 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness Aware Reinforcement Learning via Proximal Policy Optimization
Feb 06, 2025


Fairness in multi-agent systems (MAS) focuses on equitable reward distribution among agents in scenarios involving sensitive attributes such as race, gender, or socioeconomic status. This paper introduces fairness in Proximal Policy Optimization (PPO) with a penalty term derived from demographic parity, counterfactual fairness, and conditional statistical parity. The proposed method balances reward maximisation with fairness by integrating two penalty components: a retrospective component that minimises disparities in past outcomes and a prospective component that ensures fairness in future decision-making. We evaluate our approach in the Allelopathic Harvest game, a cooperative and competitive MAS focused on resource collection, where some agents possess a sensitive attribute. Experiments demonstrate that fair-PPO achieves fairer policies across all fairness metrics than classic PPO. Fairness comes at the cost of reduced rewards, namely the Price of Fairness, although agents with and without the sensitive attribute renounce comparable amounts of rewards. Additionally, the retrospective and prospective penalties effectively change the agents' behaviour and improve fairness. These findings underscore the potential of fair-PPO to address fairness challenges in MAS.
Using Protected Attributes to Consider Fairness in Multi-Agent Systems
Oct 16, 2024Fairness in Multi-Agent Systems (MAS) has been extensively studied, particularly in reward distribution among agents in scenarios such as goods allocation, resource division, lotteries, and bargaining systems. Fairness in MAS depends on various factors, including the system's governing rules, the behaviour of the agents, and their characteristics. Yet, fairness in human society often involves evaluating disparities between disadvantaged and privileged groups, guided by principles of Equality, Diversity, and Inclusion (EDI). Taking inspiration from the work on algorithmic fairness, which addresses bias in machine learning-based decision-making, we define protected attributes for MAS as characteristics that should not disadvantage an agent in terms of its expected rewards. We adapt fairness metrics from the algorithmic fairness literature -- namely, demographic parity, counterfactual fairness, and conditional statistical parity -- to the multi-agent setting, where self-interested agents interact within an environment. These metrics allow us to evaluate the fairness of MAS, with the ultimate aim of designing MAS that do not disadvantage agents based on protected attributes.
Explorative Imitation Learning: A Path Signature Approach for Continuous Environments
Jul 05, 2024



Some imitation learning methods combine behavioural cloning with self-supervision to infer actions from state pairs. However, most rely on a large number of expert trajectories to increase generalisation and human intervention to capture key aspects of the problem, such as domain constraints. In this paper, we propose Continuous Imitation Learning from Observation (CILO), a new method augmenting imitation learning with two important features: (i) exploration, allowing for more diverse state transitions, requiring less expert trajectories and resulting in fewer training iterations; and (ii) path signatures, allowing for automatic encoding of constraints, through the creation of non-parametric representations of agents and expert trajectories. We compared CILO with a baseline and two leading imitation learning methods in five environments. It had the best overall performance of all methods in all environments, outperforming the expert in two of them.
Imitation Learning: A Survey of Learning Methods, Environments and Metrics
Apr 30, 2024
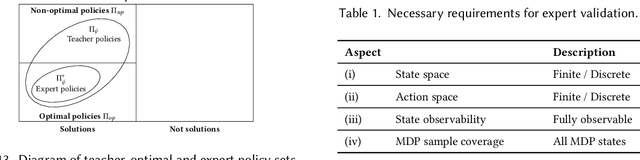

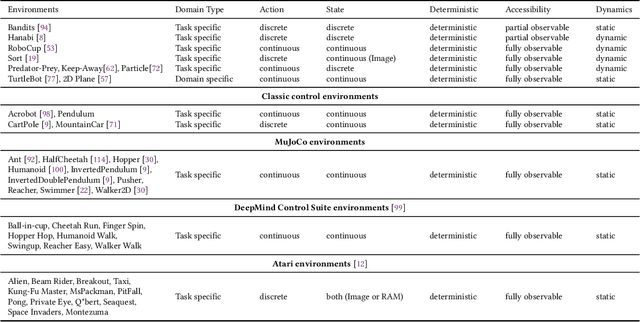
Imitation learning is an approach in which an agent learns how to execute a task by trying to mimic how one or more teachers perform it. This learning approach offers a compromise between the time it takes to learn a new task and the effort needed to collect teacher samples for the agent. It achieves this by balancing learning from the teacher, who has some information on how to perform the task, and deviating from their examples when necessary, such as states not present in the teacher samples. Consequently, the field of imitation learning has received much attention from researchers in recent years, resulting in many new methods and applications. However, with this increase in published work and past surveys focusing mainly on methodology, a lack of standardisation became more prominent in the field. This non-standardisation is evident in the use of environments, which appear in no more than two works, and evaluation processes, such as qualitative analysis, that have become rare in current literature. In this survey, we systematically review current imitation learning literature and present our findings by (i) classifying imitation learning techniques, environments and metrics by introducing novel taxonomies; (ii) reflecting on main problems from the literature; and (iii) presenting challenges and future directions for researchers.
Visual Analytics for Fine-grained Text Classification Models and Datasets
Mar 21, 2024In natural language processing (NLP), text classification tasks are increasingly fine-grained, as datasets are fragmented into a larger number of classes that are more difficult to differentiate from one another. As a consequence, the semantic structures of datasets have become more complex, and model decisions more difficult to explain. Existing tools, suited for coarse-grained classification, falter under these additional challenges. In response to this gap, we worked closely with NLP domain experts in an iterative design-and-evaluation process to characterize and tackle the growing requirements in their workflow of developing fine-grained text classification models. The result of this collaboration is the development of SemLa, a novel visual analytics system tailored for 1) dissecting complex semantic structures in a dataset when it is spatialized in model embedding space, and 2) visualizing fine-grained nuances in the meaning of text samples to faithfully explain model reasoning. This paper details the iterative design study and the resulting innovations featured in SemLa. The final design allows contrastive analysis at different levels by unearthing lexical and conceptual patterns including biases and artifacts in data. Expert feedback on our final design and case studies confirm that SemLa is a useful tool for supporting model validation and debugging as well as data annotation.
Imitation Learning Datasets: A Toolkit For Creating Datasets, Training Agents and Benchmarking
Mar 01, 2024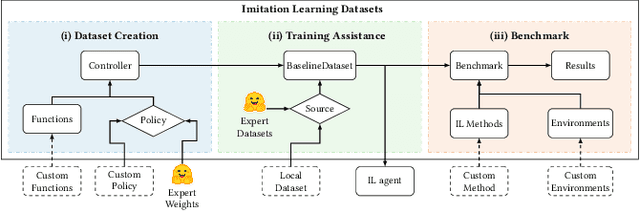
Imitation learning field requires expert data to train agents in a task. Most often, this learning approach suffers from the absence of available data, which results in techniques being tested on its dataset. Creating datasets is a cumbersome process requiring researchers to train expert agents from scratch, record their interactions and test each benchmark method with newly created data. Moreover, creating new datasets for each new technique results in a lack of consistency in the evaluation process since each dataset can drastically vary in state and action distribution. In response, this work aims to address these issues by creating Imitation Learning Datasets, a toolkit that allows for: (i) curated expert policies with multithreaded support for faster dataset creation; (ii) readily available datasets and techniques with precise measurements; and (iii) sharing implementations of common imitation learning techniques. Demonstration link: https://nathangavenski.github.io/#/il-datasets-video
AgentCoder: Multi-Agent-based Code Generation with Iterative Testing and Optimisation
Dec 20, 2023



The advancement of natural language processing (NLP) has been significantly boosted by the development of transformer-based large language models (LLMs). These models have revolutionized NLP tasks, particularly in code generation, aiding developers in creating software with enhanced efficiency. Despite their advancements, challenges in balancing code snippet generation with effective test case generation and execution persist. To address these issues, this paper introduces Multi-Agent Assistant Code Generation (AgentCoder), a novel solution comprising a multi-agent framework with specialized agents: the programmer agent, the test designer agent, and the test executor agent. During the coding procedure, the programmer agent will focus on the code generation and refinement based on the test executor agent's feedback. The test designer agent will generate test cases for the generated code, and the test executor agent will run the code with the test cases and write the feedback to the programmer. This collaborative system ensures robust code generation, surpassing the limitations of single-agent models and traditional methodologies. Our extensive experiments on 9 code generation models and 12 enhancement approaches showcase AgentCoder's superior performance over existing code generation models and prompt engineering techniques across various benchmarks. For example, AgentCoder achieves 77.4% and 89.1% pass@1 in HumanEval-ET and MBPP-ET with GPT-3.5, while SOTA baselines obtain only 69.5% and 63.0%.
Collaborative filtering to capture AI user's preferences as norms
Aug 10, 2023Customising AI technologies to each user's preferences is fundamental to them functioning well. Unfortunately, current methods require too much user involvement and fail to capture their true preferences. In fact, to avoid the nuisance of manually setting preferences, users usually accept the default settings even if these do not conform to their true preferences. Norms can be useful to regulate behaviour and ensure it adheres to user preferences but, while the literature has thoroughly studied norms, most proposals take a formal perspective. Indeed, while there has been some research on constructing norms to capture a user's privacy preferences, these methods rely on domain knowledge which, in the case of AI technologies, is difficult to obtain and maintain. We argue that a new perspective is required when constructing norms, which is to exploit the large amount of preference information readily available from whole systems of users. Inspired by recommender systems, we believe that collaborative filtering can offer a suitable approach to identifying a user's norm preferences without excessive user involvement.
Predicting Privacy Preferences for Smart Devices as Norms
Feb 21, 2023Smart devices, such as smart speakers, are becoming ubiquitous, and users expect these devices to act in accordance with their preferences. In particular, since these devices gather and manage personal data, users expect them to adhere to their privacy preferences. However, the current approach of gathering these preferences consists in asking the users directly, which usually triggers automatic responses failing to capture their true preferences. In response, in this paper we present a collaborative filtering approach to predict user preferences as norms. These preference predictions can be readily adopted or can serve to assist users in determining their own preferences. Using a dataset of privacy preferences of smart assistant users, we test the accuracy of our predictions.