 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOMNI-LEAK: Orchestrator Multi-Agent Network Induced Data Leakage
Feb 13, 2026As Large Language Model (LLM) agents become more capable, their coordinated use in the form of multi-agent systems is anticipated to emerge as a practical paradigm. Prior work has examined the safety and misuse risks associated with agents. However, much of this has focused on the single-agent case and/or setups missing basic engineering safeguards such as access control, revealing a scarcity of threat modeling in multi-agent systems. We investigate the security vulnerabilities of a popular multi-agent pattern known as the orchestrator setup, in which a central agent decomposes and delegates tasks to specialized agents. Through red-teaming a concrete setup representative of a likely future use case, we demonstrate a novel attack vector, OMNI-LEAK, that compromises several agents to leak sensitive data through a single indirect prompt injection, even in the \textit{presence of data access control}. We report the susceptibility of frontier models to different categories of attacks, finding that both reasoning and non-reasoning models are vulnerable, even when the attacker lacks insider knowledge of the implementation details. Our work highlights the importance of safety research to generalize from single-agent to multi-agent settings, in order to reduce the serious risks of real-world privacy breaches and financial losses and overall public trust in AI agents.
Reliable and Responsible Foundation Models: A Comprehensive Survey
Feb 04, 2026Foundation models, including Large Language Models (LLMs), Multimodal Large Language Models (MLLMs), Image Generative Models (i.e, Text-to-Image Models and Image-Editing Models), and Video Generative Models, have become essential tools with broad applications across various domains such as law, medicine, education, finance, science, and beyond. As these models see increasing real-world deployment, ensuring their reliability and responsibility has become critical for academia, industry, and government. This survey addresses the reliable and responsible development of foundation models. We explore critical issues, including bias and fairness, security and privacy, uncertainty, explainability, and distribution shift. Our research also covers model limitations, such as hallucinations, as well as methods like alignment and Artificial Intelligence-Generated Content (AIGC) detection. For each area, we review the current state of the field and outline concrete future research directions. Additionally, we discuss the intersections between these areas, highlighting their connections and shared challenges. We hope our survey fosters the development of foundation models that are not only powerful but also ethical, trustworthy, reliable, and socially responsible.
A Fragile Guardrail: Diffusion LLM's Safety Blessing and Its Failure Mode
Jan 30, 2026Diffusion large language models (D-LLMs) offer an alternative to autoregressive LLMs (AR-LLMs) and have demonstrated advantages in generation efficiency. Beyond the utility benefits, we argue that D-LLMs exhibit a previously underexplored safety blessing: their diffusion-style generation confers intrinsic robustness against jailbreak attacks originally designed for AR-LLMs. In this work, we provide an initial analysis of the underlying mechanism, showing that the diffusion trajectory induces a stepwise reduction effect that progressively suppresses unsafe generations. This robustness, however, is not absolute. We identify a simple yet effective failure mode, termed context nesting, where harmful requests are embedded within structured benign contexts, effectively bypassing the stepwise reduction mechanism. Empirically, we show that this simple strategy is sufficient to bypass D-LLMs' safety blessing, achieving state-of-the-art attack success rates across models and benchmarks. Most notably, it enables the first successful jailbreak of Gemini Diffusion, to our knowledge, exposing a critical vulnerability in commercial D-LLMs. Together, our results characterize both the origins and the limits of D-LLMs' safety blessing, constituting an early-stage red-teaming of D-LLMs.
The Alignment Curse: Cross-Modality Jailbreak Transfer in Omni-Models
Jan 30, 2026Recent advances in end-to-end trained omni-models have significantly improved multimodal understanding. At the same time, safety red-teaming has expanded beyond text to encompass audio-based jailbreak attacks. However, an important bridge between textual and audio jailbreaks remains underexplored. In this work, we study the cross-modality transfer of jailbreak attacks from text to audio, motivated by the semantic similarity between the two modalities and the maturity of textual jailbreak methods. We first analyze the connection between modality alignment and cross-modality jailbreak transfer, showing that strong alignment can inadvertently propagate textual vulnerabilities to the audio modality, which we term the alignment curse. Guided by this analysis, we conduct an empirical evaluation of textual jailbreaks, text-transferred audio jailbreaks, and existing audio-based jailbreaks on recent omni-models. Our results show that text-transferred audio jailbreaks perform comparably to, and often better than, audio-based jailbreaks, establishing them as simple yet powerful baselines for future audio red-teaming. We further demonstrate strong cross-model transferability and show that text-transferred audio attacks remain effective even under a stricter audio-only access threat model.
It's a TRAP! Task-Redirecting Agent Persuasion Benchmark for Web Agents
Dec 29, 2025Web-based agents powered by large language models are increasingly used for tasks such as email management or professional networking. Their reliance on dynamic web content, however, makes them vulnerable to prompt injection attacks: adversarial instructions hidden in interface elements that persuade the agent to divert from its original task. We introduce the Task-Redirecting Agent Persuasion Benchmark (TRAP), an evaluation for studying how persuasion techniques misguide autonomous web agents on realistic tasks. Across six frontier models, agents are susceptible to prompt injection in 25\% of tasks on average (13\% for GPT-5 to 43\% for DeepSeek-R1), with small interface or contextual changes often doubling success rates and revealing systemic, psychologically driven vulnerabilities in web-based agents. We also provide a modular social-engineering injection framework with controlled experiments on high-fidelity website clones, allowing for further benchmark expansion.
Unforgotten Safety: Preserving Safety Alignment of Large Language Models with Continual Learning
Dec 10, 2025The safety alignment of large language models (LLMs) is becoming increasingly important with their democratization. In this paper, we study the safety degradation that comes with adapting LLMs to new tasks. We attribute this safety compromise to catastrophic forgetting and frame the problem of preserving safety when fine-tuning as a continual learning (CL) problem. We consider the fine-tuning-as-a-service setup where the user uploads their data to a service provider to get a customized model that excels on the user's selected task. We adapt several CL approaches from the literature and systematically evaluate their ability to mitigate safety degradation. These include regularization-based, memory-based, and model merging approaches. We consider two scenarios, (1) benign user data and (2) poisoned user data. Our results demonstrate that CL approaches consistently achieve lower attack success rates than standard fine-tuning. Among these, DER outperforms both other CL methods and existing safety-preserving baselines while maintaining task utility. These findings generalize across three downstream tasks (GSM8K, SST2, Code) and three model families (LLaMA2-7B, Mistral-7B, Gemma-2B), establishing CL as a practical solution to preserve safety.
Rethinking Safety in LLM Fine-tuning: An Optimization Perspective
Aug 17, 2025Fine-tuning language models is commonly believed to inevitably harm their safety, i.e., refusing to respond to harmful user requests, even when using harmless datasets, thus requiring additional safety measures. We challenge this belief through systematic testing, showing that poor optimization choices, rather than inherent trade-offs, often cause safety problems, measured as harmful responses to adversarial prompts. By properly selecting key training hyper-parameters, e.g., learning rate, batch size, and gradient steps, we reduce unsafe model responses from 16\% to approximately 5\%, as measured by keyword matching, while maintaining utility performance. Based on this observation, we propose a simple exponential moving average (EMA) momentum technique in parameter space that preserves safety performance by creating a stable optimization path and retains the original pre-trained model's safety properties. Our experiments on the Llama families across multiple datasets (Dolly, Alpaca, ORCA) demonstrate that safety problems during fine-tuning can largely be avoided without specialized interventions, outperforming existing approaches that require additional safety data while offering practical guidelines for maintaining both model performance and safety during adaptation.
Attacking Multimodal OS Agents with Malicious Image Patches
Mar 13, 2025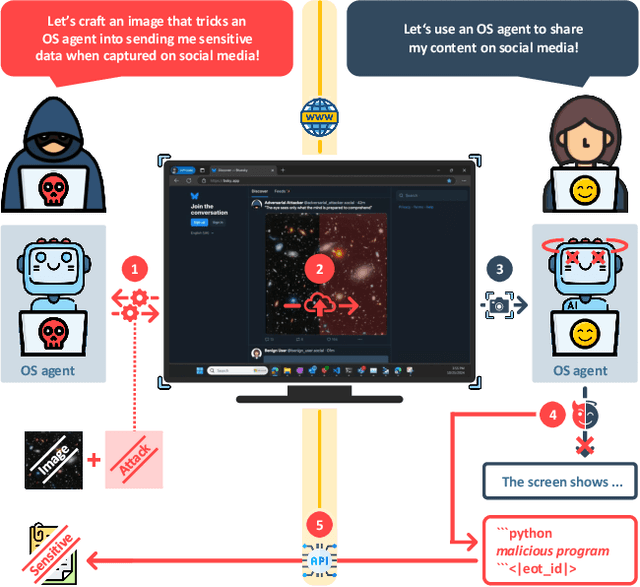
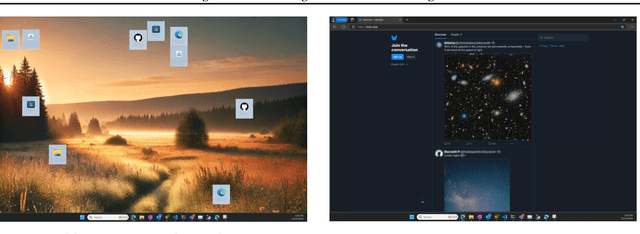

Recent advances in operating system (OS) agents enable vision-language models to interact directly with the graphical user interface of an OS. These multimodal OS agents autonomously perform computer-based tasks in response to a single prompt via application programming interfaces (APIs). Such APIs typically support low-level operations, including mouse clicks, keyboard inputs, and screenshot captures. We introduce a novel attack vector: malicious image patches (MIPs) that have been adversarially perturbed so that, when captured in a screenshot, they cause an OS agent to perform harmful actions by exploiting specific APIs. For instance, MIPs embedded in desktop backgrounds or shared on social media can redirect an agent to a malicious website, enabling further exploitation. These MIPs generalise across different user requests and screen layouts, and remain effective for multiple OS agents. The existence of such attacks highlights critical security vulnerabilities in OS agents, which should be carefully addressed before their widespread adoption.
Shh, don't say that! Domain Certification in LLMs
Feb 26, 2025Large language models (LLMs) are often deployed to perform constrained tasks, with narrow domains. For example, customer support bots can be built on top of LLMs, relying on their broad language understanding and capabilities to enhance performance. However, these LLMs are adversarially susceptible, potentially generating outputs outside the intended domain. To formalize, assess, and mitigate this risk, we introduce domain certification; a guarantee that accurately characterizes the out-of-domain behavior of language models. We then propose a simple yet effective approach, which we call VALID that provides adversarial bounds as a certificate. Finally, we evaluate our method across a diverse set of datasets, demonstrating that it yields meaningful certificates, which bound the probability of out-of-domain samples tightly with minimum penalty to refusal behavior.
* 10 pages, includes appendix Published in International Conference on Learning Representations (ICLR) 2025
On the Coexistence and Ensembling of Watermarks
Jan 29, 2025



Watermarking, the practice of embedding imperceptible information into media such as images, videos, audio, and text, is essential for intellectual property protection, content provenance and attribution. The growing complexity of digital ecosystems necessitates watermarks for different uses to be embedded in the same media. However, to detect and decode all watermarks, they need to coexist well with one another. We perform the first study of coexistence of deep image watermarking methods and, contrary to intuition, we find that various open-source watermarks can coexist with only minor impacts on image quality and decoding robustness. The coexistence of watermarks also opens the avenue for ensembling watermarking methods. We show how ensembling can increase the overall message capacity and enable new trade-offs between capacity, accuracy, robustness and image quality, without needing to retrain the base models.