 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining a Huggingface Model on AWS Sagemaker (Without Tears)
Dec 30, 2025The development of Large Language Models (LLMs) has primarily been driven by resource-rich research groups and industry partners. Due to the lack of on-premise computing resources required for increasingly complex models, many researchers are turning to cloud services like AWS SageMaker to train Hugging Face models. However, the steep learning curve of cloud platforms often presents a barrier for researchers accustomed to local environments. Existing documentation frequently leaves knowledge gaps, forcing users to seek fragmented information across the web. This demo paper aims to democratize cloud adoption by centralizing the essential information required for researchers to successfully train their first Hugging Face model on AWS SageMaker from scratch.
Can Automatic Post-Editing Improve NMT?
Sep 30, 2020
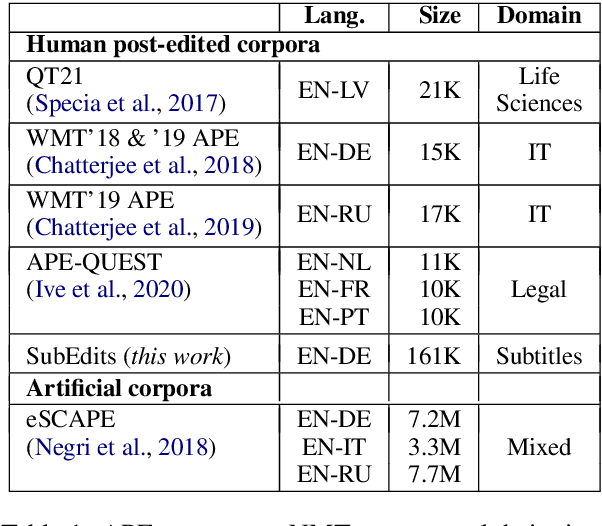


Automatic post-editing (APE) aims to improve machine translations, thereby reducing human post-editing effort. APE has had notable success when used with statistical machine translation (SMT) systems but has not been as successful over neural machine translation (NMT) systems. This has raised questions on the relevance of APE task in the current scenario. However, the training of APE models has been heavily reliant on large-scale artificial corpora combined with only limited human post-edited data. We hypothesize that APE models have been underperforming in improving NMT translations due to the lack of adequate supervision. To ascertain our hypothesis, we compile a larger corpus of human post-edits of English to German NMT. We empirically show that a state-of-art neural APE model trained on this corpus can significantly improve a strong in-domain NMT system, challenging the current understanding in the field. We further investigate the effects of varying training data sizes, using artificial training data, and domain specificity for the APE task. We release this new corpus under CC BY-NC-SA 4.0 license at https://github.com/shamilcm/pedra.
Lexically Constrained Neural Machine Translation with Levenshtein Transformer
Apr 27, 2020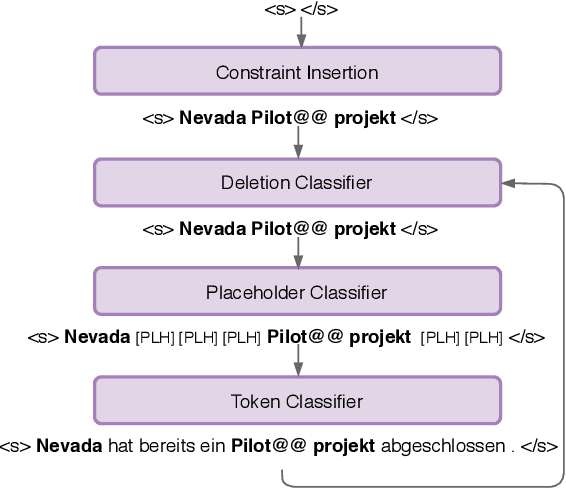
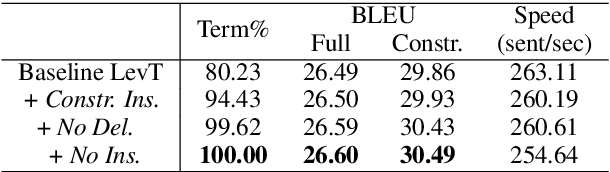

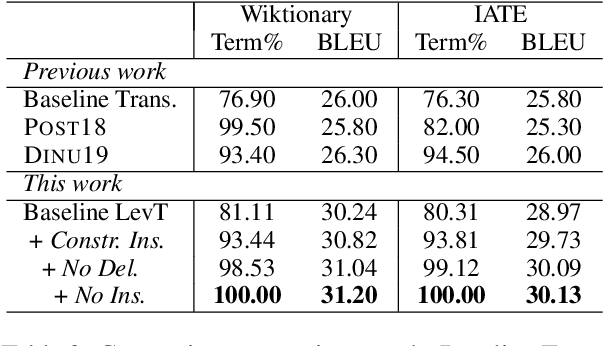
This paper proposes a simple and effective algorithm for incorporating lexical constraints in neural machine translation. Previous work either required re-training existing models with the lexical constraints or incorporating them during beam search decoding with significantly higher computational overheads. Leveraging the flexibility and speed of a recently proposed Levenshtein Transformer model (Gu et al., 2019), our method injects terminology constraints at inference time without any impact on decoding speed. Our method does not require any modification to the training procedure and can be easily applied at runtime with custom dictionaries. Experiments on English-German WMT datasets show that our approach improves an unconstrained baseline and previous approaches.
Don't Classify, Translate: Multi-Level E-Commerce Product Categorization Via Machine Translation
Dec 14, 2018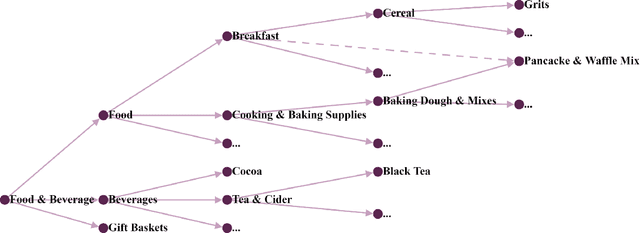
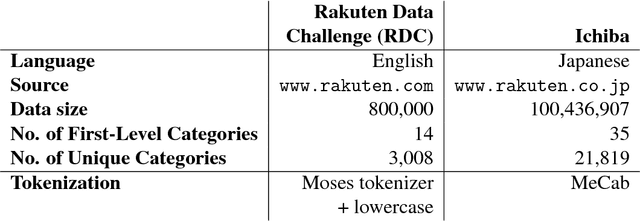
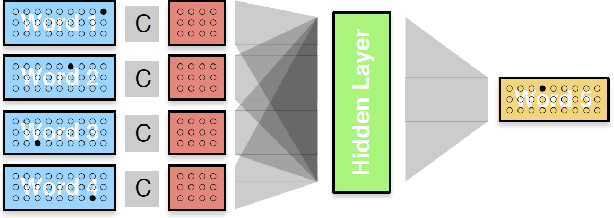

E-commerce platforms categorize their products into a multi-level taxonomy tree with thousands of leaf categories. Conventional methods for product categorization are typically based on machine learning classification algorithms. These algorithms take product information as input (e.g., titles and descriptions) to classify a product into a leaf category. In this paper, we propose a new paradigm based on machine translation. In our approach, we translate a product's natural language description into a sequence of tokens representing a root-to-leaf path in a product taxonomy. In our experiments on two large real-world datasets, we show that our approach achieves better predictive accuracy than a state-of-the-art classification system for product categorization. In addition, we demonstrate that our machine translation models can propose meaningful new paths between previously unconnected nodes in a taxonomy tree, thereby transforming the taxonomy into a directed acyclic graph (DAG). We discuss how the resultant taxonomy DAG promotes user-friendly navigation, and how it is more adaptable to new products.