 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging LLMs for Legacy Code Modernization: Challenges and Opportunities for LLM-Generated Documentation
Nov 22, 2024

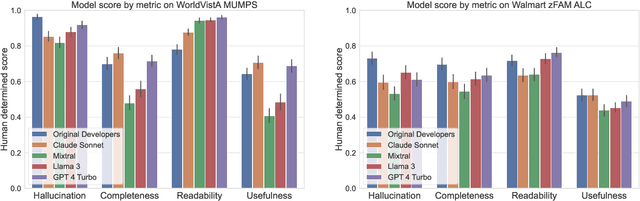

Legacy software systems, written in outdated languages like MUMPS and mainframe assembly, pose challenges in efficiency, maintenance, staffing, and security. While LLMs offer promise for modernizing these systems, their ability to understand legacy languages is largely unknown. This paper investigates the utilization of LLMs to generate documentation for legacy code using two datasets: an electronic health records (EHR) system in MUMPS and open-source applications in IBM mainframe Assembly Language Code (ALC). We propose a prompting strategy for generating line-wise code comments and a rubric to evaluate their completeness, readability, usefulness, and hallucination. Our study assesses the correlation between human evaluations and automated metrics, such as code complexity and reference-based metrics. We find that LLM-generated comments for MUMPS and ALC are generally hallucination-free, complete, readable, and useful compared to ground-truth comments, though ALC poses challenges. However, no automated metrics strongly correlate with comment quality to predict or measure LLM performance. Our findings highlight the limitations of current automated measures and the need for better evaluation metrics for LLM-generated documentation in legacy systems.
Testing the Effect of Code Documentation on Large Language Model Code Understanding
Apr 03, 2024Large Language Models (LLMs) have demonstrated impressive abilities in recent years with regards to code generation and understanding. However, little work has investigated how documentation and other code properties affect an LLM's ability to understand and generate code or documentation. We present an empirical analysis of how underlying properties of code or documentation can affect an LLM's capabilities. We show that providing an LLM with "incorrect" documentation can greatly hinder code understanding, while incomplete or missing documentation does not seem to significantly affect an LLM's ability to understand code.
Exploring the Cost of Interruptions in Human-Robot Teaming
Nov 01, 2023



Productive and efficient human-robot teaming is a highly desirable ability in service robots, yet there is a fundamental trade-off that a robot needs to consider in such tasks. On the one hand, gaining information from communication with teammates can help individual planning. On the other hand, such communication comes at the cost of distracting teammates from efficiently completing their goals, which can also harm the overall team performance. In this study, we quantify the cost of interruptions in terms of degradation of human task performance, as a robot interrupts its teammate to gain information about their task. Interruptions are varied in timing, content, and proximity. The results show that people find the interrupting robot significantly less helpful. However, the human teammate's performance in a secondary task deteriorates only slightly when interrupted. These results imply that while interruptions can objectively have a low cost, an uninformed implementation can cause these interruptions to be perceived as distracting. These research outcomes can be leveraged in numerous applications where collaborative robots must be aware of the costs and gains of interruptive communication, including logistics and service robots.
A Survey of Ad Hoc Teamwork: Definitions, Methods, and Open Problems
Feb 16, 2022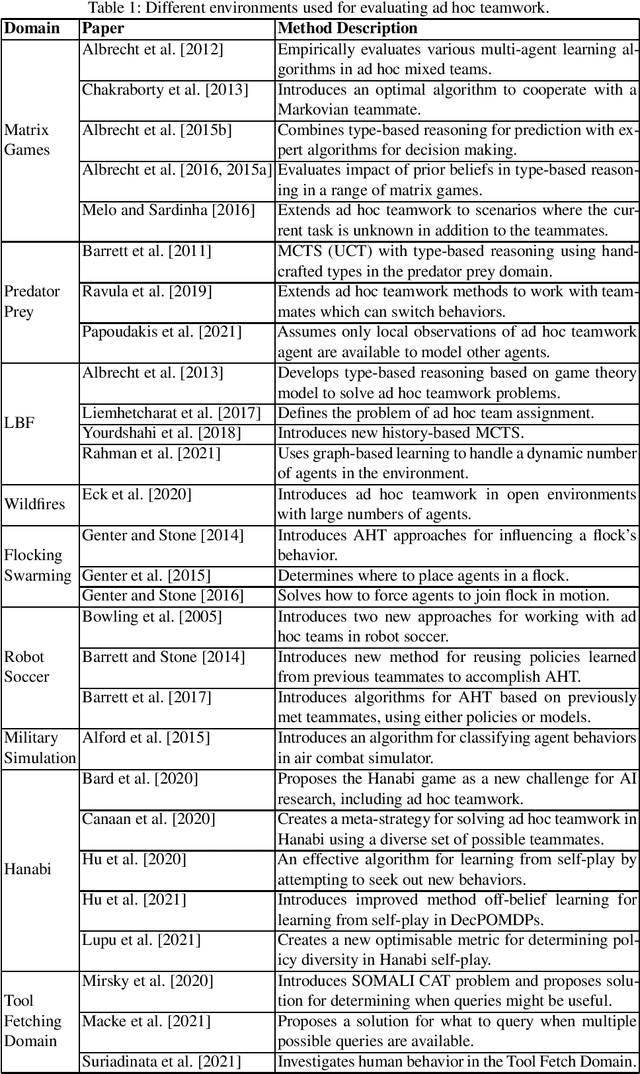
Ad hoc teamwork is the well-established research problem of designing agents that can collaborate with new teammates without prior coordination. This survey makes a two-fold contribution. First, it provides a structured description of the different facets of the ad hoc teamwork problem. Second, it discusses the progress that has been made in the field so far, and identifies the immediate and long-term open problems that need to be addressed in the field of ad hoc teamwork.
Learning a Robust Multiagent Driving Policy for Traffic Congestion Reduction
Dec 03, 2021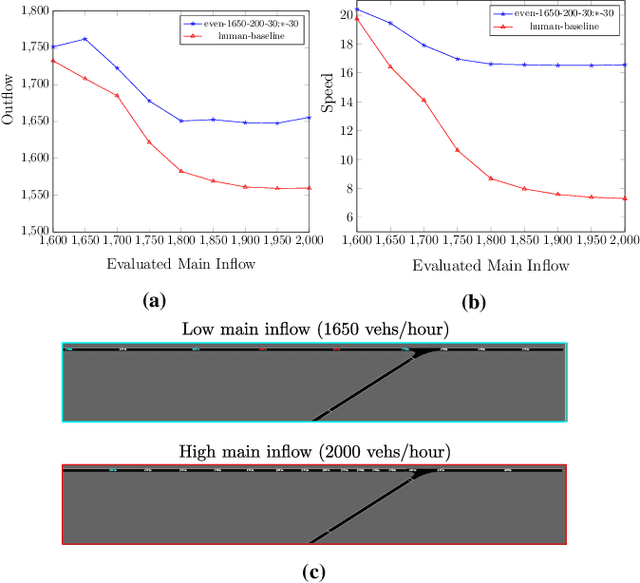
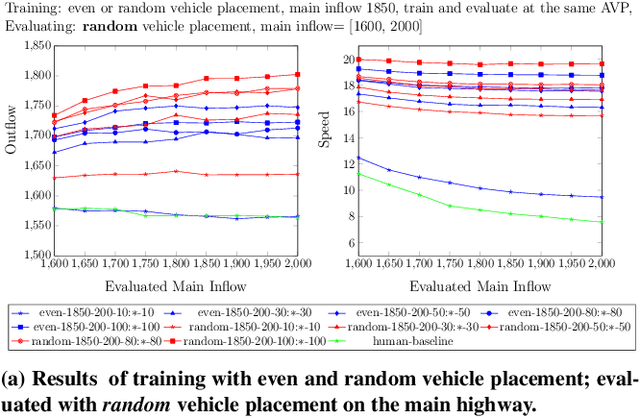
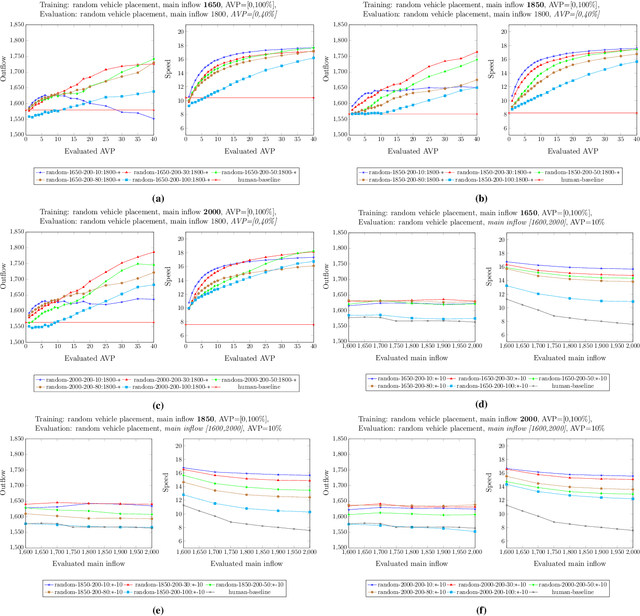
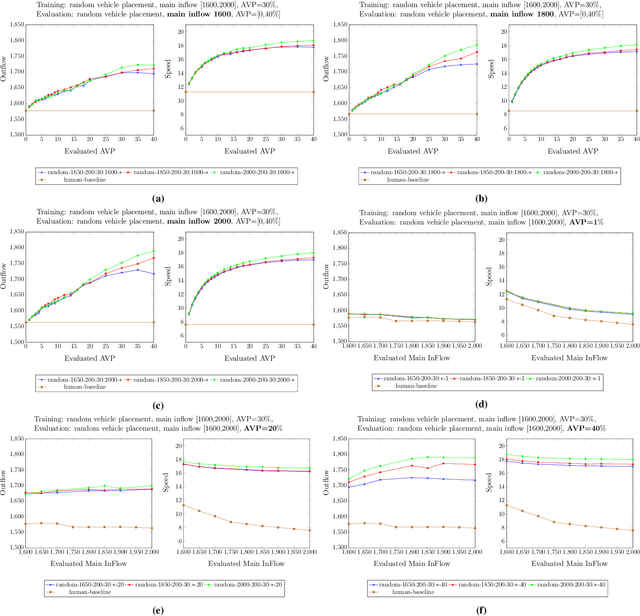
The advent of automated and autonomous vehicles (AVs) creates opportunities to achieve system-level goals using multiple AVs, such as traffic congestion reduction. Past research has shown that multiagent congestion-reducing driving policies can be learned in a variety of simulated scenarios. While initial proofs of concept were in small, closed traffic networks with a centralized controller, recently successful results have been demonstrated in more realistic settings with distributed control policies operating in open road networks where vehicles enter and leave. However, these driving policies were mostly tested under the same conditions they were trained on, and have not been thoroughly tested for robustness to different traffic conditions, which is a critical requirement in real-world scenarios. This paper presents a learned multiagent driving policy that is robust to a variety of open-network traffic conditions, including vehicle flows, the fraction of AVs in traffic, AV placement, and different merging road geometries. A thorough empirical analysis investigates the sensitivity of such a policy to the amount of AVs in both a simple merge network and a more complex road with two merging ramps. It shows that the learned policy achieves significant improvement over simulated human-driven policies even with AV penetration as low as 2%. The same policy is also shown to be capable of reducing traffic congestion in more complex roads with two merging ramps.
Expected Value of Communication for Planning in Ad Hoc Teamwork
Mar 01, 2021

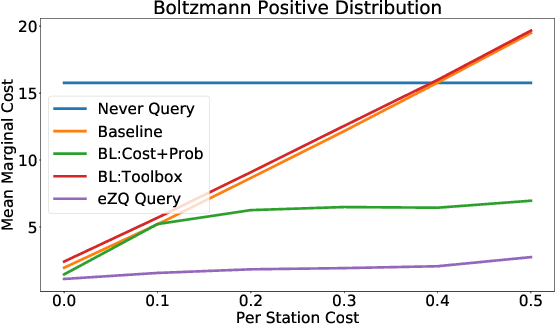
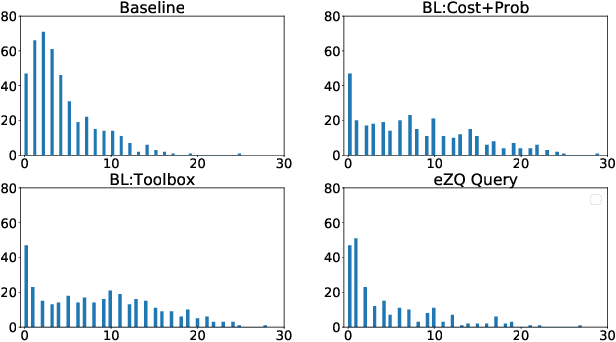
A desirable goal for autonomous agents is to be able to coordinate on the fly with previously unknown teammates. Known as "ad hoc teamwork", enabling such a capability has been receiving increasing attention in the research community. One of the central challenges in ad hoc teamwork is quickly recognizing the current plans of other agents and planning accordingly. In this paper, we focus on the scenario in which teammates can communicate with one another, but only at a cost. Thus, they must carefully balance plan recognition based on observations vs. that based on communication. This paper proposes a new metric for evaluating how similar are two policies that a teammate may be following - the Expected Divergence Point (EDP). We then present a novel planning algorithm for ad hoc teamwork, determining which query to ask and planning accordingly. We demonstrate the effectiveness of this algorithm in a range of increasingly general communication in ad hoc teamwork problems.
Scalable Multiagent Driving Policies For Reducing Traffic Congestion
Feb 26, 2021

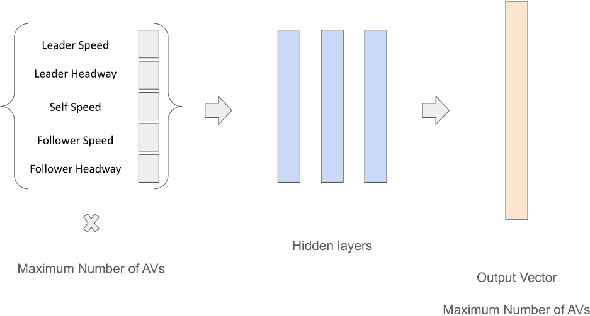

Traffic congestion is a major challenge in modern urban settings. The industry-wide development of autonomous and automated vehicles (AVs) motivates the question of how can AVs contribute to congestion reduction. Past research has shown that in small scale mixed traffic scenarios with both AVs and human-driven vehicles, a small fraction of AVs executing a controlled multiagent driving policy can mitigate congestion. In this paper, we scale up existing approaches and develop new multiagent driving policies for AVs in scenarios with greater complexity. We start by showing that a congestion metric used by past research is manipulable in open road network scenarios where vehicles dynamically join and leave the road. We then propose using a different metric that is robust to manipulation and reflects open network traffic efficiency. Next, we propose a modular transfer reinforcement learning approach, and use it to scale up a multiagent driving policy to outperform human-like traffic and existing approaches in a simulated realistic scenario, which is an order of magnitude larger than past scenarios (hundreds instead of tens of vehicles). Additionally, our modular transfer learning approach saves up to 80% of the training time in our experiments, by focusing its data collection on key locations in the network. Finally, we show for the first time a distributed multiagent policy that improves congestion over human-driven traffic. The distributed approach is more realistic and practical, as it relies solely on existing sensing and actuation capabilities, and does not require adding new communication infrastructure.
Evolutionary Optimization of Deep Learning Activation Functions
Feb 17, 2020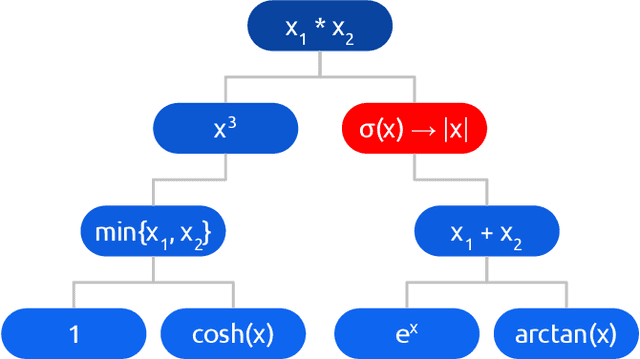

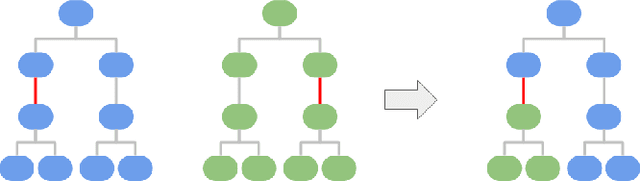

The choice of activation function can have a large effect on the performance of a neural network. While there have been some attempts to hand-engineer novel activation functions, the Rectified Linear Unit (ReLU) remains the most commonly-used in practice. This paper shows that evolutionary algorithms can discover novel activation functions that outperform ReLU. A tree-based search space of candidate activation functions is defined and explored with mutation, crossover, and exhaustive search. Experiments on training wide residual networks on the CIFAR-10 and CIFAR-100 image datasets show that this approach is effective. Replacing ReLU with evolved activation functions results in statistically significant increases in network accuracy. Optimal performance is achieved when evolution is allowed to customize activation functions to a particular task; however, these novel activation functions are shown to generalize, achieving high performance across tasks. Evolutionary optimization of activation functions is therefore a promising new dimension of metalearning in neural networks.