 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHidden in Plain Sight: Evaluating Abstract Shape Recognition in Vision-Language Models
Nov 09, 2024Despite the importance of shape perception in human vision, early neural image classifiers relied less on shape information for object recognition than other (often spurious) features. While recent research suggests that current large Vision-Language Models (VLMs) exhibit more reliance on shape, we find them to still be seriously limited in this regard. To quantify such limitations, we introduce IllusionBench, a dataset that challenges current cutting-edge VLMs to decipher shape information when the shape is represented by an arrangement of visual elements in a scene. Our extensive evaluations reveal that, while these shapes are easily detectable by human annotators, current VLMs struggle to recognize them, indicating important avenues for future work in developing more robust visual perception systems. The full dataset and codebase are available at: \url{https://arshiahemmat.github.io/illusionbench/}
Focus On This, Not That! Steering LLMs With Adaptive Feature Specification
Oct 30, 2024Despite the success of Instruction Tuning (IT) in training large language models (LLMs) to perform arbitrary user-specified tasks, these models often still leverage spurious or biased features learned from their training data, leading to undesired behaviours when deploying them in new contexts. In this work, we introduce Focus Instruction Tuning (FIT), which trains LLMs to condition their responses by focusing on specific features whilst ignoring others, leading to different behaviours based on what features are specified. Across several experimental settings, we show that focus-tuned models can be adaptively steered by focusing on different features at inference-time: for instance, robustness can be improved by focusing on task-causal features and ignoring spurious features, and social bias can be mitigated by ignoring demographic categories. Furthermore, FIT can steer behaviour in new contexts, generalising under distribution shift and to new unseen features at inference time, and thereby facilitating more robust, fair, and controllable LLM applications in real-world environments.
Universal In-Context Approximation By Prompting Fully Recurrent Models
Jun 03, 2024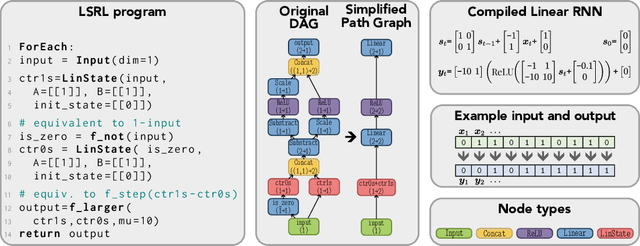
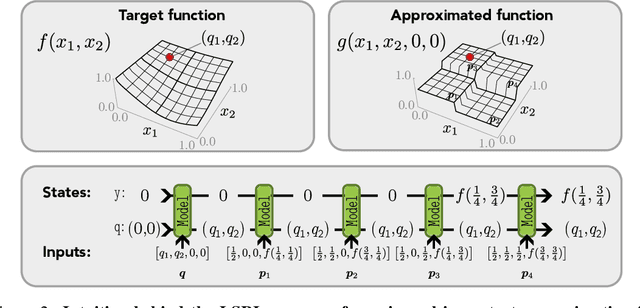

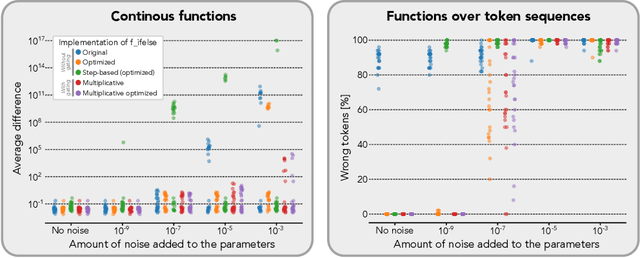
Zero-shot and in-context learning enable solving tasks without model fine-tuning, making them essential for developing generative model solutions. Therefore, it is crucial to understand whether a pretrained model can be prompted to approximate any function, i.e., whether it is a universal in-context approximator. While it was recently shown that transformer models do possess this property, these results rely on their attention mechanism. Hence, these findings do not apply to fully recurrent architectures like RNNs, LSTMs, and the increasingly popular SSMs. We demonstrate that RNNs, LSTMs, GRUs, Linear RNNs, and linear gated architectures such as Mamba and Hawk/Griffin can also serve as universal in-context approximators. To streamline our argument, we introduce a programming language called LSRL that compiles to these fully recurrent architectures. LSRL may be of independent interest for further studies of fully recurrent models, such as constructing interpretability benchmarks. We also study the role of multiplicative gating and observe that architectures incorporating such gating (e.g., LSTMs, GRUs, Hawk/Griffin) can implement certain operations more stably, making them more viable candidates for practical in-context universal approximation.
Faithful Knowledge Distillation
Jun 08, 2023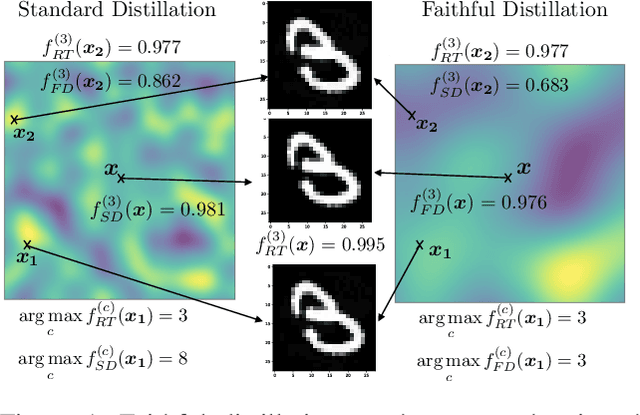
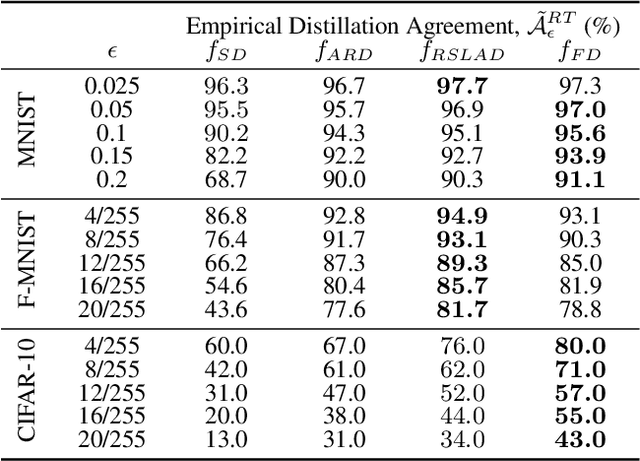


Knowledge distillation (KD) has received much attention due to its success in compressing networks to allow for their deployment in resource-constrained systems. While the problem of adversarial robustness has been studied before in the KD setting, previous works overlook what we term the relative calibration of the student network with respect to its teacher in terms of soft confidences. In particular, we focus on two crucial questions with regard to a teacher-student pair: (i) do the teacher and student disagree at points close to correctly classified dataset examples, and (ii) is the distilled student as confident as the teacher around dataset examples? These are critical questions when considering the deployment of a smaller student network trained from a robust teacher within a safety-critical setting. To address these questions, we introduce a faithful imitation framework to discuss the relative calibration of confidences, as well as provide empirical and certified methods to evaluate the relative calibration of a student w.r.t. its teacher. Further, to verifiably align the relative calibration incentives of the student to those of its teacher, we introduce faithful distillation. Our experiments on the MNIST and Fashion-MNIST datasets demonstrate the need for such an analysis and the advantages of the increased verifiability of faithful distillation over alternative adversarial distillation methods.