 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Planning for Optimal Data Pipeline Instantiation
Mar 16, 2025
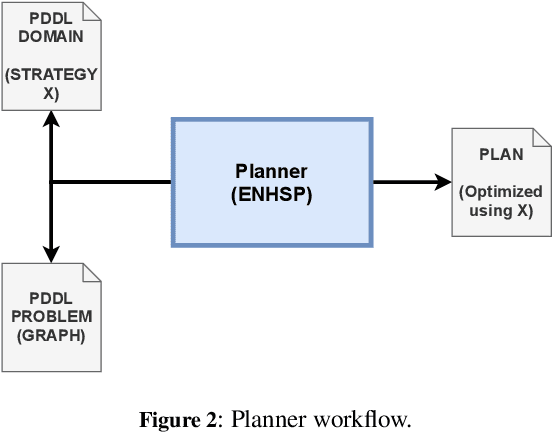


Data pipeline frameworks provide abstractions for implementing sequences of data-intensive transformation operators, automating the deployment and execution of such transformations in a cluster. Deploying a data pipeline, however, requires computing resources to be allocated in a data center, ideally minimizing the overhead for communicating data and executing operators in the pipeline while considering each operator's execution requirements. In this paper, we model the problem of optimal data pipeline deployment as planning with action costs, where we propose heuristics aiming to minimize total execution time. Experimental results indicate that the heuristics can outperform the baseline deployment and that a heuristic based on connections outperforms other strategies.
Intention Recognition in Real-Time Interactive Navigation Maps
Feb 24, 2025In this demonstration, we develop IntentRec4Maps, a system to recognise users' intentions in interactive maps for real-world navigation. IntentRec4Maps uses the Google Maps Platform as the real-world interactive map, and a very effective approach for recognising users' intentions in real-time. We showcase the recognition process of IntentRec4Maps using two different Path-Planners and a Large Language Model (LLM). GitHub: https://github.com/PeijieZ/IntentRec4Maps
Goal Recognition using Actor-Critic Optimization
Dec 31, 2024Goal Recognition aims to infer an agent's goal from a sequence of observations. Existing approaches often rely on manually engineered domains and discrete representations. Deep Recognition using Actor-Critic Optimization (DRACO) is a novel approach based on deep reinforcement learning that overcomes these limitations by providing two key contributions. First, it is the first goal recognition algorithm that learns a set of policy networks from unstructured data and uses them for inference. Second, DRACO introduces new metrics for assessing goal hypotheses through continuous policy representations. DRACO achieves state-of-the-art performance for goal recognition in discrete settings while not using the structured inputs used by existing approaches. Moreover, it outperforms these approaches in more challenging, continuous settings at substantially reduced costs in both computing and memory. Together, these results showcase the robustness of the new algorithm, bridging traditional goal recognition and deep reinforcement learning.
Explorative Imitation Learning: A Path Signature Approach for Continuous Environments
Jul 05, 2024



Some imitation learning methods combine behavioural cloning with self-supervision to infer actions from state pairs. However, most rely on a large number of expert trajectories to increase generalisation and human intervention to capture key aspects of the problem, such as domain constraints. In this paper, we propose Continuous Imitation Learning from Observation (CILO), a new method augmenting imitation learning with two important features: (i) exploration, allowing for more diverse state transitions, requiring less expert trajectories and resulting in fewer training iterations; and (ii) path signatures, allowing for automatic encoding of constraints, through the creation of non-parametric representations of agents and expert trajectories. We compared CILO with a baseline and two leading imitation learning methods in five environments. It had the best overall performance of all methods in all environments, outperforming the expert in two of them.
Goal Recognition via Linear Programming
Apr 11, 2024Goal Recognition is the task by which an observer aims to discern the goals that correspond to plans that comply with the perceived behavior of subject agents given as a sequence of observations. Research on Goal Recognition as Planning encompasses reasoning about the model of a planning task, the observations, and the goals using planning techniques, resulting in very efficient recognition approaches. In this article, we design novel recognition approaches that rely on the Operator-Counting framework, proposing new constraints, and analyze their constraints' properties both theoretically and empirically. The Operator-Counting framework is a technique that efficiently computes heuristic estimates of cost-to-goal using Integer/Linear Programming (IP/LP). In the realm of theory, we prove that the new constraints provide lower bounds on the cost of plans that comply with observations. We also provide an extensive empirical evaluation to assess how the new constraints improve the quality of the solution, and we found that they are especially informed in deciding which goals are unlikely to be part of the solution. Our novel recognition approaches have two pivotal advantages: first, they employ new IP/LP constraints for efficiently recognizing goals; second, we show how the new IP/LP constraints can improve the recognition of goals under both partial and noisy observability.
Online Goal Recognition in Discrete and Continuous Domains Using a Vectorial Representation
Jul 15, 2023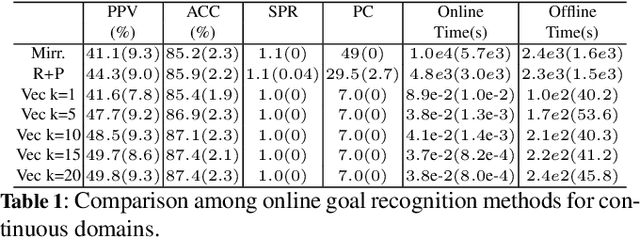

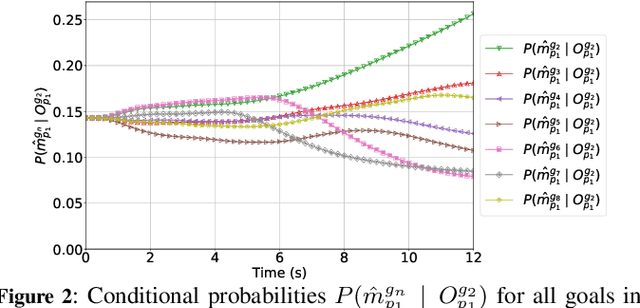
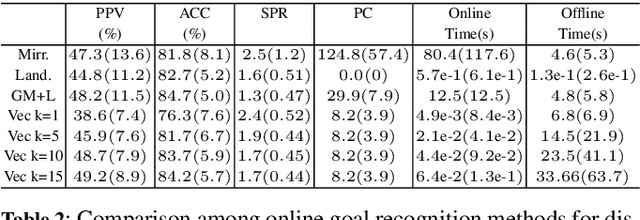
While recent work on online goal recognition efficiently infers goals under low observability, comparatively less work focuses on online goal recognition that works in both discrete and continuous domains. Online goal recognition approaches often rely on repeated calls to the planner at each new observation, incurring high computational costs. Recognizing goals online in continuous space quickly and reliably is critical for any trajectory planning problem since the real physical world is fast-moving, e.g. robot applications. We develop an efficient method for goal recognition that relies either on a single call to the planner for each possible goal in discrete domains or a simplified motion model that reduces the computational burden in continuous ones. The resulting approach performs the online component of recognition orders of magnitude faster than the current state of the art, making it the first online method effectively usable for robotics applications that require sub-second recognition.
Temporally Extended Goal Recognition in Fully Observable Non-Deterministic Domain Models
Jun 14, 2023Goal Recognition is the task of discerning the correct intended goal that an agent aims to achieve, given a set of goal hypotheses, a domain model, and a sequence of observations (i.e., a sample of the plan executed in the environment). Existing approaches assume that goal hypotheses comprise a single conjunctive formula over a single final state and that the environment dynamics are deterministic, preventing the recognition of temporally extended goals in more complex settings. In this paper, we expand goal recognition to temporally extended goals in Fully Observable Non-Deterministic (FOND) planning domain models, focusing on goals on finite traces expressed in Linear Temporal Logic (LTLf) and Pure Past Linear Temporal Logic (PLTLf). We develop the first approach capable of recognizing goals in such settings and evaluate it using different LTLf and PLTLf goals over six FOND planning domain models. Empirical results show that our approach is accurate in recognizing temporally extended goals in different recognition settings.
Self-Supervised Adversarial Imitation Learning
Apr 21, 2023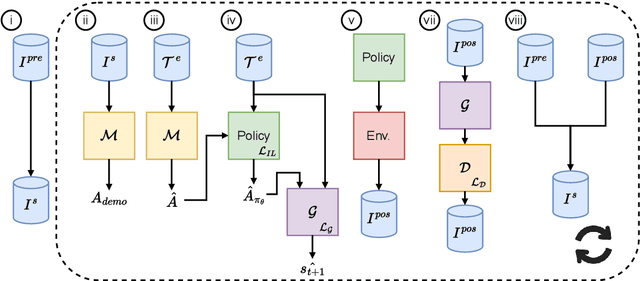
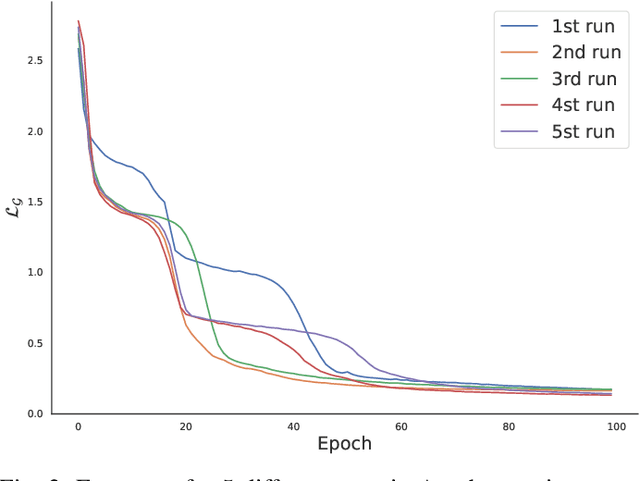
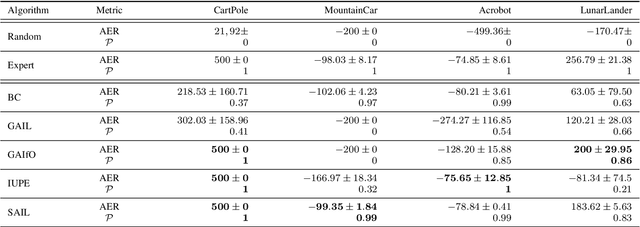
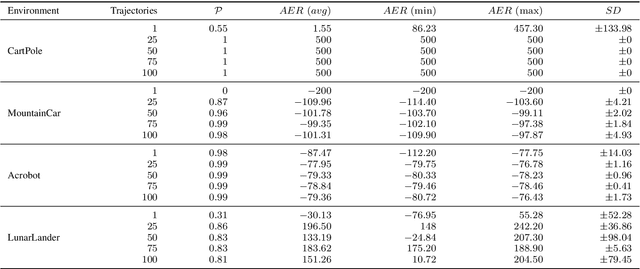
Behavioural cloning is an imitation learning technique that teaches an agent how to behave via expert demonstrations. Recent approaches use self-supervision of fully-observable unlabelled snapshots of the states to decode state pairs into actions. However, the iterative learning scheme employed by these techniques is prone to get trapped into bad local minima. Previous work uses goal-aware strategies to solve this issue. However, this requires manual intervention to verify whether an agent has reached its goal. We address this limitation by incorporating a discriminator into the original framework, offering two key advantages and directly solving a learning problem previous work had. First, it disposes of the manual intervention requirement. Second, it helps in learning by guiding function approximation based on the state transition of the expert's trajectories. Third, the discriminator solves a learning issue commonly present in the policy model, which is to sometimes perform a `no action' within the environment until the agent finally halts.
HyperTensioN and Total-order Forward Decomposition optimizations
Jul 01, 2022


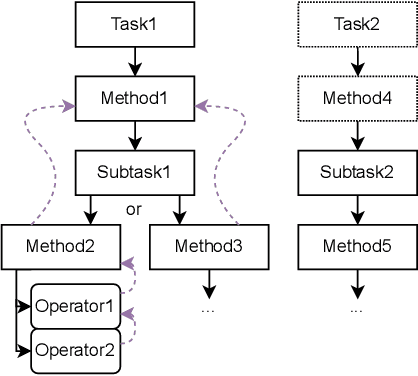
Hierarchical Task Networks (HTN) planners generate plans using a decomposition process with extra domain knowledge to guide search towards a planning task. While domain experts develop HTN descriptions, they may repeatedly describe the same preconditions, or methods that are rarely used or possible to be decomposed. By leveraging a three-stage compiler design we can easily support more language descriptions and preprocessing optimizations that when chained can greatly improve runtime efficiency in such domains. In this paper we evaluate such optimizations with the HyperTensioN HTN planner, used in the HTN IPC 2020.
Goal Recognition as Reinforcement Learning
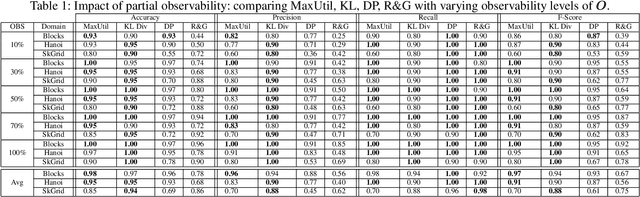
Feb 13, 2022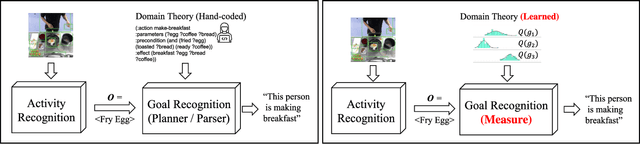
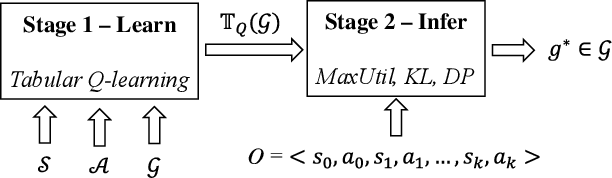

Most approaches for goal recognition rely on specifications of the possible dynamics of the actor in the environment when pursuing a goal. These specifications suffer from two key issues. First, encoding these dynamics requires careful design by a domain expert, which is often not robust to noise at recognition time. Second, existing approaches often need costly real-time computations to reason about the likelihood of each potential goal. In this paper, we develop a framework that combines model-free reinforcement learning and goal recognition to alleviate the need for careful, manual domain design, and the need for costly online executions. This framework consists of two main stages: Offline learning of policies or utility functions for each potential goal, and online inference. We provide a first instance of this framework using tabular Q-learning for the learning stage, as well as three measures that can be used to perform the inference stage. The resulting instantiation achieves state-of-the-art performance against goal recognizers on standard evaluation domains and superior performance in noisy environments.