 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentization of Digital Assets for the Agentic Web: Concepts, Techniques, and Benchmark
Apr 05, 2026Agentic Web, as a new paradigm that redefines the internet through autonomous, goal-driven interactions, plays an important role in group intelligence. As the foundational semantic primitives of the Agentic Web, digital assets encapsulate interactive web elements into agents, which expand the capacities and coverage of agents in agentic web. The lack of automated methodologies for agent generation limits the wider usage of digital assets and the advancement of the Agentic Web. In this paper, we first formalize these challenges by strictly defining the A2A-Agentization process, decomposing it into critical stages and identifying key technical hurdles on top of the A2A protocol. Based on this framework, we develop an Agentization Agent to agentize digital assets for the Agentic Web. To rigorously evaluate this capability, we propose A2A-Agentization Bench, the first benchmark explicitly designed to evaluate agentization quality in terms of fidelity and interoperability. Our experiments demonstrate that our approach effectively activates the functional capabilities of digital assets and enables interoperable A2A multi-agent collaboration. We believe this work will further facilitate scalable and standardized integration of digital assets into the Agentic Web ecosystem.
BOAD: Discovering Hierarchical Software Engineering Agents via Bandit Optimization
Dec 29, 2025Large language models (LLMs) have shown strong reasoning and coding capabilities, yet they struggle to generalize to real-world software engineering (SWE) problems that are long-horizon and out of distribution. Existing systems often rely on a single agent to handle the entire workflow-interpreting issues, navigating large codebases, and implementing fixes-within one reasoning chain. Such monolithic designs force the model to retain irrelevant context, leading to spurious correlations and poor generalization. Motivated by how human engineers decompose complex problems, we propose structuring SWE agents as orchestrators coordinating specialized sub-agents for sub-tasks such as localization, editing, and validation. The challenge lies in discovering effective hierarchies automatically: as the number of sub-agents grows, the search space becomes combinatorial, and it is difficult to attribute credit to individual sub-agents within a team. We address these challenges by formulating hierarchy discovery as a multi-armed bandit (MAB) problem, where each arm represents a candidate sub-agent and the reward measures its helpfulness when collaborating with others. This framework, termed Bandit Optimization for Agent Design (BOAD), enables efficient exploration of sub-agent designs under limited evaluation budgets. On SWE-bench-Verified, BOAD outperforms single-agent and manually designed multi-agent systems. On SWE-bench-Live, featuring more recent and out-of-distribution issues, our 36B system ranks second on the leaderboard at the time of evaluation, surpassing larger models such as GPT-4 and Claude. These results demonstrate that automatically discovered hierarchical multi-agent systems significantly improve generalization on challenging long-horizon SWE tasks. Code is available at https://github.com/iamxjy/BOAD-SWE-Agent.
Tailored Primitive Initialization is the Secret Key to Reinforcement Learning
Nov 16, 2025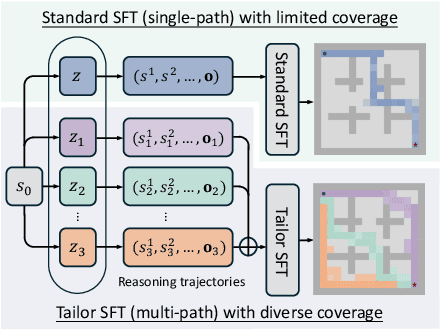

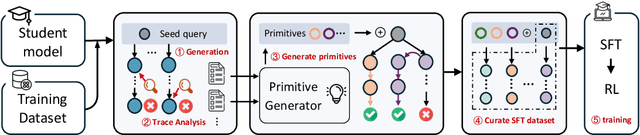
Reinforcement learning (RL) has emerged as a powerful paradigm for enhancing the reasoning capabilities of large language models (LLMs). While RL has demonstrated substantial performance gains, it still faces key challenges, including low sampling efficiency and a strong dependence on model initialization: some models achieve rapid improvements with minimal RL steps, while others require significant training data to make progress. In this work, we investigate these challenges through the lens of reasoning token coverage and argue that initializing LLMs with diverse, high-quality reasoning primitives is essential for achieving stable and sample-efficient RL training. We propose Tailor, a finetuning pipeline that automatically discovers and curates novel reasoning primitives, thereby expanding the coverage of reasoning-state distributions before RL. Extensive experiments on mathematical and logical reasoning benchmarks demonstrate that Tailor generates more diverse and higher-quality warm-start data, resulting in higher downstream RL performance.
Satori-SWE: Evolutionary Test-Time Scaling for Sample-Efficient Software Engineering
May 29, 2025
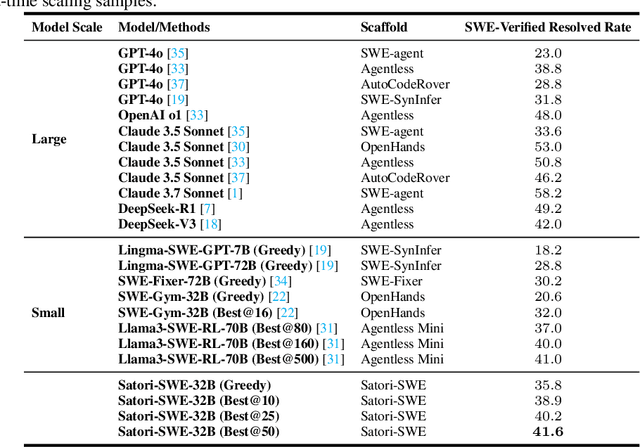
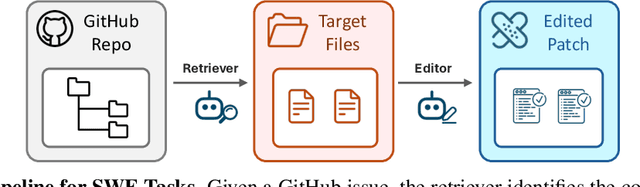

Language models (LMs) perform well on standardized coding benchmarks but struggle with real-world software engineering tasks such as resolving GitHub issues in SWE-Bench, especially when model parameters are less than 100B. While smaller models are preferable in practice due to their lower computational cost, improving their performance remains challenging. Existing approaches primarily rely on supervised fine-tuning (SFT) with high-quality data, which is expensive to curate at scale. An alternative is test-time scaling: generating multiple outputs, scoring them using a verifier, and selecting the best one. Although effective, this strategy often requires excessive sampling and costly scoring, limiting its practical application. We propose Evolutionary Test-Time Scaling (EvoScale), a sample-efficient method that treats generation as an evolutionary process. By iteratively refining outputs via selection and mutation, EvoScale shifts the output distribution toward higher-scoring regions, reducing the number of samples needed to find correct solutions. To reduce the overhead from repeatedly sampling and selection, we train the model to self-evolve using reinforcement learning (RL). Rather than relying on external verifiers at inference time, the model learns to self-improve the scores of its own generations across iterations. Evaluated on SWE-Bench-Verified, EvoScale enables our 32B model, Satori-SWE-32B, to match or exceed the performance of models with over 100B parameters while using a few samples. Code, data, and models will be fully open-sourced.
Satori: Reinforcement Learning with Chain-of-Action-Thought Enhances LLM Reasoning via Autoregressive Search
Feb 04, 2025



Large language models (LLMs) have demonstrated remarkable reasoning capabilities across diverse domains. Recent studies have shown that increasing test-time computation enhances LLMs' reasoning capabilities. This typically involves extensive sampling at inference time guided by an external LLM verifier, resulting in a two-player system. Despite external guidance, the effectiveness of this system demonstrates the potential of a single LLM to tackle complex tasks. Thus, we pose a new research problem: Can we internalize the searching capabilities to fundamentally enhance the reasoning abilities of a single LLM? This work explores an orthogonal direction focusing on post-training LLMs for autoregressive searching (i.e., an extended reasoning process with self-reflection and self-exploration of new strategies). To achieve this, we propose the Chain-of-Action-Thought (COAT) reasoning and a two-stage training paradigm: 1) a small-scale format tuning stage to internalize the COAT reasoning format and 2) a large-scale self-improvement stage leveraging reinforcement learning. Our approach results in Satori, a 7B LLM trained on open-source models and data. Extensive empirical evaluations demonstrate that Satori achieves state-of-the-art performance on mathematical reasoning benchmarks while exhibits strong generalization to out-of-domain tasks. Code, data, and models will be fully open-sourced.
SailCompass: Towards Reproducible and Robust Evaluation for Southeast Asian Languages
Dec 02, 2024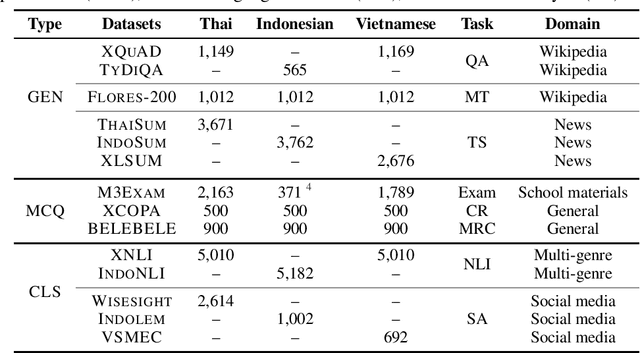
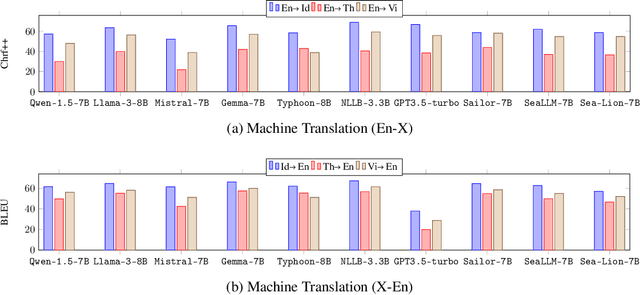
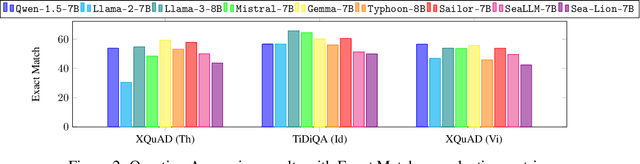
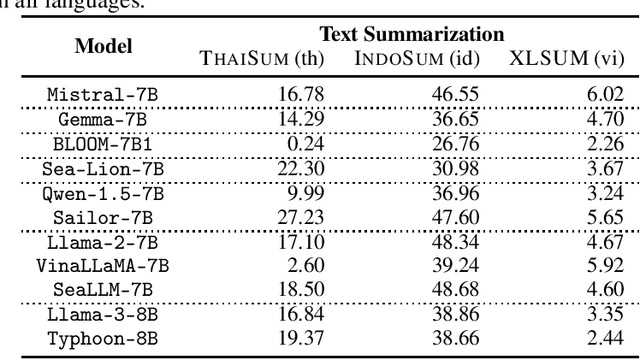
In this paper, we introduce SailCompass, a reproducible and robust evaluation benchmark for assessing Large Language Models (LLMs) on Southeast Asian Languages (SEA). SailCompass encompasses three main SEA languages, eight primary tasks including 14 datasets covering three task types (generation, multiple-choice questions, and classification). To improve the robustness of the evaluation approach, we explore different prompt configurations for multiple-choice questions and leverage calibrations to improve the faithfulness of classification tasks. With SailCompass, we derive the following findings: (1) SEA-specialized LLMs still outperform general LLMs, although the gap has narrowed; (2) A balanced language distribution is important for developing better SEA-specialized LLMs; (3) Advanced prompting techniques (e.g., calibration, perplexity-based ranking) are necessary to better utilize LLMs. All datasets and evaluation scripts are public.
Scaling up Masked Diffusion Models on Text
Oct 24, 2024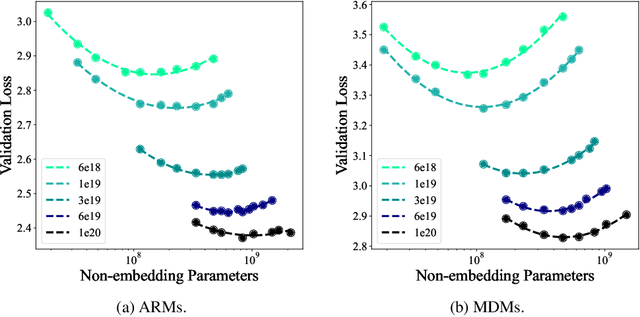

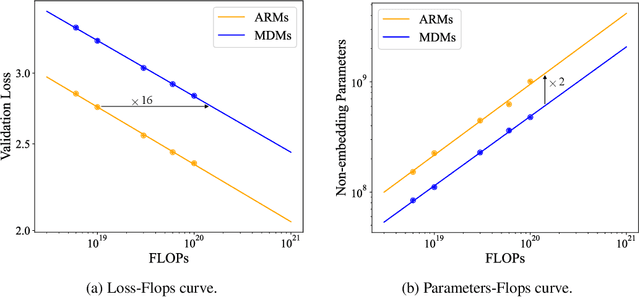

Masked diffusion models (MDMs) have shown promise in language modeling, yet their scalability and effectiveness in core language tasks, such as text generation and language understanding, remain underexplored. This paper establishes the first scaling law for MDMs, demonstrating a scaling rate comparable to autoregressive models (ARMs) and a relatively small compute gap. Motivated by their scalability, we train a family of MDMs with up to 1.1 billion (B) parameters to systematically evaluate their performance against ARMs of comparable or larger sizes. Fully leveraging the probabilistic formulation of MDMs, we propose a simple yet effective \emph{unsupervised classifier-free guidance} that effectively exploits large-scale unpaired data, boosting performance for conditional inference. In language understanding, a 1.1B MDM shows competitive results, outperforming the larger 1.5B GPT-2 model on four out of eight zero-shot benchmarks. In text generation, MDMs provide a flexible trade-off compared to ARMs utilizing KV-cache: MDMs match the performance of ARMs while being 1.4 times faster, or achieve higher quality than ARMs at a higher computational cost. Moreover, MDMs address challenging tasks for ARMs by effectively handling bidirectional reasoning and adapting to temporal shifts in data. Notably, a 1.1B MDM breaks the \emph{reverse curse} encountered by much larger ARMs with significantly more data and computation, such as Llama-2 (13B) and GPT-3 (175B). Our code is available at \url{https://github.com/ML-GSAI/SMDM}.
Effi-Code: Unleashing Code Efficiency in Language Models
Oct 14, 2024



As the use of large language models (LLMs) for code generation becomes more prevalent in software development, it is critical to enhance both the efficiency and correctness of the generated code. Existing methods and models primarily focus on the correctness of LLM-generated code, ignoring efficiency. In this work, we present Effi-Code, an approach to enhancing code generation in LLMs that can improve both efficiency and correctness. We introduce a Self-Optimization process based on Overhead Profiling that leverages open-source LLMs to generate a high-quality dataset of correct and efficient code samples. This dataset is then used to fine-tune various LLMs. Our method involves the iterative refinement of generated code, guided by runtime performance metrics and correctness checks. Extensive experiments demonstrate that models fine-tuned on the Effi-Code show significant improvements in both code correctness and efficiency across task types. For example, the pass@1 of DeepSeek-Coder-6.7B-Instruct generated code increases from \textbf{43.3\%} to \textbf{76.8\%}, and the average execution time for the same correct tasks decreases by \textbf{30.5\%}. Effi-Code offers a scalable and generalizable approach to improving code generation in AI systems, with potential applications in software development, algorithm design, and computational problem-solving. The source code of Effi-Code was released in \url{https://github.com/huangd1999/Effi-Code}.
RegMix: Data Mixture as Regression for Language Model Pre-training
Jul 01, 2024



The data mixture for large language model pre-training significantly impacts performance, yet how to determine an effective mixture remains unclear. We propose RegMix to automatically identify a high-performing data mixture by formulating it as a regression task. RegMix involves training a set of small models with diverse data mixtures and fitting a regression model to predict their performance given their respective mixtures. With the fitted regression model, we simulate the top-ranked mixture and use it to train a large-scale model with orders of magnitude more compute. To empirically validate RegMix, we train 512 models with 1M parameters for 1B tokens of different mixtures to fit the regression model and find the optimal mixture. Using this mixture we train a 1B parameter model for 25B tokens (i.e. 1000x larger and 25x longer) which we find performs best among 64 candidate 1B parameter models with other mixtures. Further, our method demonstrates superior performance compared to human selection and achieves results that match or surpass DoReMi, while utilizing only 10% of the compute budget. Our experiments also show that (1) Data mixtures significantly impact performance with single-task performance variations of up to 14.6%; (2) Web corpora rather than data perceived as high-quality like Wikipedia have the strongest positive correlation with downstream performance; (3) Domains interact in complex ways often contradicting common sense, thus automatic approaches like RegMix are needed; (4) Data mixture effects transcend scaling laws, and our approach captures the complexity by considering all domains together. Our code is available at https://github.com/sail-sg/regmix.
Long Context Transfer from Language to Vision
Jun 24, 2024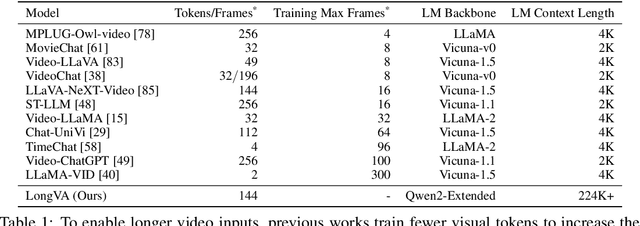
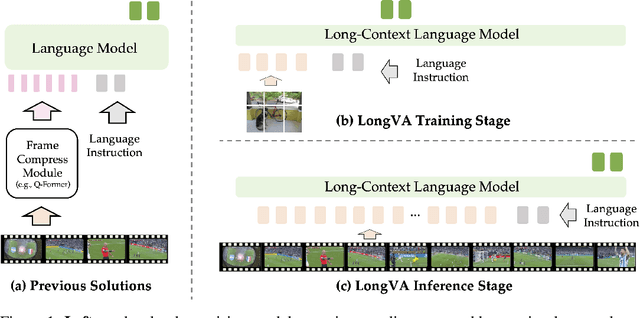


Video sequences offer valuable temporal information, but existing large multimodal models (LMMs) fall short in understanding extremely long videos. Many works address this by reducing the number of visual tokens using visual resamplers. Alternatively, in this paper, we approach this problem from the perspective of the language model. By simply extrapolating the context length of the language backbone, we enable LMMs to comprehend orders of magnitude more visual tokens without any video training. We call this phenomenon long context transfer and carefully ablate its properties. To effectively measure LMMs' ability to generalize to long contexts in the vision modality, we develop V-NIAH (Visual Needle-In-A-Haystack), a purely synthetic long vision benchmark inspired by the language model's NIAH test. Our proposed Long Video Assistant (LongVA) can process 2000 frames or over 200K visual tokens without additional complexities. With its extended context length, LongVA achieves state-of-the-art performance on Video-MME among 7B-scale models by densely sampling more input frames. Our work is open-sourced at https://github.com/EvolvingLMMs-Lab/LongVA.