 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCODA: Coordination via On-Policy Diffusion for Multi-Agent Offline Reinforcement Learning
Apr 25, 2026Offline multi-agent reinforcement learning (MARL) enables policy learning from fixed datasets, but is prone to coordination failure: agents trained on static, off-policy data converge to suboptimal joint behaviours because they cannot co-adapt as their policies change. We introduce CODA (Coordination via On-Policy Diffusion for Multi-Agent Reinforcement Learning), a diffusion-based multi-agent trajectory generator for data augmentation that samples conditioned on the current joint policy, producing synthetic experience which reflects the evolving behaviours of the agents, thereby providing a mechanism for co-adaptation. We find that previous diffusion-based augmentation approaches are insufficient for fostering multi-agent coordination because they produce static augmented datasets that do not evolve as the current joint policy changes during training; CODA resolves this by more closely simulating on-policy learning and is a meaningful step toward coordinated behaviours in the offline setting. CODA is algorithm-agnostic and can be layered onto both model-free and model-based offline reinforcement learning pipelines as an augmentation module. Empirically, CODA not only resolves canonical coordination pathologies in continuous polynomial games but also delivers strong results on the more complex MaMuJoCo continuous-control benchmarks.
Learning Complex Teamwork Tasks using a Sub-task Curriculum
Feb 09, 2023



Training a team to complete a complex task via multi-agent reinforcement learning can be difficult due to challenges such as policy search in a large policy space, and non-stationarity caused by mutually adapting agents. To facilitate efficient learning of complex multi-agent tasks, we propose an approach which uses an expert-provided curriculum of simpler multi-agent sub-tasks. In each sub-task of the curriculum, a subset of the entire team is trained to acquire sub-task-specific policies. The sub-teams are then merged and transferred to the target task, where their policies are collectively fined tuned to solve the more complex target task. We present MEDoE, a flexible method which identifies situations in the target task where each agent can use its sub-task-specific skills, and uses this information to modulate hyperparameters for learning and exploration during the fine-tuning process. We compare MEDoE to multi-agent reinforcement learning baselines that train from scratch in the full task, and with na\"ive applications of standard multi-agent reinforcement learning techniques for fine-tuning. We show that MEDoE outperforms baselines which train from scratch or use na\"ive fine-tuning approaches, requiring significantly fewer total training timesteps to solve a range of complex teamwork tasks.
Deep Reinforcement Learning for Multi-Agent Interaction
Aug 02, 2022The development of autonomous agents which can interact with other agents to accomplish a given task is a core area of research in artificial intelligence and machine learning. Towards this goal, the Autonomous Agents Research Group develops novel machine learning algorithms for autonomous systems control, with a specific focus on deep reinforcement learning and multi-agent reinforcement learning. Research problems include scalable learning of coordinated agent policies and inter-agent communication; reasoning about the behaviours, goals, and composition of other agents from limited observations; and sample-efficient learning based on intrinsic motivation, curriculum learning, causal inference, and representation learning. This article provides a broad overview of the ongoing research portfolio of the group and discusses open problems for future directions.
Towards Robust Ad Hoc Teamwork Agents By Creating Diverse Training Teammates
Jul 28, 2022

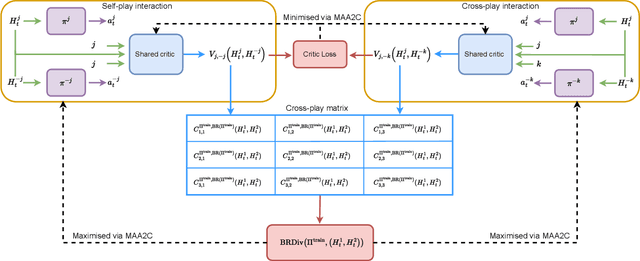

Ad hoc teamwork (AHT) is the problem of creating an agent that must collaborate with previously unseen teammates without prior coordination. Many existing AHT methods can be categorised as type-based methods, which require a set of predefined teammates for training. Designing teammate types for training is a challenging issue that determines the generalisation performance of agents when dealing with teammate types unseen during training. In this work, we propose a method to discover diverse teammate types based on maximising best response diversity metrics. We show that our proposed approach yields teammate types that require a wider range of best responses from the learner during collaboration, which potentially improves the robustness of a learner's performance in AHT compared to alternative methods.
Few-Shot Teamwork
Jul 19, 2022We propose the novel few-shot teamwork (FST) problem, where skilled agents trained in a team to complete one task are combined with skilled agents from different tasks, and together must learn to adapt to an unseen but related task. We discuss how the FST problem can be seen as addressing two separate problems: one of reducing the experience required to train a team of agents to complete a complex task; and one of collaborating with unfamiliar teammates to complete a new task. Progress towards solving FST could lead to progress in both multi-agent reinforcement learning and ad hoc teamwork.
A Survey of Ad Hoc Teamwork: Definitions, Methods, and Open Problems
Feb 16, 2022
Ad hoc teamwork is the well-established research problem of designing agents that can collaborate with new teammates without prior coordination. This survey makes a two-fold contribution. First, it provides a structured description of the different facets of the ad hoc teamwork problem. Second, it discusses the progress that has been made in the field so far, and identifies the immediate and long-term open problems that need to be addressed in the field of ad hoc teamwork.
Interpretable Goal Recognition in the Presence of Occluded Factors for Autonomous Vehicles
Aug 05, 2021
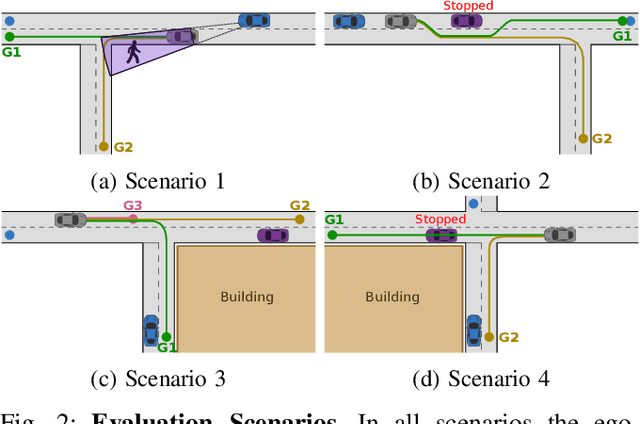
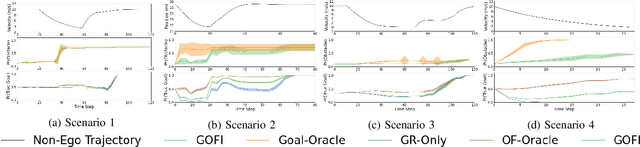
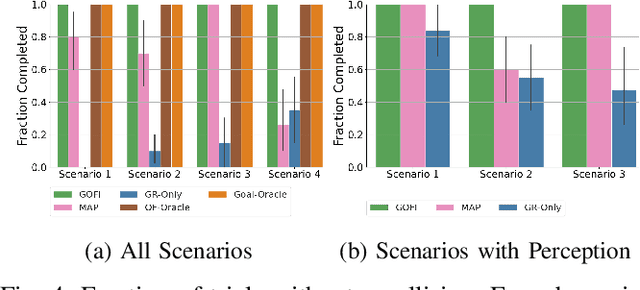
Recognising the goals or intentions of observed vehicles is a key step towards predicting the long-term future behaviour of other agents in an autonomous driving scenario. When there are unseen obstacles or occluded vehicles in a scenario, goal recognition may be confounded by the effects of these unseen entities on the behaviour of observed vehicles. Existing prediction algorithms that assume rational behaviour with respect to inferred goals may fail to make accurate long-horizon predictions because they ignore the possibility that the behaviour is influenced by such unseen entities. We introduce the Goal and Occluded Factor Inference (GOFI) algorithm which bases inference on inverse-planning to jointly infer a probabilistic belief over goals and potential occluded factors. We then show how these beliefs can be integrated into Monte Carlo Tree Search (MCTS). We demonstrate that jointly inferring goals and occluded factors leads to more accurate beliefs with respect to the true world state and allows an agent to safely navigate several scenarios where other baselines take unsafe actions leading to collisions.