 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBXRL: Behavior-Explainable Reinforcement Learning
Mar 24, 2026A major challenge of Reinforcement Learning is that agents often learn undesired behaviors that seem to defy the reward structure they were given. Explainable Reinforcement Learning (XRL) methods can answer queries such as "explain this specific action", "explain this specific trajectory", and "explain the entire policy". However, XRL lacks a formal definition for behavior as a pattern of actions across many episodes. We provide such a definition, and use it to enable a new query: "Explain this behavior". We present Behavior-Explainable Reinforcement Learning (BXRL), a new problem formulation that treats behaviors as first-class objects. BXRL defines a behavior measure as any function $m : Π\to \mathbb{R}$, allowing users to precisely express the pattern of actions that they find interesting and measure how strongly the policy exhibits it. We define contrastive behaviors that reduce the question "why does the agent prefer $a$ to $a'$?" to "why is $m(π)$ high?" which can be explored with differentiation. We do not implement an explainability method; we instead analyze three existing methods and propose how they could be adapted to explain behavior. We present a port of the HighwayEnv driving environment to JAX, which provides an interface for defining, measuring, and differentiating behaviors with respect to the model parameters.
The Intelligent Disobedience Game: Formulating Disobedience in Stackelberg Games and Markov Decision Processes
Mar 22, 2026In shared autonomy, a critical tension arises when an automated assistant must choose between obeying a human's instruction and deliberately overriding it to prevent harm. This safety-critical behavior is known as intelligent disobedience. To formalize this dynamic, this paper introduces the Intelligent Disobedience Game (IDG), a sequential game-theoretic framework based on Stackelberg games that models the interaction between a human leader and an assistive follower operating under asymmetric information. It characterizes optimal strategies for both agents across multi-step scenarios, identifying strategic phenomena such as ``safety traps,'' where the system indefinitely avoids harm but fails to achieve the human's goal. The IDG provides a needed mathematical foundation that enables both the algorithmic development of agents that can learn safe non-compliance and the empirical study of how humans perceive and trust disobedient AI. The paper further translates the IDG into a shared control Multi-Agent Markov Decision Process representation, forming a compact computational testbed for training reinforcement learning agents.
Proceedings of the 2nd Workshop on Advancing Artificial Intelligence through Theory of Mind
Mar 19, 2026This volume includes a selection of papers presented at the 2nd Workshop on Advancing Artificial Intelligence through Theory of Mind held at AAAI 2026 in Singapore on 26th January 2026. The purpose of this volume is to provide an open access and curated anthology for the ToM and AI research community.
Agents of Chaos
Feb 23, 2026We report an exploratory red-teaming study of autonomous language-model-powered agents deployed in a live laboratory environment with persistent memory, email accounts, Discord access, file systems, and shell execution. Over a two-week period, twenty AI researchers interacted with the agents under benign and adversarial conditions. Focusing on failures emerging from the integration of language models with autonomy, tool use, and multi-party communication, we document eleven representative case studies. Observed behaviors include unauthorized compliance with non-owners, disclosure of sensitive information, execution of destructive system-level actions, denial-of-service conditions, uncontrolled resource consumption, identity spoofing vulnerabilities, cross-agent propagation of unsafe practices, and partial system takeover. In several cases, agents reported task completion while the underlying system state contradicted those reports. We also report on some of the failed attempts. Our findings establish the existence of security-, privacy-, and governance-relevant vulnerabilities in realistic deployment settings. These behaviors raise unresolved questions regarding accountability, delegated authority, and responsibility for downstream harms, and warrant urgent attention from legal scholars, policymakers, and researchers across disciplines. This report serves as an initial empirical contribution to that broader conversation.
GRAIL: Goal Recognition Alignment through Imitation Learning
Feb 15, 2026Understanding an agent's goals from its behavior is fundamental to aligning AI systems with human intentions. Existing goal recognition methods typically rely on an optimal goal-oriented policy representation, which may differ from the actor's true behavior and hinder the accurate recognition of their goal. To address this gap, this paper introduces Goal Recognition Alignment through Imitation Learning (GRAIL), which leverages imitation learning and inverse reinforcement learning to learn one goal-directed policy for each candidate goal directly from (potentially suboptimal) demonstration trajectories. By scoring an observed partial trajectory with each learned goal-directed policy in a single forward pass, GRAIL retains the one-shot inference capability of classical goal recognition while leveraging learned policies that can capture suboptimal and systematically biased behavior. Across the evaluated domains, GRAIL increases the F1-score by more than 0.5 under systematically biased optimal behavior, achieves gains of approximately 0.1-0.3 under suboptimal behavior, and yields improvements of up to 0.4 under noisy optimal trajectories, while remaining competitive in fully optimal settings. This work contributes toward scalable and robust models for interpreting agent goals in uncertain environments.
Break Out the Silverware -- Semantic Understanding of Stored Household Items
Dec 25, 2025``Bring me a plate.'' For domestic service robots, this simple command reveals a complex challenge: inferring where everyday items are stored, often out of sight in drawers, cabinets, or closets. Despite advances in vision and manipulation, robots still lack the commonsense reasoning needed to complete this task. We introduce the Stored Household Item Challenge, a benchmark task for evaluating service robots' cognitive capabilities: given a household scene and a queried item, predict its most likely storage location. Our benchmark includes two datasets: (1) a real-world evaluation set of 100 item-image pairs with human-annotated ground truth from participants' kitchens, and (2) a development set of 6,500 item-image pairs annotated with storage polygons over public kitchen images. These datasets support realistic modeling of household organization and enable comparative evaluation across agent architectures. To begin tackling this challenge, we introduce NOAM (Non-visible Object Allocation Model), a hybrid agent pipeline that combines structured scene understanding with large language model inference. NOAM converts visual input into natural language descriptions of spatial context and visible containers, then prompts a language model (e.g., GPT-4) to infer the most likely hidden storage location. This integrated vision-language agent exhibits emergent commonsense reasoning and is designed for modular deployment within broader robotic systems. We evaluate NOAM against baselines including random selection, vision-language pipelines (Grounding-DINO + SAM), leading multimodal models (e.g., Gemini, GPT-4o, Kosmos-2, LLaMA, Qwen), and human performance. NOAM significantly improves prediction accuracy and approaches human-level results, highlighting best practices for deploying cognitively capable agents in domestic environments.
General Dynamic Goal Recognition
May 14, 2025Understanding an agent's intent through its behavior is essential in human-robot interaction, interactive AI systems, and multi-agent collaborations. This task, known as Goal Recognition (GR), poses significant challenges in dynamic environments where goals are numerous and constantly evolving. Traditional GR methods, designed for a predefined set of goals, often struggle to adapt to these dynamic scenarios. To address this limitation, we introduce the General Dynamic GR problem - a broader definition of GR - aimed at enabling real-time GR systems and fostering further research in this area. Expanding on this foundation, this paper employs a model-free goal-conditioned RL approach to enable fast adaptation for GR across various changing tasks.
GRAML: Dynamic Goal Recognition As Metric Learning
May 06, 2025Goal Recognition (GR) is the problem of recognizing an agent's objectives based on observed actions. Recent data-driven approaches for GR alleviate the need for costly, manually crafted domain models. However, these approaches can only reason about a pre-defined set of goals, and time-consuming training is needed for new emerging goals. To keep this model-learning automated while enabling quick adaptation to new goals, this paper introduces GRAML: Goal Recognition As Metric Learning. GRAML uses a Siamese network to treat GR as a deep metric learning task, employing an RNN that learns a metric over an embedding space, where the embeddings for observation traces leading to different goals are distant, and embeddings of traces leading to the same goals are close. This metric is especially useful when adapting to new goals, even if given just one example observation trace per goal. Evaluated on a versatile set of environments, GRAML shows speed, flexibility, and runtime improvements over the state-of-the-art GR while maintaining accurate recognition.
Gap the (Theory of) Mind: Sharing Beliefs About Teammates' Goals Boosts Collaboration Perception, Not Performance
May 06, 2025
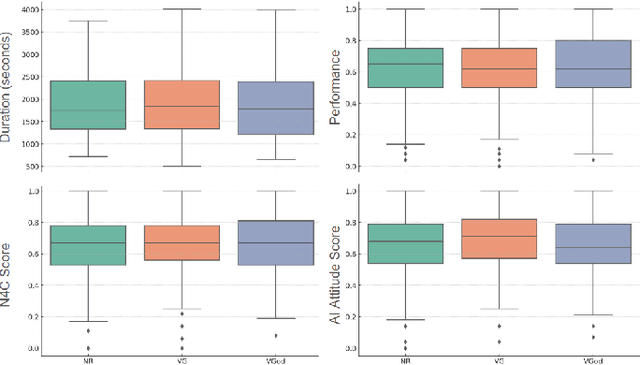
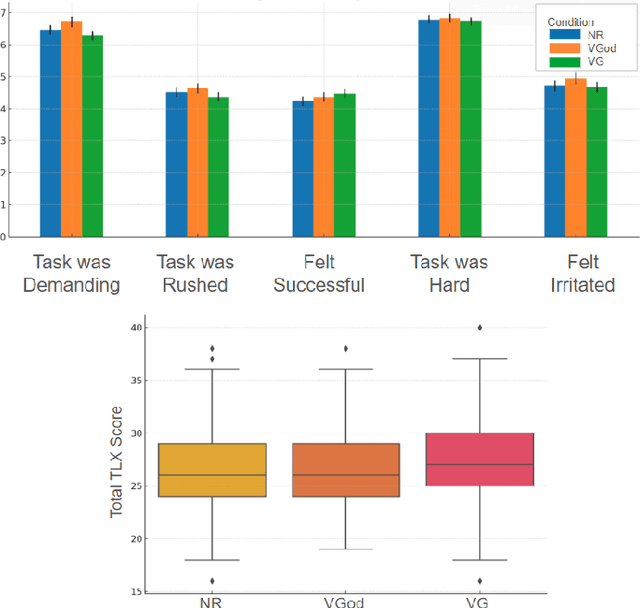
In human-agent teams, openly sharing goals is often assumed to enhance planning, collaboration, and effectiveness. However, direct communication of these goals is not always feasible, requiring teammates to infer their partner's intentions through actions. Building on this, we investigate whether an AI agent's ability to share its inferred understanding of a human teammate's goals can improve task performance and perceived collaboration. Through an experiment comparing three conditions-no recognition (NR), viable goals (VG), and viable goals on-demand (VGod) - we find that while goal-sharing information did not yield significant improvements in task performance or overall satisfaction scores, thematic analysis suggests that it supported strategic adaptations and subjective perceptions of collaboration. Cognitive load assessments revealed no additional burden across conditions, highlighting the challenge of balancing informativeness and simplicity in human-agent interactions. These findings highlight the nuanced trade-off of goal-sharing: while it fosters trust and enhances perceived collaboration, it can occasionally hinder objective performance gains.
Proceedings of 1st Workshop on Advancing Artificial Intelligence through Theory of Mind
Apr 28, 2025



This volume includes a selection of papers presented at the Workshop on Advancing Artificial Intelligence through Theory of Mind held at AAAI 2025 in Philadelphia US on 3rd March 2025. The purpose of this volume is to provide an open access and curated anthology for the ToM and AI research community.