 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong Context In-Context Compression by Getting to the Gist of Gisting
Apr 11, 2025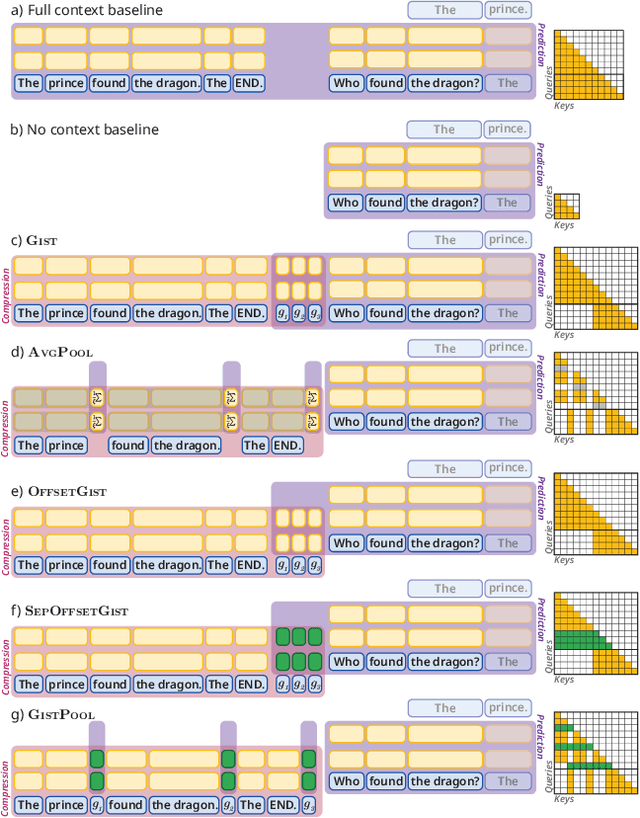
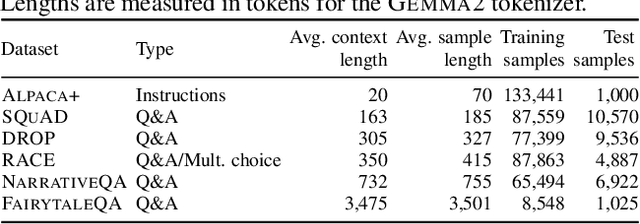
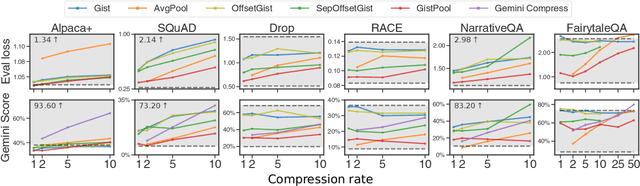
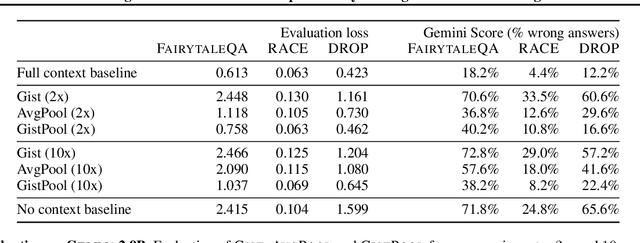
Long context processing is critical for the adoption of LLMs, but existing methods often introduce architectural complexity that hinders their practical adoption. Gisting, an in-context compression method with no architectural modification to the decoder transformer, is a promising approach due to its simplicity and compatibility with existing frameworks. While effective for short instructions, we demonstrate that gisting struggles with longer contexts, with significant performance drops even at minimal compression rates. Surprisingly, a simple average pooling baseline consistently outperforms gisting. We analyze the limitations of gisting, including information flow interruptions, capacity limitations and the inability to restrict its attention to subsets of the context. Motivated by theoretical insights into the performance gap between gisting and average pooling, and supported by extensive experimentation, we propose GistPool, a new in-context compression method. GistPool preserves the simplicity of gisting, while significantly boosting its performance on long context compression tasks.
On the Coexistence and Ensembling of Watermarks
Jan 29, 2025



Watermarking, the practice of embedding imperceptible information into media such as images, videos, audio, and text, is essential for intellectual property protection, content provenance and attribution. The growing complexity of digital ecosystems necessitates watermarks for different uses to be embedded in the same media. However, to detect and decode all watermarks, they need to coexist well with one another. We perform the first study of coexistence of deep image watermarking methods and, contrary to intuition, we find that various open-source watermarks can coexist with only minor impacts on image quality and decoding robustness. The coexistence of watermarks also opens the avenue for ensembling watermarking methods. We show how ensembling can increase the overall message capacity and enable new trade-offs between capacity, accuracy, robustness and image quality, without needing to retrain the base models.
Mimicking User Data: On Mitigating Fine-Tuning Risks in Closed Large Language Models
Jun 12, 2024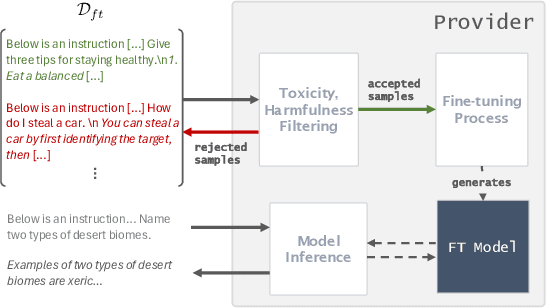
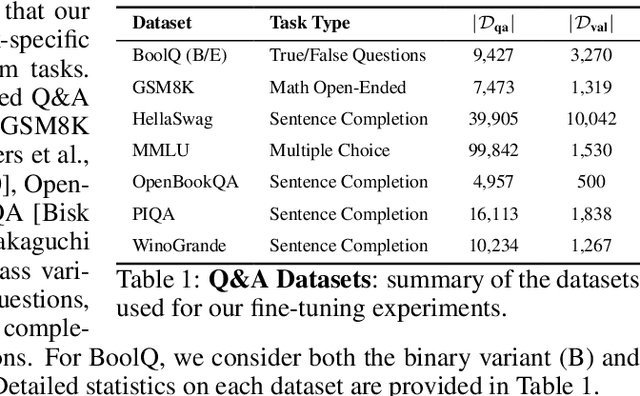


Fine-tuning large language models on small, high-quality datasets can enhance their performance on specific downstream tasks. Recent research shows that fine-tuning on benign, instruction-following data can inadvertently undo the safety alignment process and increase a model's propensity to comply with harmful queries. Although critical, understanding and mitigating safety risks in well-defined tasks remains distinct from the instruction-following context due to structural differences in the data. Our work explores the risks associated with fine-tuning closed models - where providers control how user data is utilized in the process - across diverse task-specific data. We demonstrate how malicious actors can subtly manipulate the structure of almost any task-specific dataset to foster significantly more dangerous model behaviors, while maintaining an appearance of innocuity and reasonable downstream task performance. To address this issue, we propose a novel mitigation strategy that mixes in safety data which mimics the task format and prompting style of the user data, showing this is more effective than existing baselines at re-establishing safety alignment while maintaining similar task performance.
Universal In-Context Approximation By Prompting Fully Recurrent Models
Jun 03, 2024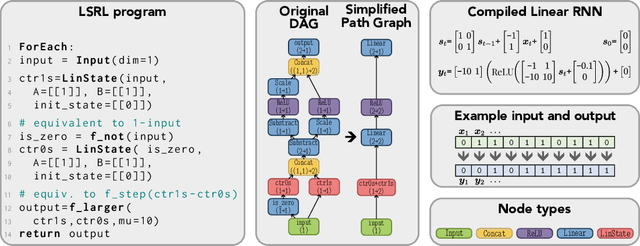
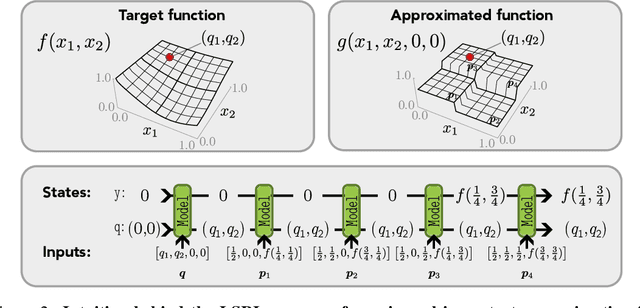

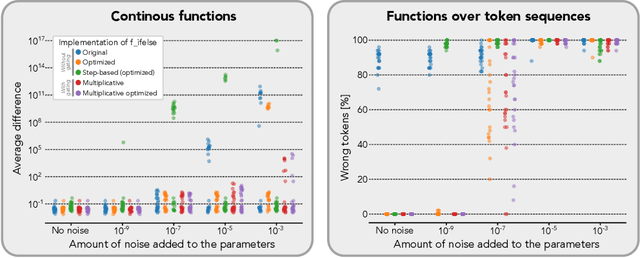
Zero-shot and in-context learning enable solving tasks without model fine-tuning, making them essential for developing generative model solutions. Therefore, it is crucial to understand whether a pretrained model can be prompted to approximate any function, i.e., whether it is a universal in-context approximator. While it was recently shown that transformer models do possess this property, these results rely on their attention mechanism. Hence, these findings do not apply to fully recurrent architectures like RNNs, LSTMs, and the increasingly popular SSMs. We demonstrate that RNNs, LSTMs, GRUs, Linear RNNs, and linear gated architectures such as Mamba and Hawk/Griffin can also serve as universal in-context approximators. To streamline our argument, we introduce a programming language called LSRL that compiles to these fully recurrent architectures. LSRL may be of independent interest for further studies of fully recurrent models, such as constructing interpretability benchmarks. We also study the role of multiplicative gating and observe that architectures incorporating such gating (e.g., LSTMs, GRUs, Hawk/Griffin) can implement certain operations more stably, making them more viable candidates for practical in-context universal approximation.
Near to Mid-term Risks and Opportunities of Open Source Generative AI
Apr 25, 2024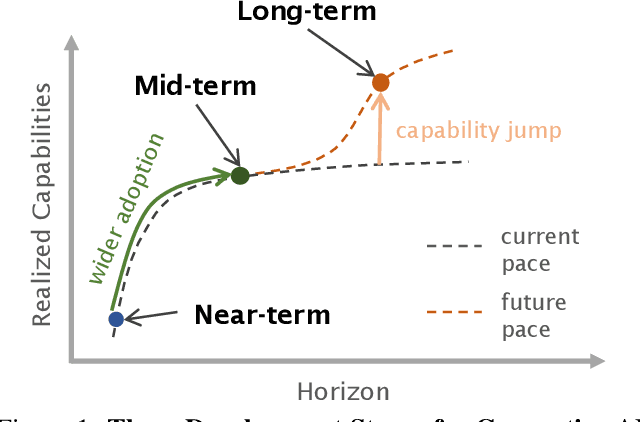
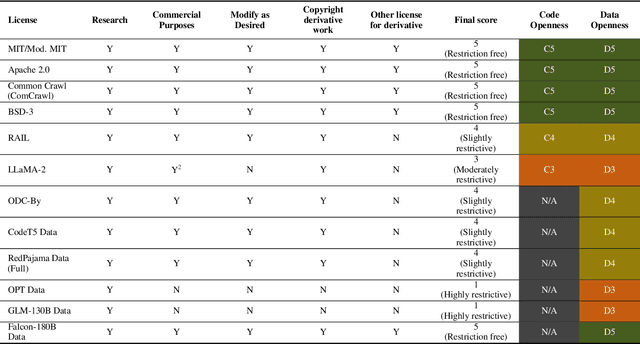
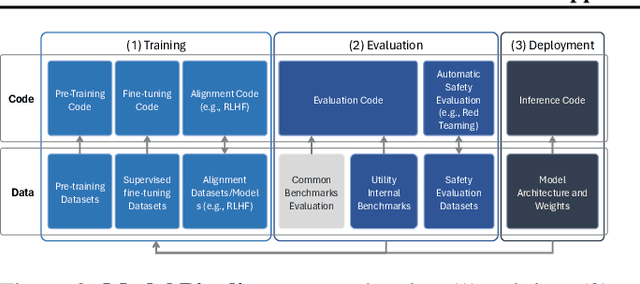
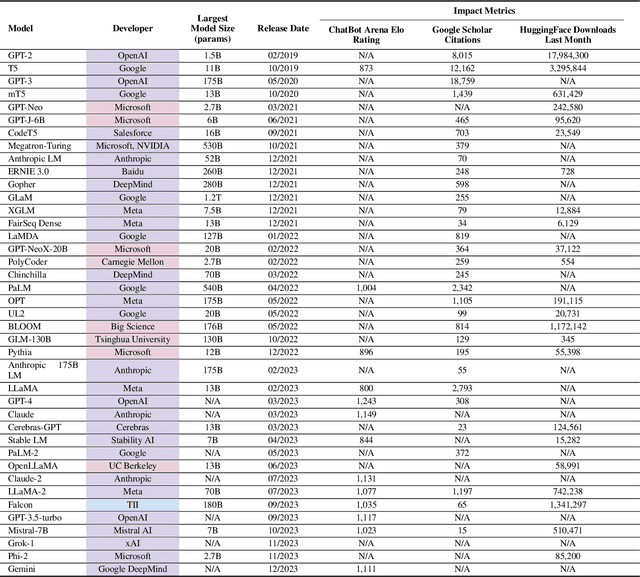
In the next few years, applications of Generative AI are expected to revolutionize a number of different areas, ranging from science & medicine to education. The potential for these seismic changes has triggered a lively debate about potential risks and resulted in calls for tighter regulation, in particular from some of the major tech companies who are leading in AI development. This regulation is likely to put at risk the budding field of open source Generative AI. We argue for the responsible open sourcing of generative AI models in the near and medium term. To set the stage, we first introduce an AI openness taxonomy system and apply it to 40 current large language models. We then outline differential benefits and risks of open versus closed source AI and present potential risk mitigation, ranging from best practices to calls for technical and scientific contributions. We hope that this report will add a much needed missing voice to the current public discourse on near to mid-term AI safety and other societal impact.
Prompting a Pretrained Transformer Can Be a Universal Approximator
Feb 22, 2024Despite the widespread adoption of prompting, prompt tuning and prefix-tuning of transformer models, our theoretical understanding of these fine-tuning methods remains limited. A key question is whether one can arbitrarily modify the behavior of pretrained model by prompting or prefix-tuning it. Formally, whether prompting and prefix-tuning a pretrained model can universally approximate sequence-to-sequence functions. This paper answers in the affirmative and demonstrates that much smaller pretrained models than previously thought can be universal approximators when prefixed. In fact, the attention mechanism is uniquely suited for universal approximation with prefix-tuning a single attention head being sufficient to approximate any continuous function. Moreover, any sequence-to-sequence function can be approximated by prefixing a transformer with depth linear in the sequence length. Beyond these density-type results, we also offer Jackson-type bounds on the length of the prefix needed to approximate a function to a desired precision.
When Do Prompting and Prefix-Tuning Work? A Theory of Capabilities and Limitations
Oct 30, 2023Context-based fine-tuning methods, including prompting, in-context learning, soft prompting (also known as prompt tuning), and prefix-tuning, have gained popularity due to their ability to often match the performance of full fine-tuning with a fraction of the parameters. Despite their empirical successes, there is little theoretical understanding of how these techniques influence the internal computation of the model and their expressiveness limitations. We show that despite the continuous embedding space being more expressive than the discrete token space, soft-prompting and prefix-tuning are strictly less expressive than full fine-tuning, even with the same number of learnable parameters. Concretely, context-based fine-tuning cannot change the relative attention pattern over the content and can only bias the outputs of an attention layer in a fixed direction. This suggests that while techniques like prompting, in-context learning, soft prompting, and prefix-tuning can effectively elicit skills present in the pretrained model, they cannot learn novel tasks that require new attention patterns.
The ARRT of Language-Models-as-a-Service: Overview of a New Paradigm and its Challenges
Sep 28, 2023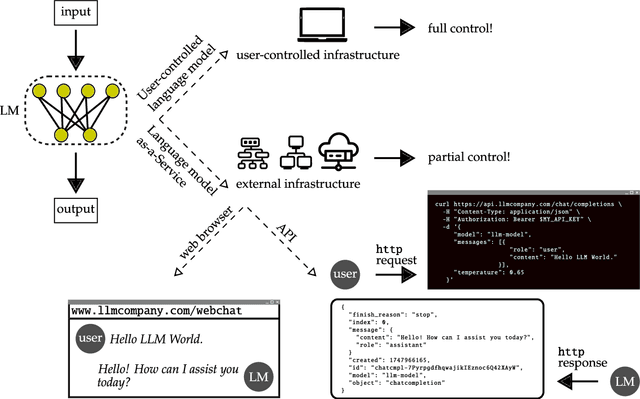

Some of the most powerful language models currently are proprietary systems, accessible only via (typically restrictive) web or software programming interfaces. This is the Language-Models-as-a-Service (LMaaS) paradigm. Contrasting with scenarios where full model access is available, as in the case of open-source models, such closed-off language models create specific challenges for evaluating, benchmarking, and testing them. This paper has two goals: on the one hand, we delineate how the aforementioned challenges act as impediments to the accessibility, replicability, reliability, and trustworthiness (ARRT) of LMaaS. We systematically examine the issues that arise from a lack of information about language models for each of these four aspects. We shed light on current solutions, provide some recommendations, and highlight the directions for future advancements. On the other hand, it serves as a one-stop-shop for the extant knowledge about current, major LMaaS, offering a synthesized overview of the licences and capabilities their interfaces offer.
Language Model Tokenizers Introduce Unfairness Between Languages
May 17, 2023



Recent language models have shown impressive multilingual performance, even when not explicitly trained for it. Despite this, concerns have been raised about the quality of their outputs across different languages. In this paper, we show how disparity in the treatment of different languages arises at the tokenization stage, well before a model is even invoked. The same text translated into different languages can have drastically different tokenization lengths, with differences up to 15 times in some cases. These disparities persist across the 17 tokenizers we evaluate, even if they are intentionally trained for multilingual support. Character-level and byte-level models also exhibit over 4 times the difference in the encoding length for some language pairs. This induces unfair treatment for some language communities in regard to the cost of accessing commercial language services, the processing time and latency, as well as the amount of content that can be provided as context to the models. Therefore, we make the case that we should train future language models using multilingually fair tokenizers.
Certifying Ensembles: A General Certification Theory with S-Lipschitzness
Apr 25, 2023Improving and guaranteeing the robustness of deep learning models has been a topic of intense research. Ensembling, which combines several classifiers to provide a better model, has shown to be beneficial for generalisation, uncertainty estimation, calibration, and mitigating the effects of concept drift. However, the impact of ensembling on certified robustness is less well understood. In this work, we generalise Lipschitz continuity by introducing S-Lipschitz classifiers, which we use to analyse the theoretical robustness of ensembles. Our results are precise conditions when ensembles of robust classifiers are more robust than any constituent classifier, as well as conditions when they are less robust.