 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStereoVLA: Enhancing Vision-Language-Action Models with Stereo Vision
Dec 26, 2025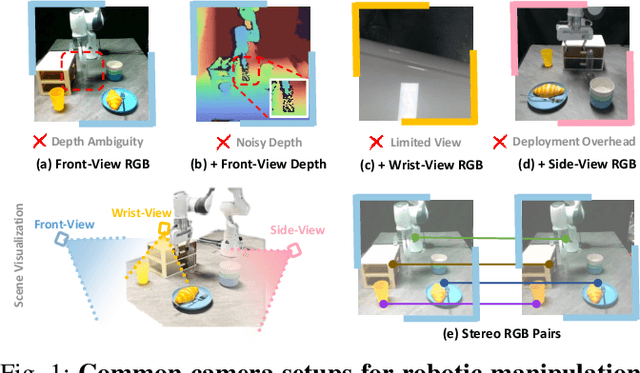
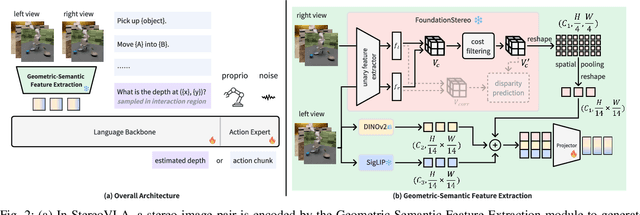
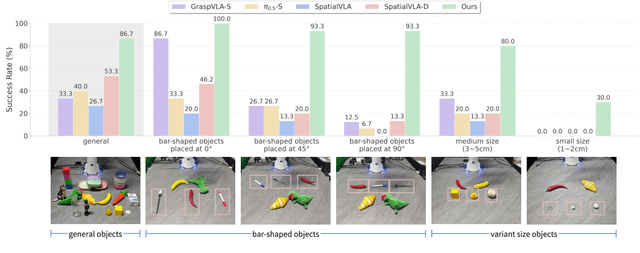
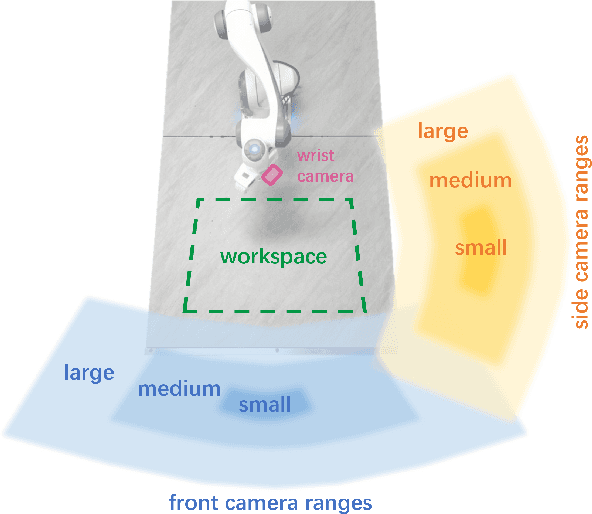
Stereo cameras closely mimic human binocular vision, providing rich spatial cues critical for precise robotic manipulation. Despite their advantage, the adoption of stereo vision in vision-language-action models (VLAs) remains underexplored. In this work, we present StereoVLA, a VLA model that leverages rich geometric cues from stereo vision. We propose a novel Geometric-Semantic Feature Extraction module that utilizes vision foundation models to extract and fuse two key features: 1) geometric features from subtle stereo-view differences for spatial perception; 2) semantic-rich features from the monocular view for instruction following. Additionally, we propose an auxiliary Interaction-Region Depth Estimation task to further enhance spatial perception and accelerate model convergence. Extensive experiments show that our approach outperforms baselines by a large margin in diverse tasks under the stereo setting and demonstrates strong robustness to camera pose variations.
LEED: A Highly Efficient and Scalable LLM-Empowered Expert Demonstrations Framework for Multi-Agent Reinforcement Learning
Sep 18, 2025Multi-agent reinforcement learning (MARL) holds substantial promise for intelligent decision-making in complex environments. However, it suffers from a coordination and scalability bottleneck as the number of agents increases. To address these issues, we propose the LLM-empowered expert demonstrations framework for multi-agent reinforcement learning (LEED). LEED consists of two components: a demonstration generation (DG) module and a policy optimization (PO) module. Specifically, the DG module leverages large language models to generate instructions for interacting with the environment, thereby producing high-quality demonstrations. The PO module adopts a decentralized training paradigm, where each agent utilizes the generated demonstrations to construct an expert policy loss, which is then integrated with its own policy loss. This enables each agent to effectively personalize and optimize its local policy based on both expert knowledge and individual experience. Experimental results show that LEED achieves superior sample efficiency, time efficiency, and robust scalability compared to state-of-the-art baselines.
Sample Efficient Experience Replay in Non-stationary Environments
Sep 18, 2025Reinforcement learning (RL) in non-stationary environments is challenging, as changing dynamics and rewards quickly make past experiences outdated. Traditional experience replay (ER) methods, especially those using TD-error prioritization, struggle to distinguish between changes caused by the agent's policy and those from the environment, resulting in inefficient learning under dynamic conditions. To address this challenge, we propose the Discrepancy of Environment Dynamics (DoE), a metric that isolates the effects of environment shifts on value functions. Building on this, we introduce Discrepancy of Environment Prioritized Experience Replay (DEER), an adaptive ER framework that prioritizes transitions based on both policy updates and environmental changes. DEER uses a binary classifier to detect environment changes and applies distinct prioritization strategies before and after each shift, enabling more sample-efficient learning. Experiments on four non-stationary benchmarks demonstrate that DEER further improves the performance of off-policy algorithms by 11.54 percent compared to the best-performing state-of-the-art ER methods.
EffiBench-X: A Multi-Language Benchmark for Measuring Efficiency of LLM-Generated Code
May 19, 2025
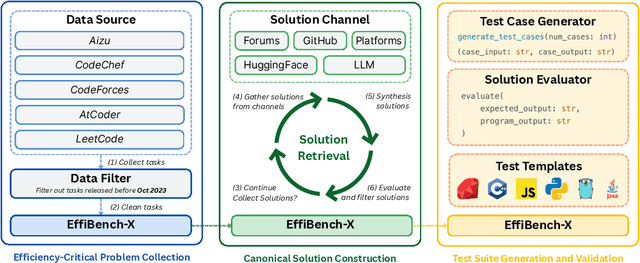


Existing code generation benchmarks primarily evaluate functional correctness, with limited focus on code efficiency and often restricted to a single language like Python. To address this gap, we introduce EffiBench-X, the first multi-language benchmark designed to measure the efficiency of LLM-generated code. EffiBench-X supports Python, C++, Java, JavaScript, Ruby, and Golang. It comprises competitive programming tasks with human-expert solutions as efficiency baselines. Evaluating state-of-the-art LLMs on EffiBench-X reveals that while models generate functionally correct code, they consistently underperform human experts in efficiency. Even the most efficient LLM-generated solutions (Qwen3-32B) achieve only around \textbf{62\%} of human efficiency on average, with significant language-specific variations. LLMs show better efficiency in Python, Ruby, and JavaScript than in Java, C++, and Golang. For instance, DeepSeek-R1's Python code is significantly more efficient than its Java code. These results highlight the critical need for research into LLM optimization techniques to improve code efficiency across diverse languages. The dataset and evaluation infrastructure are submitted and available at https://github.com/EffiBench/EffiBench-X.git and https://huggingface.co/datasets/EffiBench/effibench-x.
GraspVLA: a Grasping Foundation Model Pre-trained on Billion-scale Synthetic Action Data
May 06, 2025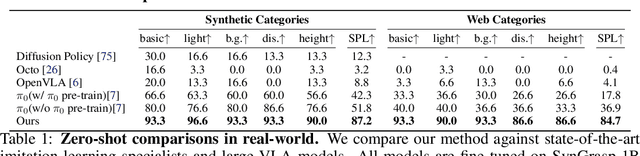



Embodied foundation models are gaining increasing attention for their zero-shot generalization, scalability, and adaptability to new tasks through few-shot post-training. However, existing models rely heavily on real-world data, which is costly and labor-intensive to collect. Synthetic data offers a cost-effective alternative, yet its potential remains largely underexplored. To bridge this gap, we explore the feasibility of training Vision-Language-Action models entirely with large-scale synthetic action data. We curate SynGrasp-1B, a billion-frame robotic grasping dataset generated in simulation with photorealistic rendering and extensive domain randomization. Building on this, we present GraspVLA, a VLA model pretrained on large-scale synthetic action data as a foundational model for grasping tasks. GraspVLA integrates autoregressive perception tasks and flow-matching-based action generation into a unified Chain-of-Thought process, enabling joint training on synthetic action data and Internet semantics data. This design helps mitigate sim-to-real gaps and facilitates the transfer of learned actions to a broader range of Internet-covered objects, achieving open-vocabulary generalization in grasping. Extensive evaluations across real-world and simulation benchmarks demonstrate GraspVLA's advanced zero-shot generalizability and few-shot adaptability to specific human preferences. We will release SynGrasp-1B dataset and pre-trained weights to benefit the community.
State-Aware Perturbation Optimization for Robust Deep Reinforcement Learning
Mar 26, 2025Recently, deep reinforcement learning (DRL) has emerged as a promising approach for robotic control. However, the deployment of DRL in real-world robots is hindered by its sensitivity to environmental perturbations. While existing whitebox adversarial attacks rely on local gradient information and apply uniform perturbations across all states to evaluate DRL robustness, they fail to account for temporal dynamics and state-specific vulnerabilities. To combat the above challenge, we first conduct a theoretical analysis of white-box attacks in DRL by establishing the adversarial victim-dynamics Markov decision process (AVD-MDP), to derive the necessary and sufficient conditions for a successful attack. Based on this, we propose a selective state-aware reinforcement adversarial attack method, named STAR, to optimize perturbation stealthiness and state visitation dispersion. STAR first employs a soft mask-based state-targeting mechanism to minimize redundant perturbations, enhancing stealthiness and attack effectiveness. Then, it incorporates an information-theoretic optimization objective to maximize mutual information between perturbations, environmental states, and victim actions, ensuring a dispersed state-visitation distribution that steers the victim agent into vulnerable states for maximum return reduction. Extensive experiments demonstrate that STAR outperforms state-of-the-art benchmarks.
Robust Deep Reinforcement Learning in Robotics via Adaptive Gradient-Masked Adversarial Attacks
Mar 26, 2025Deep reinforcement learning (DRL) has emerged as a promising approach for robotic control, but its realworld deployment remains challenging due to its vulnerability to environmental perturbations. Existing white-box adversarial attack methods, adapted from supervised learning, fail to effectively target DRL agents as they overlook temporal dynamics and indiscriminately perturb all state dimensions, limiting their impact on long-term rewards. To address these challenges, we propose the Adaptive Gradient-Masked Reinforcement (AGMR) Attack, a white-box attack method that combines DRL with a gradient-based soft masking mechanism to dynamically identify critical state dimensions and optimize adversarial policies. AGMR selectively allocates perturbations to the most impactful state features and incorporates a dynamic adjustment mechanism to balance exploration and exploitation during training. Extensive experiments demonstrate that AGMR outperforms state-of-the-art adversarial attack methods in degrading the performance of the victim agent and enhances the victim agent's robustness through adversarial defense mechanisms.
Rethinking Adversarial Attacks in Reinforcement Learning from Policy Distribution Perspective
Jan 08, 2025Deep Reinforcement Learning (DRL) suffers from uncertainties and inaccuracies in the observation signal in realworld applications. Adversarial attack is an effective method for evaluating the robustness of DRL agents. However, existing attack methods targeting individual sampled actions have limited impacts on the overall policy distribution, particularly in continuous action spaces. To address these limitations, we propose the Distribution-Aware Projected Gradient Descent attack (DAPGD). DAPGD uses distribution similarity as the gradient perturbation input to attack the policy network, which leverages the entire policy distribution rather than relying on individual samples. We utilize the Bhattacharyya distance in DAPGD to measure policy similarity, enabling sensitive detection of subtle but critical differences between probability distributions. Our experiment results demonstrate that DAPGD achieves SOTA results compared to the baselines in three robot navigation tasks, achieving an average 22.03% higher reward drop compared to the best baseline.
Effi-Code: Unleashing Code Efficiency in Language Models
Oct 14, 2024As the use of large language models (LLMs) for code generation becomes more prevalent in software development, it is critical to enhance both the efficiency and correctness of the generated code. Existing methods and models primarily focus on the correctness of LLM-generated code, ignoring efficiency. In this work, we present Effi-Code, an approach to enhancing code generation in LLMs that can improve both efficiency and correctness. We introduce a Self-Optimization process based on Overhead Profiling that leverages open-source LLMs to generate a high-quality dataset of correct and efficient code samples. This dataset is then used to fine-tune various LLMs. Our method involves the iterative refinement of generated code, guided by runtime performance metrics and correctness checks. Extensive experiments demonstrate that models fine-tuned on the Effi-Code show significant improvements in both code correctness and efficiency across task types. For example, the pass@1 of DeepSeek-Coder-6.7B-Instruct generated code increases from \textbf{43.3\%} to \textbf{76.8\%}, and the average execution time for the same correct tasks decreases by \textbf{30.5\%}. Effi-Code offers a scalable and generalizable approach to improving code generation in AI systems, with potential applications in software development, algorithm design, and computational problem-solving. The source code of Effi-Code was released in \url{https://github.com/huangd1999/Effi-Code}.
Towards Synergistic, Generalized, and Efficient Dual-System for Robotic Manipulation
Oct 10, 2024

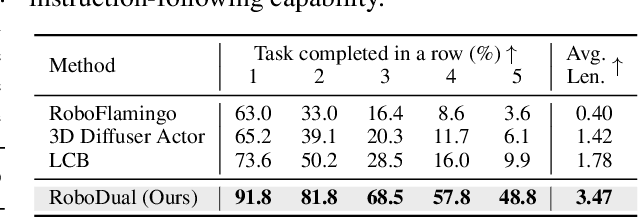

The increasing demand for versatile robotic systems to operate in diverse and dynamic environments has emphasized the importance of a generalist policy, which leverages a large cross-embodiment data corpus to facilitate broad adaptability and high-level reasoning. However, the generalist would struggle with inefficient inference and cost-expensive training. The specialist policy, instead, is curated for specific domain data and excels at task-level precision with efficiency. Yet, it lacks the generalization capacity for a wide range of applications. Inspired by these observations, we introduce RoboDual, a synergistic dual-system that supplements the merits of both generalist and specialist policy. A diffusion transformer-based specialist is devised for multi-step action rollouts, exquisitely conditioned on the high-level task understanding and discretized action output of a vision-language-action (VLA) based generalist. Compared to OpenVLA, RoboDual achieves 26.7% improvement in real-world setting and 12% gain on CALVIN by introducing a specialist policy with merely 20M trainable parameters. It maintains strong performance with 5% of demonstration data only, and enables a 3.8 times higher control frequency in real-world deployment. Code would be made publicly available. Our project page is hosted at: https://opendrivelab.com/RoboDual/