 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Automatic Post-Editing Improve NMT?
Sep 30, 2020
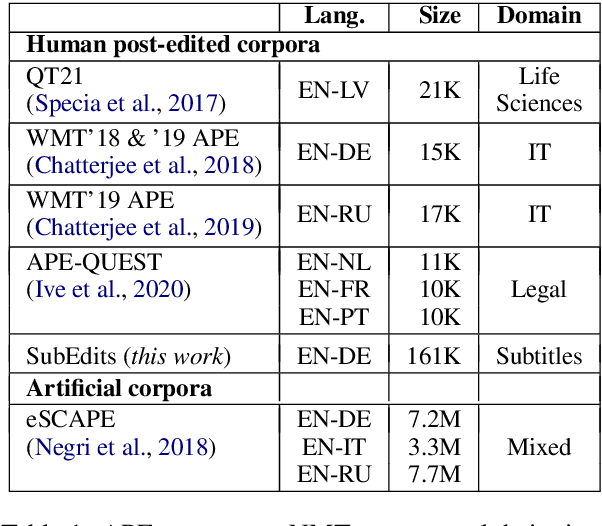


Automatic post-editing (APE) aims to improve machine translations, thereby reducing human post-editing effort. APE has had notable success when used with statistical machine translation (SMT) systems but has not been as successful over neural machine translation (NMT) systems. This has raised questions on the relevance of APE task in the current scenario. However, the training of APE models has been heavily reliant on large-scale artificial corpora combined with only limited human post-edited data. We hypothesize that APE models have been underperforming in improving NMT translations due to the lack of adequate supervision. To ascertain our hypothesis, we compile a larger corpus of human post-edits of English to German NMT. We empirically show that a state-of-art neural APE model trained on this corpus can significantly improve a strong in-domain NMT system, challenging the current understanding in the field. We further investigate the effects of varying training data sizes, using artificial training data, and domain specificity for the APE task. We release this new corpus under CC BY-NC-SA 4.0 license at https://github.com/shamilcm/pedra.
Lexically Constrained Neural Machine Translation with Levenshtein Transformer
Apr 27, 2020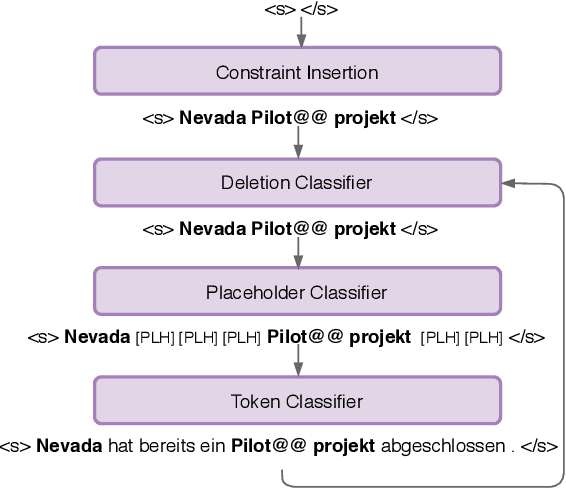
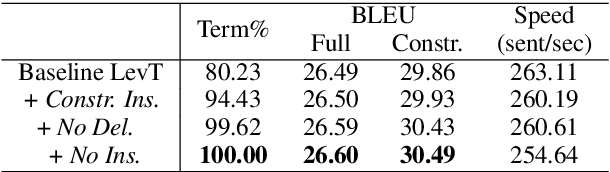

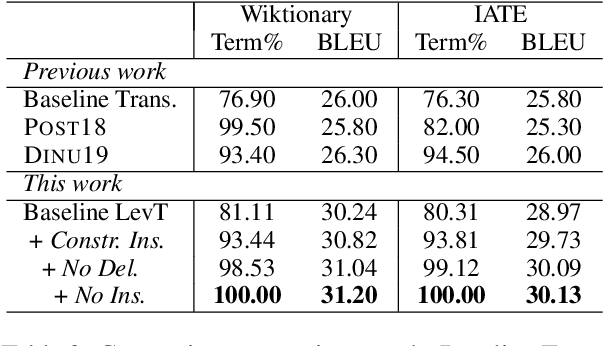
This paper proposes a simple and effective algorithm for incorporating lexical constraints in neural machine translation. Previous work either required re-training existing models with the lexical constraints or incorporating them during beam search decoding with significantly higher computational overheads. Leveraging the flexibility and speed of a recently proposed Levenshtein Transformer model (Gu et al., 2019), our method injects terminology constraints at inference time without any impact on decoding speed. Our method does not require any modification to the training procedure and can be easily applied at runtime with custom dictionaries. Experiments on English-German WMT datasets show that our approach improves an unconstrained baseline and previous approaches.