 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Post-Training: A Deep Dive into Reasoning Large Language Models
Feb 28, 2025Large Language Models (LLMs) have transformed the natural language processing landscape and brought to life diverse applications. Pretraining on vast web-scale data has laid the foundation for these models, yet the research community is now increasingly shifting focus toward post-training techniques to achieve further breakthroughs. While pretraining provides a broad linguistic foundation, post-training methods enable LLMs to refine their knowledge, improve reasoning, enhance factual accuracy, and align more effectively with user intents and ethical considerations. Fine-tuning, reinforcement learning, and test-time scaling have emerged as critical strategies for optimizing LLMs performance, ensuring robustness, and improving adaptability across various real-world tasks. This survey provides a systematic exploration of post-training methodologies, analyzing their role in refining LLMs beyond pretraining, addressing key challenges such as catastrophic forgetting, reward hacking, and inference-time trade-offs. We highlight emerging directions in model alignment, scalable adaptation, and inference-time reasoning, and outline future research directions. We also provide a public repository to continually track developments in this fast-evolving field: https://github.com/mbzuai-oryx/Awesome-LLM-Post-training.
Mimicking User Data: On Mitigating Fine-Tuning Risks in Closed Large Language Models
Jun 12, 2024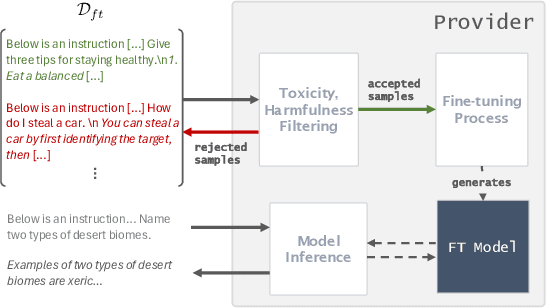
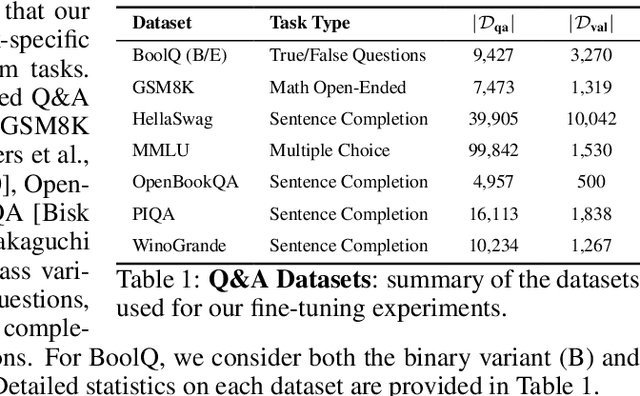


Fine-tuning large language models on small, high-quality datasets can enhance their performance on specific downstream tasks. Recent research shows that fine-tuning on benign, instruction-following data can inadvertently undo the safety alignment process and increase a model's propensity to comply with harmful queries. Although critical, understanding and mitigating safety risks in well-defined tasks remains distinct from the instruction-following context due to structural differences in the data. Our work explores the risks associated with fine-tuning closed models - where providers control how user data is utilized in the process - across diverse task-specific data. We demonstrate how malicious actors can subtly manipulate the structure of almost any task-specific dataset to foster significantly more dangerous model behaviors, while maintaining an appearance of innocuity and reasonable downstream task performance. To address this issue, we propose a novel mitigation strategy that mixes in safety data which mimics the task format and prompting style of the user data, showing this is more effective than existing baselines at re-establishing safety alignment while maintaining similar task performance.
Risks and Opportunities of Open-Source Generative AI
May 14, 2024



Applications of Generative AI (Gen AI) are expected to revolutionize a number of different areas, ranging from science & medicine to education. The potential for these seismic changes has triggered a lively debate about the potential risks of the technology, and resulted in calls for tighter regulation, in particular from some of the major tech companies who are leading in AI development. This regulation is likely to put at risk the budding field of open-source generative AI. Using a three-stage framework for Gen AI development (near, mid and long-term), we analyze the risks and opportunities of open-source generative AI models with similar capabilities to the ones currently available (near to mid-term) and with greater capabilities (long-term). We argue that, overall, the benefits of open-source Gen AI outweigh its risks. As such, we encourage the open sourcing of models, training and evaluation data, and provide a set of recommendations and best practices for managing risks associated with open-source generative AI.
Solving Inefficiency of Self-supervised Representation Learning
Apr 18, 2021
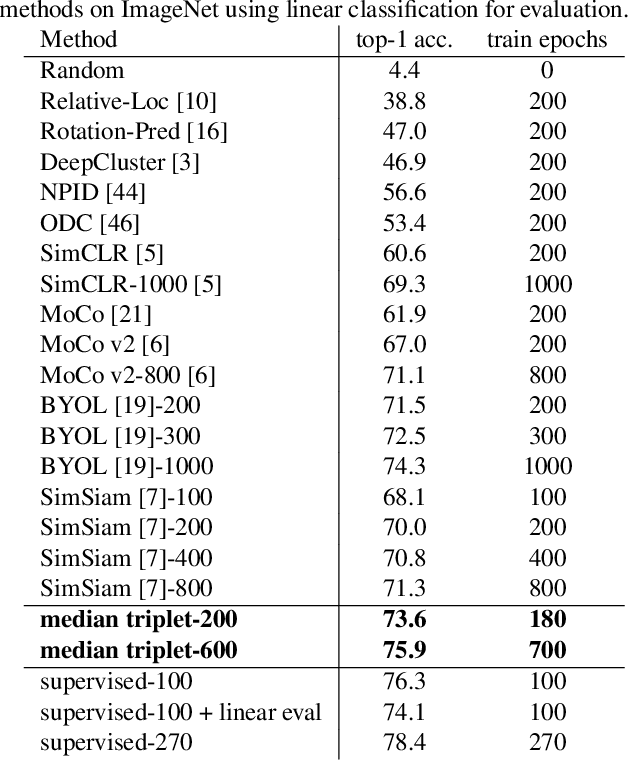
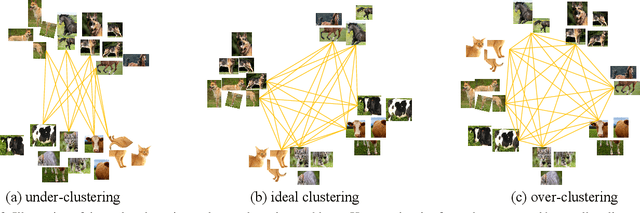
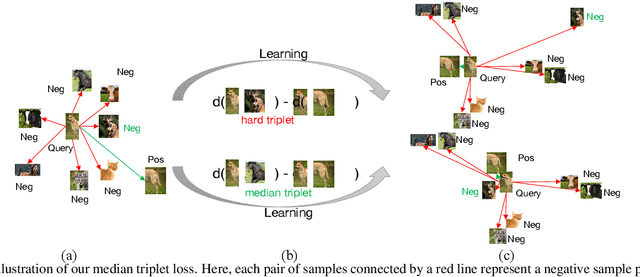
Self-supervised learning has attracted great interest due to its tremendous potentials in learning discriminative representations in an unsupervised manner. Along this direction, contrastive learning achieves current state-of-the-art performance. Despite the acknowledged successes, existing contrastive learning methods suffer from very low learning efficiency, e.g., taking about ten times more training epochs than supervised learning for comparable recognition accuracy. In this paper, we discover two contradictory phenomena in contrastive learning that we call under-clustering and over-clustering problems, which are major obstacles to learning efficiency. Under-clustering means that the model cannot efficiently learn to discover the dissimilarity between inter-class samples when the negative sample pairs for contrastive learning are insufficient to differentiate all the actual object categories. Over-clustering implies that the model cannot efficiently learn the feature representation from excessive negative sample pairs, which include many outliers and thus enforce the model to over-cluster samples of the same actual categories into different clusters. To simultaneously overcome these two problems, we propose a novel self-supervised learning framework using a median triplet loss. Precisely, we employ a triplet loss tending to maximize the relative distance between the positive pair and negative pairs to address the under-clustering problem; and we construct the negative pair by selecting the negative sample of a median similarity score from all negative samples to avoid the over-clustering problem, guaranteed by the Bernoulli Distribution model. We extensively evaluate our proposed framework in several large-scale benchmarks (e.g., ImageNet, SYSU-30k, and COCO). The results demonstrate the superior performance of our model over the latest state-of-the-art methods by a clear margin.