 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Singapore Consensus on Global AI Safety Research Priorities
Jun 25, 2025


Rapidly improving AI capabilities and autonomy hold significant promise of transformation, but are also driving vigorous debate on how to ensure that AI is safe, i.e., trustworthy, reliable, and secure. Building a trusted ecosystem is therefore essential -- it helps people embrace AI with confidence and gives maximal space for innovation while avoiding backlash. The "2025 Singapore Conference on AI (SCAI): International Scientific Exchange on AI Safety" aimed to support research in this space by bringing together AI scientists across geographies to identify and synthesise research priorities in AI safety. This resulting report builds on the International AI Safety Report chaired by Yoshua Bengio and backed by 33 governments. By adopting a defence-in-depth model, this report organises AI safety research domains into three types: challenges with creating trustworthy AI systems (Development), challenges with evaluating their risks (Assessment), and challenges with monitoring and intervening after deployment (Control).
Know Thy Judge: On the Robustness Meta-Evaluation of LLM Safety Judges
Mar 06, 2025



Large Language Model (LLM) based judges form the underpinnings of key safety evaluation processes such as offline benchmarking, automated red-teaming, and online guardrailing. This widespread requirement raises the crucial question: can we trust the evaluations of these evaluators? In this paper, we highlight two critical challenges that are typically overlooked: (i) evaluations in the wild where factors like prompt sensitivity and distribution shifts can affect performance and (ii) adversarial attacks that target the judge. We highlight the importance of these through a study of commonly used safety judges, showing that small changes such as the style of the model output can lead to jumps of up to 0.24 in the false negative rate on the same dataset, whereas adversarial attacks on the model generation can fool some judges into misclassifying 100% of harmful generations as safe ones. These findings reveal gaps in commonly used meta-evaluation benchmarks and weaknesses in the robustness of current LLM judges, indicating that low attack success under certain judges could create a false sense of security.
Mimicking User Data: On Mitigating Fine-Tuning Risks in Closed Large Language Models
Jun 12, 2024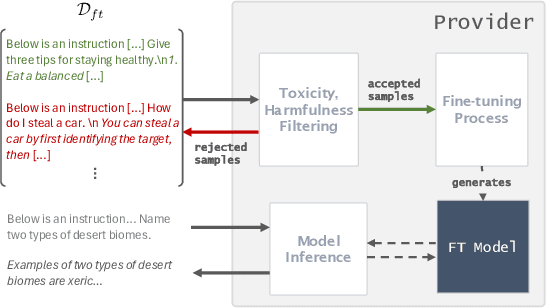


Fine-tuning large language models on small, high-quality datasets can enhance their performance on specific downstream tasks. Recent research shows that fine-tuning on benign, instruction-following data can inadvertently undo the safety alignment process and increase a model's propensity to comply with harmful queries. Although critical, understanding and mitigating safety risks in well-defined tasks remains distinct from the instruction-following context due to structural differences in the data. Our work explores the risks associated with fine-tuning closed models - where providers control how user data is utilized in the process - across diverse task-specific data. We demonstrate how malicious actors can subtly manipulate the structure of almost any task-specific dataset to foster significantly more dangerous model behaviors, while maintaining an appearance of innocuity and reasonable downstream task performance. To address this issue, we propose a novel mitigation strategy that mixes in safety data which mimics the task format and prompting style of the user data, showing this is more effective than existing baselines at re-establishing safety alignment while maintaining similar task performance.
Risks and Opportunities of Open-Source Generative AI
May 14, 2024



Applications of Generative AI (Gen AI) are expected to revolutionize a number of different areas, ranging from science & medicine to education. The potential for these seismic changes has triggered a lively debate about the potential risks of the technology, and resulted in calls for tighter regulation, in particular from some of the major tech companies who are leading in AI development. This regulation is likely to put at risk the budding field of open-source generative AI. Using a three-stage framework for Gen AI development (near, mid and long-term), we analyze the risks and opportunities of open-source generative AI models with similar capabilities to the ones currently available (near to mid-term) and with greater capabilities (long-term). We argue that, overall, the benefits of open-source Gen AI outweigh its risks. As such, we encourage the open sourcing of models, training and evaluation data, and provide a set of recommendations and best practices for managing risks associated with open-source generative AI.
Near to Mid-term Risks and Opportunities of Open Source Generative AI
Apr 25, 2024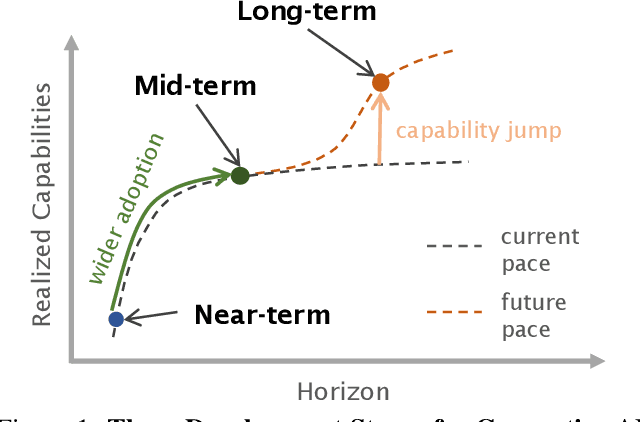
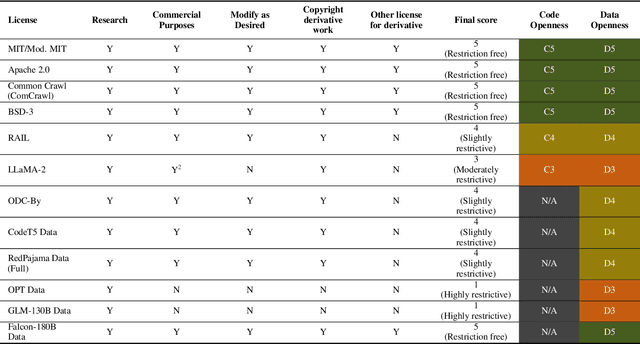
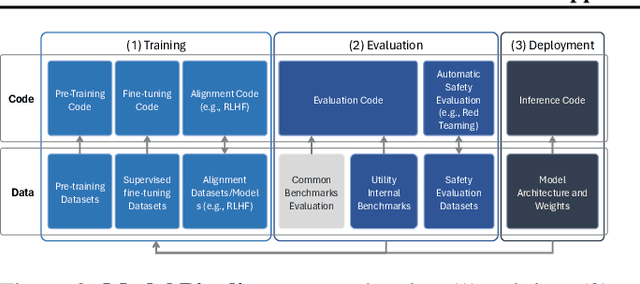
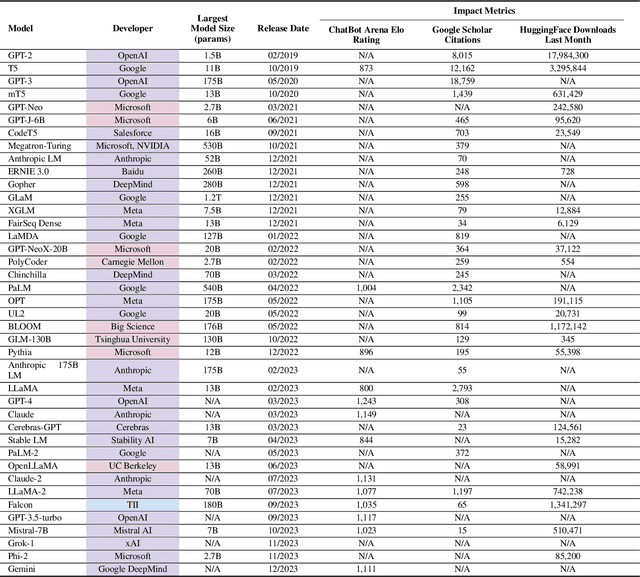
In the next few years, applications of Generative AI are expected to revolutionize a number of different areas, ranging from science & medicine to education. The potential for these seismic changes has triggered a lively debate about potential risks and resulted in calls for tighter regulation, in particular from some of the major tech companies who are leading in AI development. This regulation is likely to put at risk the budding field of open source Generative AI. We argue for the responsible open sourcing of generative AI models in the near and medium term. To set the stage, we first introduce an AI openness taxonomy system and apply it to 40 current large language models. We then outline differential benefits and risks of open versus closed source AI and present potential risk mitigation, ranging from best practices to calls for technical and scientific contributions. We hope that this report will add a much needed missing voice to the current public discourse on near to mid-term AI safety and other societal impact.
Segment, Select, Correct: A Framework for Weakly-Supervised Referring Segmentation
Oct 23, 2023Referring Image Segmentation (RIS) - the problem of identifying objects in images through natural language sentences - is a challenging task currently mostly solved through supervised learning. However, while collecting referred annotation masks is a time-consuming process, the few existing weakly-supervised and zero-shot approaches fall significantly short in performance compared to fully-supervised learning ones. To bridge the performance gap without mask annotations, we propose a novel weakly-supervised framework that tackles RIS by decomposing it into three steps: obtaining instance masks for the object mentioned in the referencing instruction (segment), using zero-shot learning to select a potentially correct mask for the given instruction (select), and bootstrapping a model which allows for fixing the mistakes of zero-shot selection (correct). In our experiments, using only the first two steps (zero-shot segment and select) outperforms other zero-shot baselines by as much as 19%, while our full method improves upon this much stronger baseline and sets the new state-of-the-art for weakly-supervised RIS, reducing the gap between the weakly-supervised and fully-supervised methods in some cases from around 33% to as little as 14%. Code is available at https://github.com/fgirbal/segment-select-correct.
Faithful Knowledge Distillation
Jun 08, 2023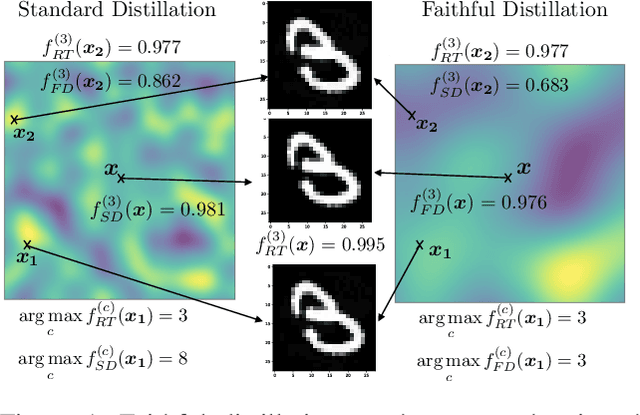
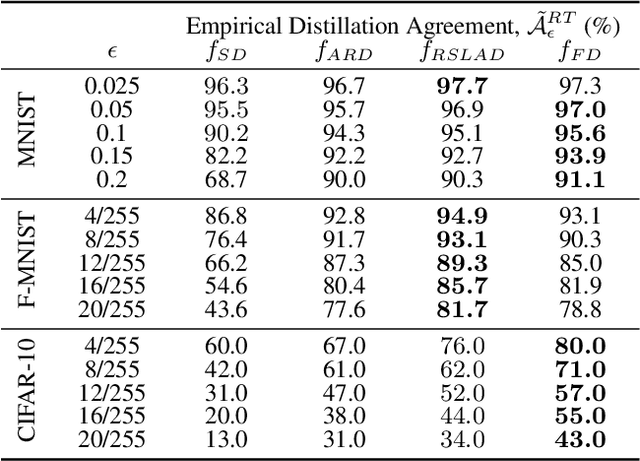


Knowledge distillation (KD) has received much attention due to its success in compressing networks to allow for their deployment in resource-constrained systems. While the problem of adversarial robustness has been studied before in the KD setting, previous works overlook what we term the relative calibration of the student network with respect to its teacher in terms of soft confidences. In particular, we focus on two crucial questions with regard to a teacher-student pair: (i) do the teacher and student disagree at points close to correctly classified dataset examples, and (ii) is the distilled student as confident as the teacher around dataset examples? These are critical questions when considering the deployment of a smaller student network trained from a robust teacher within a safety-critical setting. To address these questions, we introduce a faithful imitation framework to discuss the relative calibration of confidences, as well as provide empirical and certified methods to evaluate the relative calibration of a student w.r.t. its teacher. Further, to verifiably align the relative calibration incentives of the student to those of its teacher, we introduce faithful distillation. Our experiments on the MNIST and Fashion-MNIST datasets demonstrate the need for such an analysis and the advantages of the increased verifiability of faithful distillation over alternative adversarial distillation methods.
Provably Correct Physics-Informed Neural Networks
May 17, 2023Recent work provides promising evidence that Physics-informed neural networks (PINN) can efficiently solve partial differential equations (PDE). However, previous works have failed to provide guarantees on the worst-case residual error of a PINN across the spatio-temporal domain - a measure akin to the tolerance of numerical solvers - focusing instead on point-wise comparisons between their solution and the ones obtained by a solver on a set of inputs. In real-world applications, one cannot consider tests on a finite set of points to be sufficient grounds for deployment, as the performance could be substantially worse on a different set. To alleviate this issue, we establish tolerance-based correctness conditions for PINNs over the entire input domain. To verify the extent to which they hold, we introduce $\partial$-CROWN: a general, efficient and scalable post-training framework to bound PINN residual errors. We demonstrate its effectiveness in obtaining tight certificates by applying it to two classically studied PDEs - Burgers' and Schr\"odinger's equations -, and two more challenging ones with real-world applications - the Allan-Cahn and Diffusion-Sorption equations.
Certifying Ensembles: A General Certification Theory with S-Lipschitzness
Apr 25, 2023Improving and guaranteeing the robustness of deep learning models has been a topic of intense research. Ensembling, which combines several classifiers to provide a better model, has shown to be beneficial for generalisation, uncertainty estimation, calibration, and mitigating the effects of concept drift. However, the impact of ensembling on certified robustness is less well understood. In this work, we generalise Lipschitz continuity by introducing S-Lipschitz classifiers, which we use to analyse the theoretical robustness of ensembles. Our results are precise conditions when ensembles of robust classifiers are more robust than any constituent classifier, as well as conditions when they are less robust.
Interpretable Goal Recognition in the Presence of Occluded Factors for Autonomous Vehicles
Aug 05, 2021
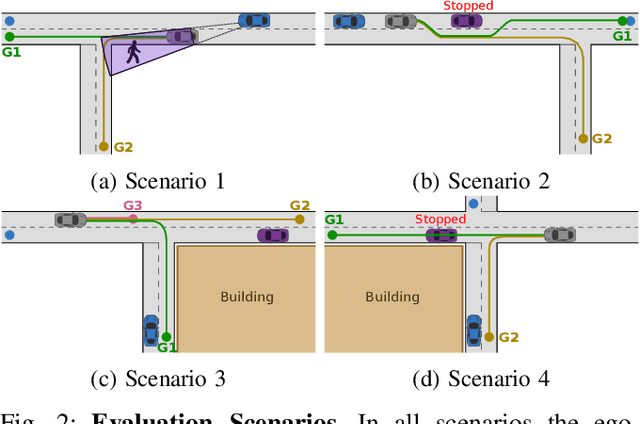
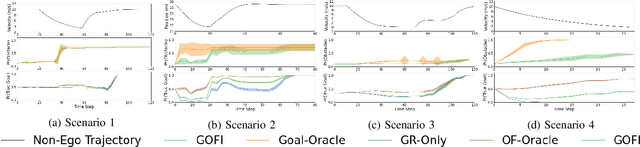
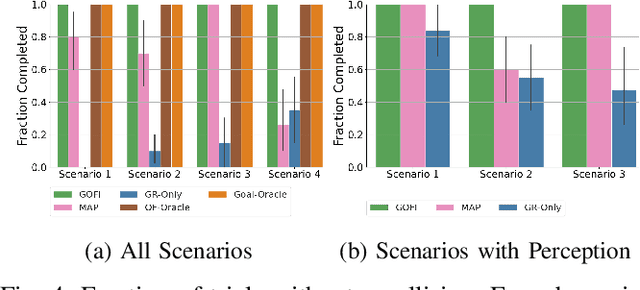
Recognising the goals or intentions of observed vehicles is a key step towards predicting the long-term future behaviour of other agents in an autonomous driving scenario. When there are unseen obstacles or occluded vehicles in a scenario, goal recognition may be confounded by the effects of these unseen entities on the behaviour of observed vehicles. Existing prediction algorithms that assume rational behaviour with respect to inferred goals may fail to make accurate long-horizon predictions because they ignore the possibility that the behaviour is influenced by such unseen entities. We introduce the Goal and Occluded Factor Inference (GOFI) algorithm which bases inference on inverse-planning to jointly infer a probabilistic belief over goals and potential occluded factors. We then show how these beliefs can be integrated into Monte Carlo Tree Search (MCTS). We demonstrate that jointly inferring goals and occluded factors leads to more accurate beliefs with respect to the true world state and allows an agent to safely navigate several scenarios where other baselines take unsafe actions leading to collisions.