 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSailCompass: Towards Reproducible and Robust Evaluation for Southeast Asian Languages
Paper and Code
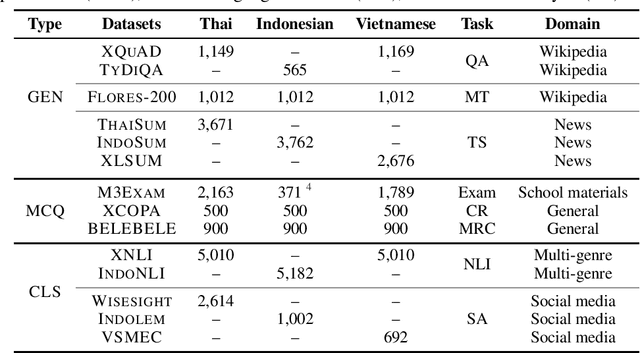
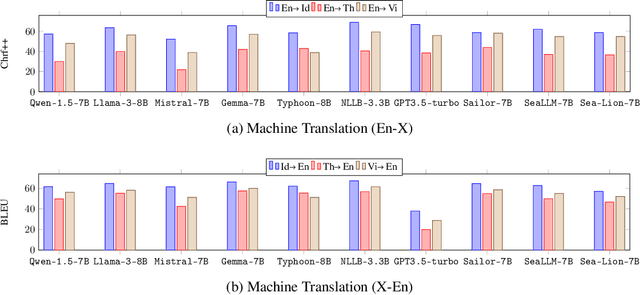
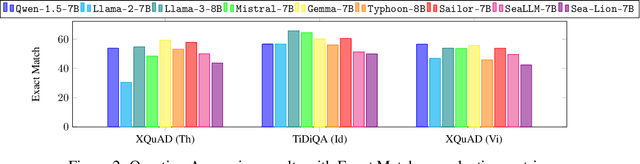
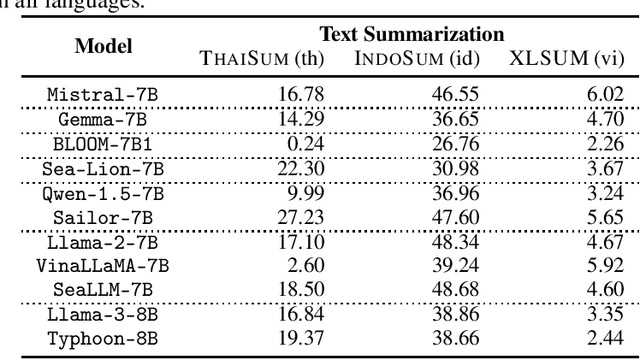
In this paper, we introduce SailCompass, a reproducible and robust evaluation benchmark for assessing Large Language Models (LLMs) on Southeast Asian Languages (SEA). SailCompass encompasses three main SEA languages, eight primary tasks including 14 datasets covering three task types (generation, multiple-choice questions, and classification). To improve the robustness of the evaluation approach, we explore different prompt configurations for multiple-choice questions and leverage calibrations to improve the faithfulness of classification tasks. With SailCompass, we derive the following findings: (1) SEA-specialized LLMs still outperform general LLMs, although the gap has narrowed; (2) A balanced language distribution is important for developing better SEA-specialized LLMs; (3) Advanced prompting techniques (e.g., calibration, perplexity-based ranking) are necessary to better utilize LLMs. All datasets and evaluation scripts are public.