 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Role-Playing Agents Practice What They Preach? Belief-Behavior Consistency in LLM-Based Simulations of Human Trust
Jul 02, 2025As LLMs are increasingly studied as role-playing agents to generate synthetic data for human behavioral research, ensuring that their outputs remain coherent with their assigned roles has become a critical concern. In this paper, we investigate how consistently LLM-based role-playing agents' stated beliefs about the behavior of the people they are asked to role-play ("what they say") correspond to their actual behavior during role-play ("how they act"). Specifically, we establish an evaluation framework to rigorously measure how well beliefs obtained by prompting the model can predict simulation outcomes in advance. Using an augmented version of the GenAgents persona bank and the Trust Game (a standard economic game used to quantify players' trust and reciprocity), we introduce a belief-behavior consistency metric to systematically investigate how it is affected by factors such as: (1) the types of beliefs we elicit from LLMs, like expected outcomes of simulations versus task-relevant attributes of individual characters LLMs are asked to simulate; (2) when and how we present LLMs with relevant information about Trust Game; and (3) how far into the future we ask the model to forecast its actions. We also explore how feasible it is to impose a researcher's own theoretical priors in the event that the originally elicited beliefs are misaligned with research objectives. Our results reveal systematic inconsistencies between LLMs' stated (or imposed) beliefs and the outcomes of their role-playing simulation, at both an individual- and population-level. Specifically, we find that, even when models appear to encode plausible beliefs, they may fail to apply them in a consistent way. These findings highlight the need to identify how and when LLMs' stated beliefs align with their simulated behavior, allowing researchers to use LLM-based agents appropriately in behavioral studies.
Evaluating and Designing Sparse Autoencoders by Approximating Quasi-Orthogonality
Mar 31, 2025



Sparse autoencoders (SAEs) have emerged as a workhorse of modern mechanistic interpretability, but leading SAE approaches with top-$k$ style activation functions lack theoretical grounding for selecting the hyperparameter $k$. SAEs are based on the linear representation hypothesis (LRH), which assumes that the representations of large language models (LLMs) are linearly encoded, and the superposition hypothesis (SH), which states that there can be more features in the model than its dimensionality. We show that, based on the formal definitions of the LRH and SH, the magnitude of sparse feature vectors (the latent representations learned by SAEs of the dense embeddings of LLMs) can be approximated using their corresponding dense vector with a closed-form error bound. To visualize this, we propose the ZF plot, which reveals a previously unknown relationship between LLM hidden embeddings and SAE feature vectors, allowing us to make the first empirical measurement of the extent to which feature vectors of pre-trained SAEs are over- or under-activated for a given input. Correspondingly, we introduce Approximate Feature Activation (AFA), which approximates the magnitude of the ground-truth sparse feature vector, and propose a new evaluation metric derived from AFA to assess the alignment between inputs and activations. We also leverage AFA to introduce a novel SAE architecture, the top-AFA SAE, leading to SAEs that: (a) are more in line with theoretical justifications; and (b) obviate the need to tune SAE sparsity hyperparameters. Finally, we empirically demonstrate that top-AFA SAEs achieve reconstruction loss comparable to that of state-of-the-art top-k SAEs, without requiring the hyperparameter $k$ to be tuned. Our code is available at: https://github.com/SewoongLee/top-afa-sae.
Social Science Is Necessary for Operationalizing Socially Responsible Foundation Models
Dec 20, 2024With the rise of foundation models, there is growing concern about their potential social impacts. Social science has a long history of studying the social impacts of transformative technologies in terms of pre-existing systems of power and how these systems are disrupted or reinforced by new technologies. In this position paper, we build on prior work studying the social impacts of earlier technologies to propose a conceptual framework studying foundation models as sociotechnical systems, incorporating social science expertise to better understand how these models affect systems of power, anticipate the impacts of deploying these models in various applications, and study the effectiveness of technical interventions intended to mitigate social harms. We advocate for an interdisciplinary and collaborative research paradigm between AI and social science across all stages of foundation model research and development to promote socially responsible research practices and use cases, and outline several strategies to facilitate such research.
Hidden in Plain Sight: Evaluating Abstract Shape Recognition in Vision-Language Models
Nov 09, 2024Despite the importance of shape perception in human vision, early neural image classifiers relied less on shape information for object recognition than other (often spurious) features. While recent research suggests that current large Vision-Language Models (VLMs) exhibit more reliance on shape, we find them to still be seriously limited in this regard. To quantify such limitations, we introduce IllusionBench, a dataset that challenges current cutting-edge VLMs to decipher shape information when the shape is represented by an arrangement of visual elements in a scene. Our extensive evaluations reveal that, while these shapes are easily detectable by human annotators, current VLMs struggle to recognize them, indicating important avenues for future work in developing more robust visual perception systems. The full dataset and codebase are available at: \url{https://arshiahemmat.github.io/illusionbench/}
Focus On This, Not That! Steering LLMs With Adaptive Feature Specification
Oct 30, 2024Despite the success of Instruction Tuning (IT) in training large language models (LLMs) to perform arbitrary user-specified tasks, these models often still leverage spurious or biased features learned from their training data, leading to undesired behaviours when deploying them in new contexts. In this work, we introduce Focus Instruction Tuning (FIT), which trains LLMs to condition their responses by focusing on specific features whilst ignoring others, leading to different behaviours based on what features are specified. Across several experimental settings, we show that focus-tuned models can be adaptively steered by focusing on different features at inference-time: for instance, robustness can be improved by focusing on task-causal features and ignoring spurious features, and social bias can be mitigated by ignoring demographic categories. Furthermore, FIT can steer behaviour in new contexts, generalising under distribution shift and to new unseen features at inference time, and thereby facilitating more robust, fair, and controllable LLM applications in real-world environments.
Can LLMs Reliably Simulate Human Learner Actions? A Simulation Authoring Framework for Open-Ended Learning Environments
Oct 03, 2024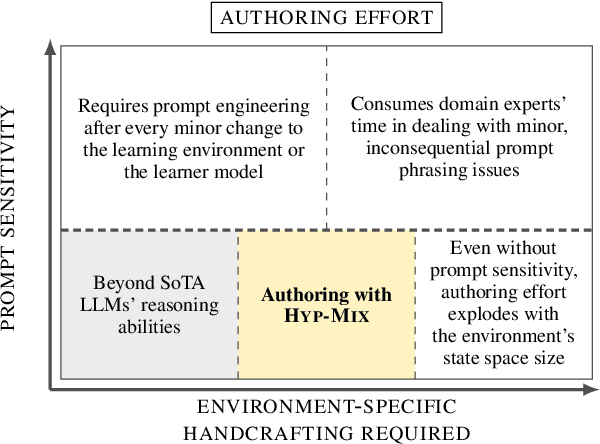

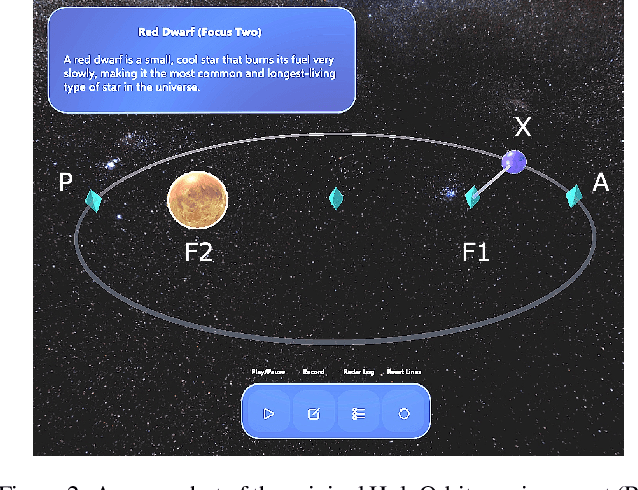
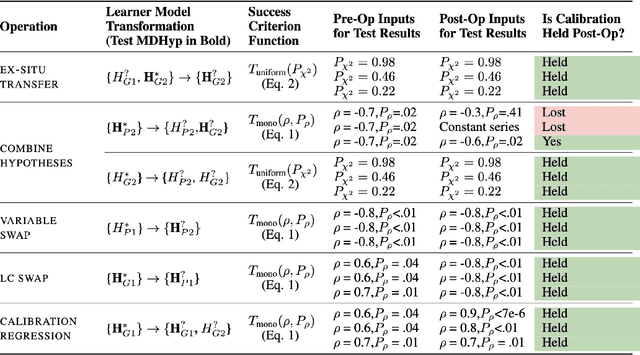
Simulating learner actions helps stress-test open-ended interactive learning environments and prototype new adaptations before deployment. While recent studies show the promise of using large language models (LLMs) for simulating human behavior, such approaches have not gone beyond rudimentary proof-of-concept stages due to key limitations. First, LLMs are highly sensitive to minor prompt variations, raising doubts about their ability to generalize to new scenarios without extensive prompt engineering. Moreover, apparently successful outcomes can often be unreliable, either because domain experts unintentionally guide LLMs to produce expected results, leading to self-fulfilling prophecies; or because the LLM has encountered highly similar scenarios in its training data, meaning that models may not be simulating behavior so much as regurgitating memorized content. To address these challenges, we propose Hyp-Mix, a simulation authoring framework that allows experts to develop and evaluate simulations by combining testable hypotheses about learner behavior. Testing this framework in a physics learning environment, we found that GPT-4 Turbo maintains calibrated behavior even as the underlying learner model changes, providing the first evidence that LLMs can be used to simulate realistic behaviors in open-ended interactive learning environments, a necessary prerequisite for useful LLM behavioral simulation.
Measuring the Reliability of Causal Probing Methods: Tradeoffs, Limitations, and the Plight of Nullifying Interventions
Aug 28, 2024



Causal probing is an approach to interpreting foundation models, such as large language models, by training probes to recognize latent properties of interest from embeddings, intervening on probes to modify this representation, and analyzing the resulting changes in the model's behavior. While some recent works have cast doubt on the theoretical basis of several leading causal probing intervention methods, it has been unclear how to systematically and empirically evaluate their effectiveness in practice. To address this problem, we propose a general empirical analysis framework to evaluate the reliability of causal probing interventions, formally defining and quantifying two key causal probing desiderata: completeness (fully transforming the representation of the target property) and selectivity (minimally impacting other properties). Our formalism allows us to make the first direct comparisons between different families of causal probing methods (e.g., linear vs. nonlinear or counterfactual vs. nullifying interventions). We conduct extensive experiments across several leading methods, finding that (1) there is an inherent tradeoff between these criteria, and no method is able to consistently satisfy both at once; and (2) across the board, nullifying interventions are always far less complete than counterfactual interventions, indicating that nullifying methods may not be an effective approach to causal probing.
The Cognitive Revolution in Interpretability: From Explaining Behavior to Interpreting Representations and Algorithms
Aug 11, 2024Artificial neural networks have long been understood as "black boxes": though we know their computation graphs and learned parameters, the knowledge encoded by these weights and functions they perform are not inherently interpretable. As such, from the early days of deep learning, there have been efforts to explain these models' behavior and understand them internally; and recently, mechanistic interpretability (MI) has emerged as a distinct research area studying the features and implicit algorithms learned by foundation models such as large language models. In this work, we aim to ground MI in the context of cognitive science, which has long struggled with analogous questions in studying and explaining the behavior of "black box" intelligent systems like the human brain. We leverage several important ideas and developments in the history of cognitive science to disentangle divergent objectives in MI and indicate a clear path forward. First, we argue that current methods are ripe to facilitate a transition in deep learning interpretation echoing the "cognitive revolution" in 20th-century psychology that shifted the study of human psychology from pure behaviorism toward mental representations and processing. Second, we propose a taxonomy mirroring key parallels in computational neuroscience to describe two broad categories of MI research, semantic interpretation (what latent representations are learned and used) and algorithmic interpretation (what operations are performed over representations) to elucidate their divergent goals and objects of study. Finally, we elaborate the parallels and distinctions between various approaches in both categories, analyze the respective strengths and weaknesses of representative works, clarify underlying assumptions, outline key challenges, and discuss the possibility of unifying these modes of interpretation under a common framework.
Competence-Based Analysis of Language Models
Mar 01, 2023



Despite the recent success of large pretrained language models (LMs) on a variety of prompting tasks, these models can be alarmingly brittle to small changes in inputs or application contexts. To better understand such behavior and motivate the design of more robust LMs, we propose a general experimental framework, CALM (Competence-based Analysis of Language Models), where targeted causal interventions are utilized to damage an LM's internal representation of various linguistic properties in order to evaluate its use of each representation in performing a given task. We implement these interventions as gradient-based adversarial attacks, which (in contrast to prior causal probing methodologies) are able to target arbitrarily-encoded representations of relational properties, and carry out a case study of this approach to analyze how BERT-like LMs use representations of several relational properties in performing associated relation prompting tasks. We find that, while the representations LMs leverage in performing each task are highly entangled, they may be meaningfully interpreted in terms of the tasks where they are most utilized; and more broadly, that CALM enables an expanded scope of inquiry in LM analysis that may be useful in predicting and explaining weaknesses of existing LMs.
Not Just Pretty Pictures: Text-to-Image Generators Enable Interpretable Interventions for Robust Representations
Dec 21, 2022



Neural image classifiers are known to undergo severe performance degradation when exposed to input that exhibits covariate-shift with respect to the training distribution. Successful hand-crafted augmentation pipelines aim at either approximating the expected test domain conditions or to perturb the features that are specific to the training environment. The development of effective pipelines is typically cumbersome, and produce transformations whose impact on the classifier performance are hard to understand and control. In this paper, we show that recent Text-to-Image (T2I) generators' ability to simulate image interventions via natural-language prompts can be leveraged to train more robust models, offering a more interpretable and controllable alternative to traditional augmentation methods. We find that a variety of prompting mechanisms are effective for producing synthetic training data sufficient to achieve state-of-the-art performance in widely-adopted domain-generalization benchmarks and reduce classifiers' dependency on spurious features. Our work suggests that further progress in T2I generation and a tighter integration with other research fields may represent a significant step towards the development of more robust machine learning systems.