 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTalk Less, Verify More: Improving LLM Assistants with Semantic Checks and Execution Feedback
Jan 07, 2026As large language model (LLM) assistants become increasingly integrated into enterprise workflows, their ability to generate accurate, semantically aligned, and executable outputs is critical. However, current conversational business analytics (CBA) systems often lack built-in verification mechanisms, leaving users to manually validate potentially flawed results. This paper introduces two complementary verification techniques: Q*, which performs reverse translation and semantic matching between code and user intent, and Feedback+, which incorporates execution feedback to guide code refinement. Embedded within a generator-discriminator framework, these mechanisms shift validation responsibilities from users to the system. Evaluations on three benchmark datasets, Spider, Bird, and GSM8K, demonstrate that both Q* and Feedback+ reduce error rates and task completion time. The study also identifies reverse translation as a key bottleneck, highlighting opportunities for future improvement. Overall, this work contributes a design-oriented framework for building more reliable, enterprise-grade GenAI systems capable of trustworthy decision support.
Sentiment-Aware Extractive and Abstractive Summarization for Unstructured Text Mining
Dec 23, 2025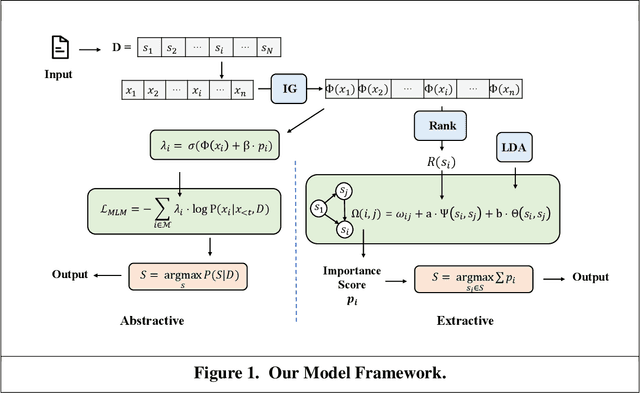
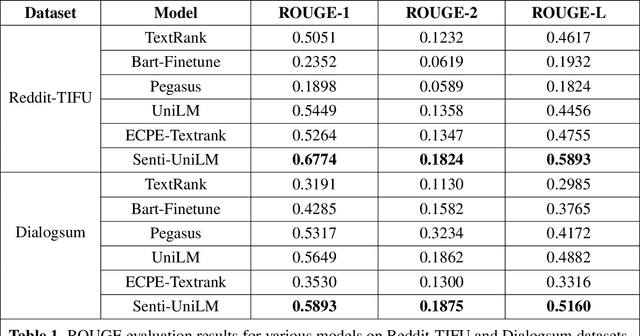
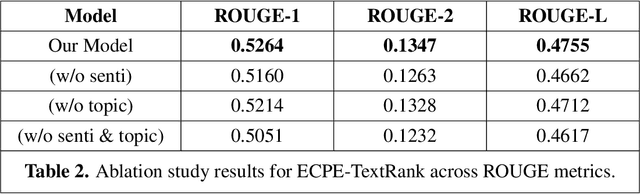
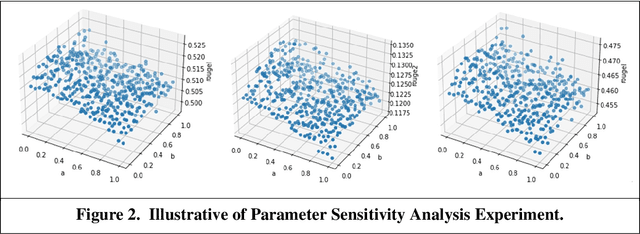
With the rapid growth of unstructured data from social media, reviews, and forums, text mining has become essential in Information Systems (IS) for extracting actionable insights. Summarization can condense fragmented, emotion-rich posts, but existing methods-optimized for structured news-struggle with noisy, informal content. Emotional cues are critical for IS tasks such as brand monitoring and market analysis, yet few studies integrate sentiment modeling into summarization of short user-generated texts. We propose a sentiment-aware framework extending extractive (TextRank) and abstractive (UniLM) approaches by embedding sentiment signals into ranking and generation processes. This dual design improves the capture of emotional nuances and thematic relevance, producing concise, sentiment-enriched summaries that enhance timely interventions and strategic decision-making in dynamic online environments.
Practical Global and Local Bounds in Gaussian Process Regression via Chaining
Nov 17, 2025Gaussian process regression (GPR) is a popular nonparametric Bayesian method that provides predictive uncertainty estimates and is widely used in safety-critical applications. While prior research has introduced various uncertainty bounds, most existing approaches require access to specific input features, and rely on posterior mean and variance estimates or the tuning of hyperparameters. These limitations hinder robustness and fail to capture the model's global behavior in expectation. To address these limitations, we propose a chaining-based framework for estimating upper and lower bounds on the expected extreme values over unseen data, without requiring access to specific input features. We provide kernel-specific refinements for commonly used kernels such as RBF and Matérn, in which our bounds are tighter than generic constructions. We further improve numerical tightness by avoiding analytical relaxations. In addition to global estimation, we also develop a novel method for local uncertainty quantification at specified inputs. This approach leverages chaining geometry through partition diameters, adapting to local structures without relying on posterior variance scaling. Our experimental results validate the theoretical findings and demonstrate that our method outperforms existing approaches on both synthetic and real-world datasets.
The Shape of Reasoning: Topological Analysis of Reasoning Traces in Large Language Models
Oct 23, 2025Evaluating the quality of reasoning traces from large language models remains understudied, labor-intensive, and unreliable: current practice relies on expert rubrics, manual annotation, and slow pairwise judgments. Automated efforts are dominated by graph-based proxies that quantify structural connectivity but do not clarify what constitutes high-quality reasoning; such abstractions can be overly simplistic for inherently complex processes. We introduce a topological data analysis (TDA)-based evaluation framework that captures the geometry of reasoning traces and enables label-efficient, automated assessment. In our empirical study, topological features yield substantially higher predictive power for assessing reasoning quality than standard graph metrics, suggesting that effective reasoning is better captured by higher-dimensional geometric structures rather than purely relational graphs. We further show that a compact, stable set of topological features reliably indicates trace quality, offering a practical signal for future reinforcement learning algorithms.
In-Training Multicalibrated Survival Analysis for Healthcare via Constrained Optimization
Jul 03, 2025Survival analysis is an important problem in healthcare because it models the relationship between an individual's covariates and the onset time of an event of interest (e.g., death). It is important for survival models to be well-calibrated (i.e., for their predicted probabilities to be close to ground-truth probabilities) because badly calibrated systems can result in erroneous clinical decisions. Existing survival models are typically calibrated at the population level only, and thus run the risk of being poorly calibrated for one or more minority subpopulations. We propose a model called GRADUATE that achieves multicalibration by ensuring that all subpopulations are well-calibrated too. GRADUATE frames multicalibration as a constrained optimization problem, and optimizes both calibration and discrimination in-training to achieve a good balance between them. We mathematically prove that the optimization method used yields a solution that is both near-optimal and feasible with high probability. Empirical comparisons against state-of-the-art baselines on real-world clinical datasets demonstrate GRADUATE's efficacy. In a detailed analysis, we elucidate the shortcomings of the baselines vis-a-vis GRADUATE's strengths.
Investigating the Effects of Cognitive Biases in Prompts on Large Language Model Outputs
Jun 14, 2025This paper investigates the influence of cognitive biases on Large Language Models (LLMs) outputs. Cognitive biases, such as confirmation and availability biases, can distort user inputs through prompts, potentially leading to unfaithful and misleading outputs from LLMs. Using a systematic framework, our study introduces various cognitive biases into prompts and assesses their impact on LLM accuracy across multiple benchmark datasets, including general and financial Q&A scenarios. The results demonstrate that even subtle biases can significantly alter LLM answer choices, highlighting a critical need for bias-aware prompt design and mitigation strategy. Additionally, our attention weight analysis highlights how these biases can alter the internal decision-making processes of LLMs, affecting the attention distribution in ways that are associated with output inaccuracies. This research has implications for Al developers and users in enhancing the robustness and reliability of Al applications in diverse domains.
SMARTe: Slot-based Method for Accountable Relational Triple extraction
Apr 17, 2025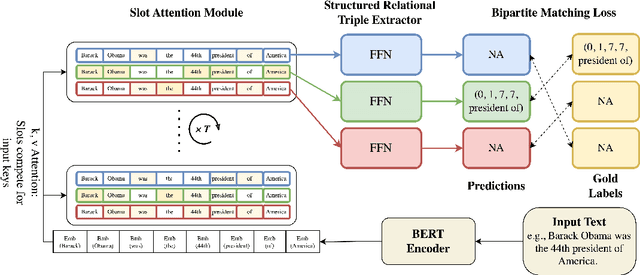
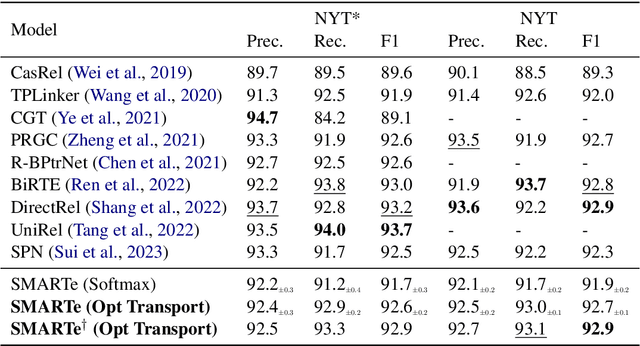
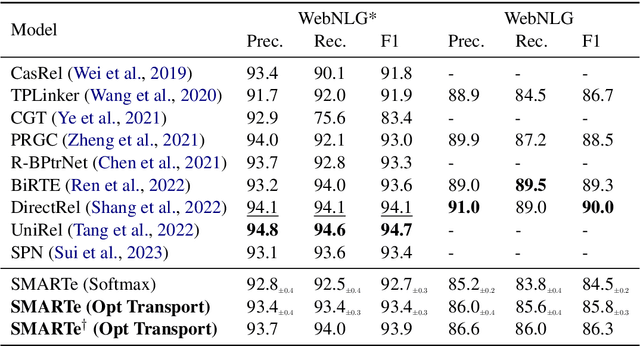
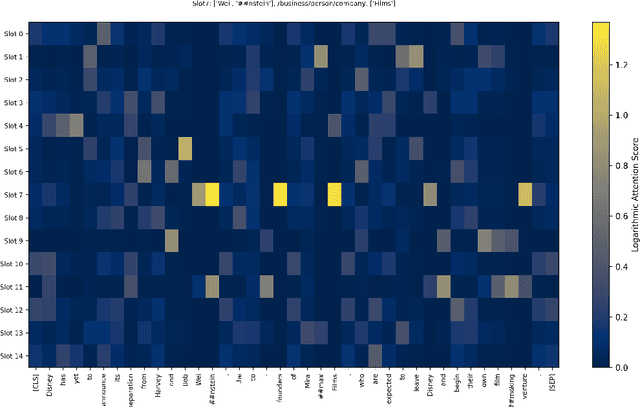
Relational Triple Extraction (RTE) is a fundamental task in Natural Language Processing (NLP). However, prior research has primarily focused on optimizing model performance, with limited efforts to understand the internal mechanisms driving these models. Many existing methods rely on complex preprocessing to induce specific interactions, often resulting in opaque systems that may not fully align with their theoretical foundations. To address these limitations, we propose SMARTe: a Slot-based Method for Accountable Relational Triple extraction. SMARTe introduces intrinsic interpretability through a slot attention mechanism and frames the task as a set prediction problem. Slot attention consolidates relevant information into distinct slots, ensuring all predictions can be explicitly traced to learned slot representations and the tokens contributing to each predicted relational triple. While emphasizing interpretability, SMARTe achieves performance comparable to state-of-the-art models. Evaluations on the NYT and WebNLG datasets demonstrate that adding interpretability does not compromise performance. Furthermore, we conducted qualitative assessments to showcase the explanations provided by SMARTe, using attention heatmaps that map to their respective tokens. We conclude with a discussion of our findings and propose directions for future research.
SailCompass: Towards Reproducible and Robust Evaluation for Southeast Asian Languages
Dec 02, 2024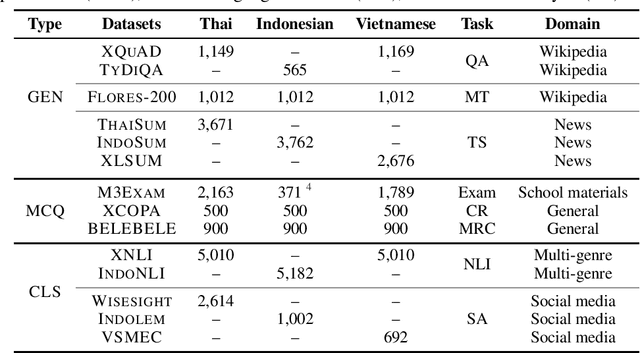
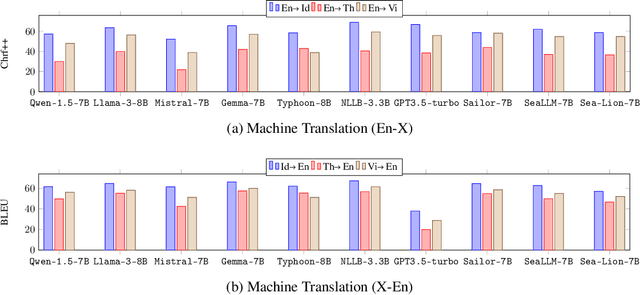
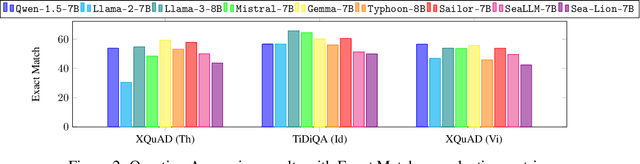
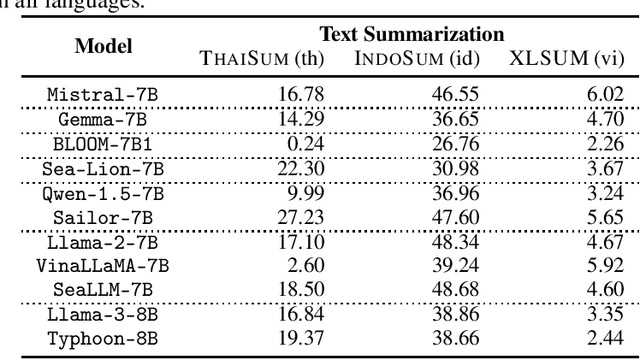
In this paper, we introduce SailCompass, a reproducible and robust evaluation benchmark for assessing Large Language Models (LLMs) on Southeast Asian Languages (SEA). SailCompass encompasses three main SEA languages, eight primary tasks including 14 datasets covering three task types (generation, multiple-choice questions, and classification). To improve the robustness of the evaluation approach, we explore different prompt configurations for multiple-choice questions and leverage calibrations to improve the faithfulness of classification tasks. With SailCompass, we derive the following findings: (1) SEA-specialized LLMs still outperform general LLMs, although the gap has narrowed; (2) A balanced language distribution is important for developing better SEA-specialized LLMs; (3) Advanced prompting techniques (e.g., calibration, perplexity-based ranking) are necessary to better utilize LLMs. All datasets and evaluation scripts are public.
Interpretable Predictive Models for Healthcare via Rational Logistic Regression
Nov 05, 2024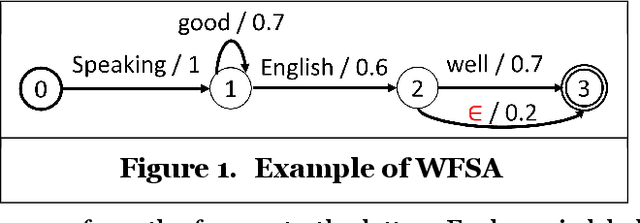
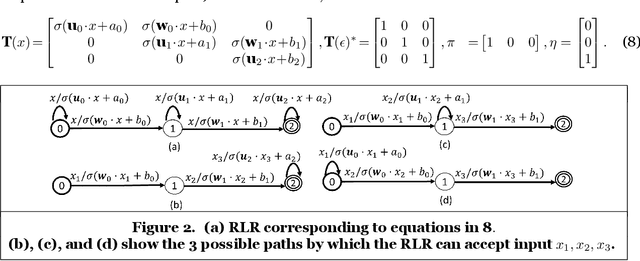
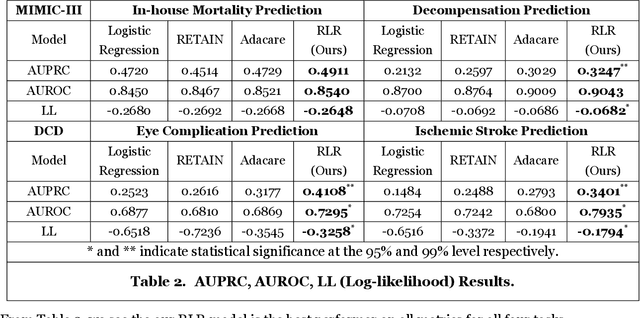
The healthcare sector has experienced a rapid accumulation of digital data recently, especially in the form of electronic health records (EHRs). EHRs constitute a precious resource that IS researchers could utilize for clinical applications (e.g., morbidity prediction). Deep learning seems like the obvious choice to exploit this surfeit of data. However, numerous studies have shown that deep learning does not enjoy the same kind of success on EHR data as it has in other domains; simple models like logistic regression are frequently as good as sophisticated deep learning ones. Inspired by this observation, we develop a novel model called rational logistic regression (RLR) that has standard logistic regression (LR) as its special case (and thus inherits LR's inductive bias that aligns with EHR data). RLR has rational series as its theoretical underpinnings, works on longitudinal time-series data, and learns interpretable patterns. Empirical comparisons on real-world clinical tasks demonstrate RLR's efficacy.
Explainable Risk Classification in Financial Reports
May 06, 2024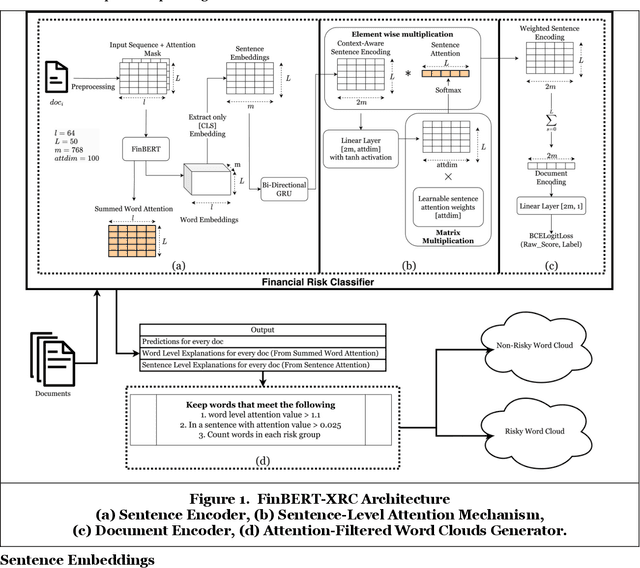
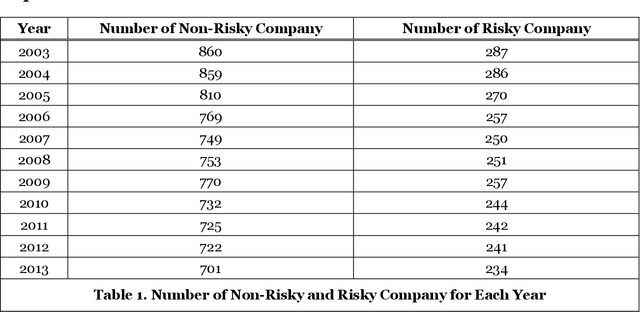
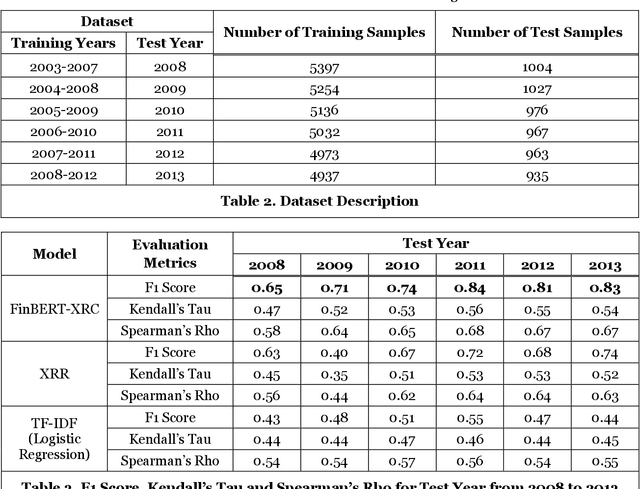
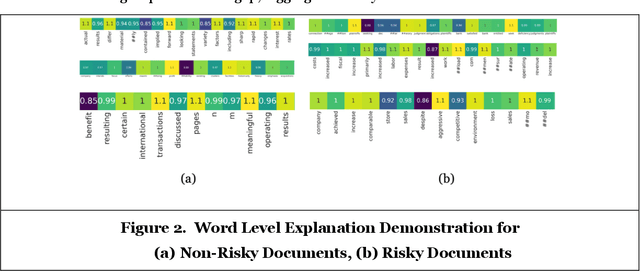
Every publicly traded company in the US is required to file an annual 10-K financial report, which contains a wealth of information about the company. In this paper, we propose an explainable deep-learning model, called FinBERT-XRC, that takes a 10-K report as input, and automatically assesses the post-event return volatility risk of its associated company. In contrast to previous systems, our proposed model simultaneously offers explanations of its classification decision at three different levels: the word, sentence, and corpus levels. By doing so, our model provides a comprehensive interpretation of its prediction to end users. This is particularly important in financial domains, where the transparency and accountability of algorithmic predictions play a vital role in their application to decision-making processes. Aside from its novel interpretability, our model surpasses the state of the art in predictive accuracy in experiments on a large real-world dataset of 10-K reports spanning six years.