inconsistencies between LLMs' stated (or imposed) beliefs and the outcomes of their role-playing simulation, at both an individual- and population-level. Specifically, we find that, even when models appear to encode plausible beliefs, they may fail to apply them in a consistent way. These findings highlight the need to identify how and when LLMs' stated beliefs align with their simulated behavior, allowing researchers to use LLM-based agents appropriately in behavioral studies.
Can LLMs Reliably Simulate Human Learner Actions? A Simulation Authoring Framework for Open-Ended Learning Environments
Oct 03, 2024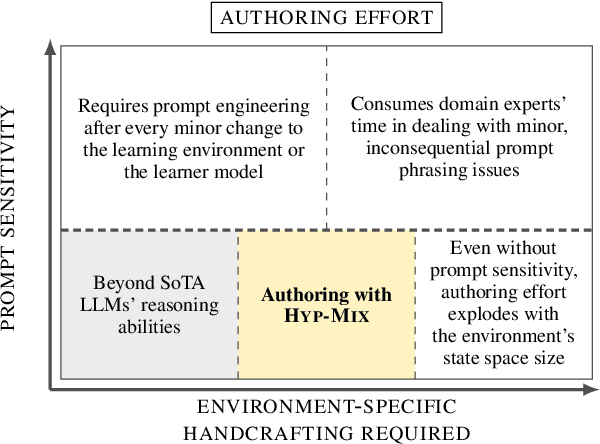

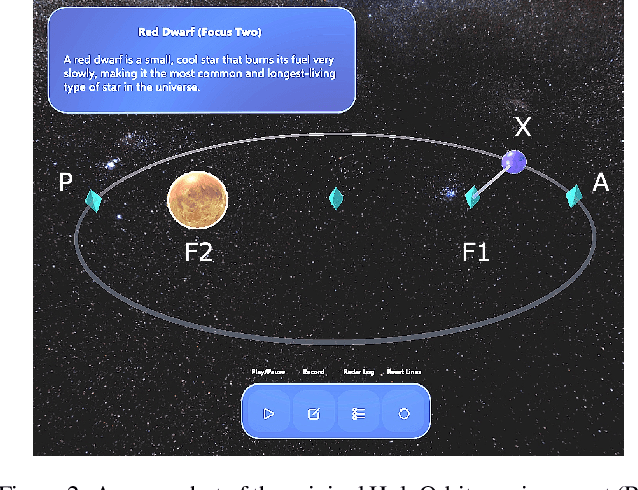
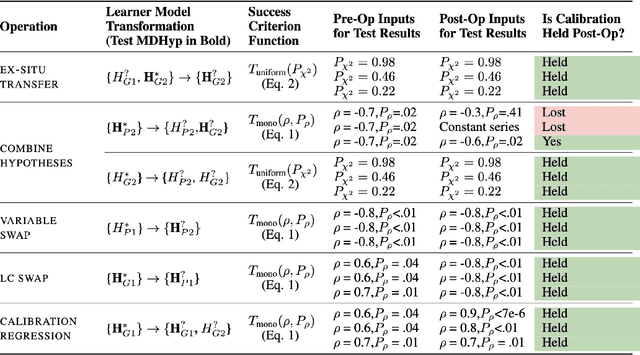
Simulating learner actions helps stress-test open-ended interactive learning environments and prototype new adaptations before deployment. While recent studies show the promise of using large language models (LLMs) for simulating human behavior, such approaches have not gone beyond rudimentary proof-of-concept stages due to key limitations. First, LLMs are highly sensitive to minor prompt variations, raising doubts about their ability to generalize to new scenarios without extensive prompt engineering. Moreover, apparently successful outcomes can often be unreliable, either because domain experts unintentionally guide LLMs to produce expected results, leading to self-fulfilling prophecies; or because the LLM has encountered highly similar scenarios in its training data, meaning that models may not be simulating behavior so much as regurgitating memorized content. To address these challenges, we propose Hyp-Mix, a simulation authoring framework that allows experts to develop and evaluate simulations by combining testable hypotheses about learner behavior. Testing this framework in a physics learning environment, we found that GPT-4 Turbo maintains calibrated behavior even as the underlying learner model changes, providing the first evidence that LLMs can be used to simulate realistic behaviors in open-ended interactive learning environments, a necessary prerequisite for useful LLM behavioral simulation.
Making Task-Oriented Dialogue Datasets More Natural by Synthetically Generating Indirect User Requests
Jun 16, 2024
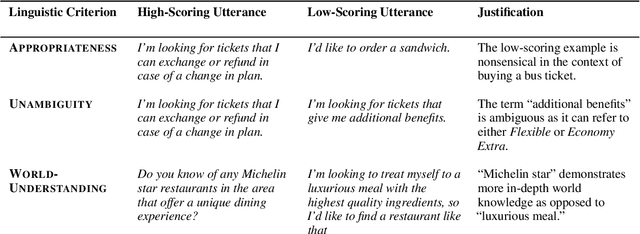
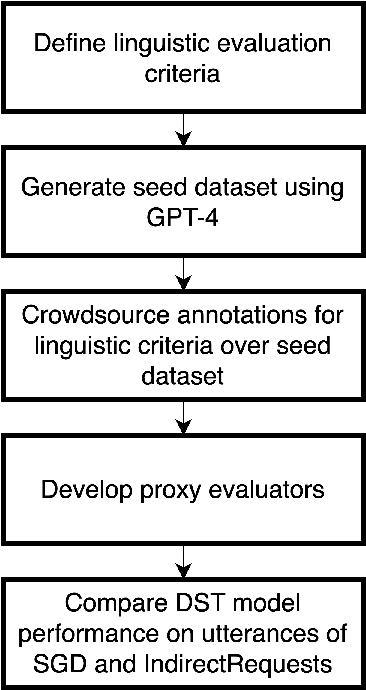

Indirect User Requests (IURs), such as "It's cold in here" instead of "Could you please increase the temperature?" are common in human-human task-oriented dialogue and require world knowledge and pragmatic reasoning from the listener. While large language models (LLMs) can handle these requests effectively, smaller models deployed on virtual assistants often struggle due to resource constraints. Moreover, existing task-oriented dialogue benchmarks lack sufficient examples of complex discourse phenomena such as indirectness. To address this, we propose a set of linguistic criteria along with an LLM-based pipeline for generating realistic IURs to test natural language understanding (NLU) and dialogue state tracking (DST) models before deployment in a new domain. We also release IndirectRequests, a dataset of IURs based on the Schema Guided Dialog (SGD) corpus, as a comparative testbed for evaluating the performance of smaller models in handling indirect requests.
IndirectRequests: Making Task-Oriented Dialogue Datasets More Natural by Synthetically Generating Indirect User Requests
Jun 12, 2024Existing benchmark corpora of task-oriented dialogue are collected either using a "machines talking to machines" approach or by giving template-based goal descriptions to crowdworkers. These methods, however, often produce utterances that are markedly different from natural human conversations in which people often convey their preferences in indirect ways, such as through small talk. We term such utterances as Indirect User Requests (IURs). Understanding such utterances demands considerable world knowledge and reasoning capabilities on the listener's part. Our study introduces an LLM-based pipeline to automatically generate realistic, high-quality IURs for a given domain, with the ultimate goal of supporting research in natural language understanding (NLU) and dialogue state tracking (DST) for task-oriented dialogue systems. Our findings show that while large LLMs such as GPT-3.5 and GPT-4 generate high-quality IURs, achieving similar quality with smaller models is more challenging. We release IndirectRequests, a dataset of IURs that advances beyond the initial Schema-Guided Dialog (SGD) dataset in that it provides a challenging testbed for testing the "in the wild" performance of NLU and DST models.
Can Similarity-Based Domain-Ordering Reduce Catastrophic Forgetting for Intent Recognition?
Feb 21, 2024Task-oriented dialogue systems are expected to handle a constantly expanding set of intents and domains even after they have been deployed to support more and more functionalities. To live up to this expectation, it becomes critical to mitigate the catastrophic forgetting problem (CF) that occurs in continual learning (CL) settings for a task such as intent recognition. While existing dialogue systems research has explored replay-based and regularization-based methods to this end, the effect of domain ordering on the CL performance of intent recognition models remains unexplored. If understood well, domain ordering has the potential to be an orthogonal technique that can be leveraged alongside existing techniques such as experience replay. Our work fills this gap by comparing the impact of three domain-ordering strategies (min-sum path, max-sum path, random) on the CL performance of a generative intent recognition model. Our findings reveal that the min-sum path strategy outperforms the others in reducing catastrophic forgetting when training on the 220M T5-Base model. However, this advantage diminishes with the larger 770M T5-Large model. These results underscores the potential of domain ordering as a complementary strategy for mitigating catastrophic forgetting in continually learning intent recognition models, particularly in resource-constrained scenarios.
A Review of Digital Learning Environments for Teaching Natural Language Processing in K-12 Education
Oct 02, 2023Natural Language Processing (NLP) plays a significant role in our daily lives and has become an essential part of Artificial Intelligence (AI) education in K-12. As children grow up with NLP-powered applications, it is crucial to introduce NLP concepts to them, fostering their understanding of language processing, language generation, and ethical implications of AI and NLP. This paper presents a comprehensive review of digital learning environments for teaching NLP in K-12. Specifically, it explores existing digital learning tools, discusses how they support specific NLP tasks and procedures, and investigates their explainability and evaluation results in educational contexts. By examining the strengths and limitations of these tools, this literature review sheds light on the current state of NLP learning tools in K-12 education. It aims to guide future research efforts to refine existing tools, develop new ones, and explore more effective and inclusive strategies for integrating NLP into K-12 educational contexts.
Agreement Tracking for Multi-Issue Negotiation Dialogues
Jul 13, 2023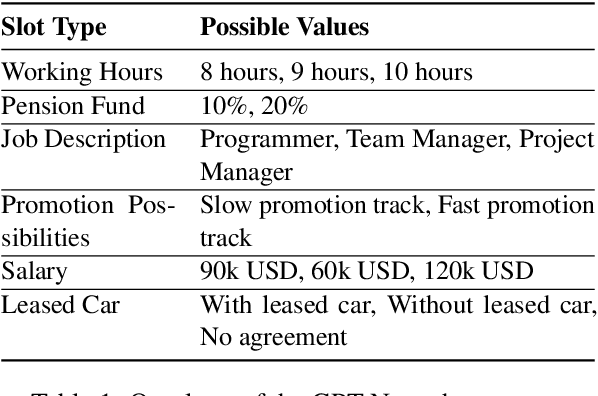


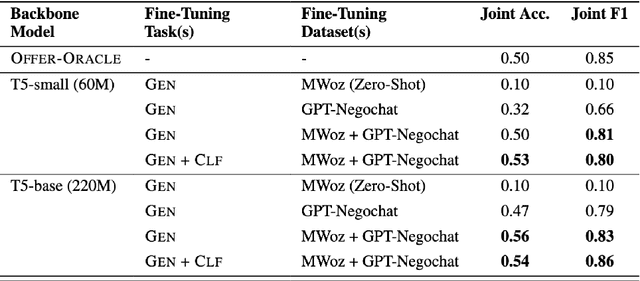
Automated negotiation support systems aim to help human negotiators reach more favorable outcomes in multi-issue negotiations (e.g., an employer and a candidate negotiating over issues such as salary, hours, and promotions before a job offer). To be successful, these systems must accurately track agreements reached by participants in real-time. Existing approaches either focus on task-oriented dialogues or produce unstructured outputs, rendering them unsuitable for this objective. Our work introduces the novel task of agreement tracking for two-party multi-issue negotiations, which requires continuous monitoring of agreements within a structured state space. To address the scarcity of annotated corpora with realistic multi-issue negotiation dialogues, we use GPT-3 to build GPT-Negochat, a synthesized dataset that we make publicly available. We present a strong initial baseline for our task by transfer-learning a T5 model trained on the MultiWOZ 2.4 corpus. Pre-training T5-small and T5-base on MultiWOZ 2.4's DST task enhances results by 21% and 9% respectively over training solely on GPT-Negochat. We validate our method's sample-efficiency via smaller training subset experiments. By releasing GPT-Negochat and our baseline models, we aim to encourage further research in multi-issue negotiation dialogue agreement tracking.