 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRakutenAI-7B: Extending Large Language Models for Japanese
Mar 21, 2024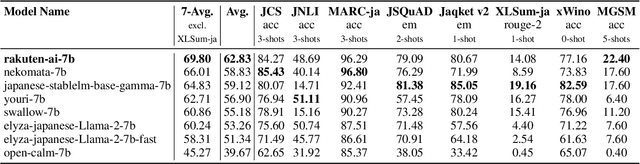
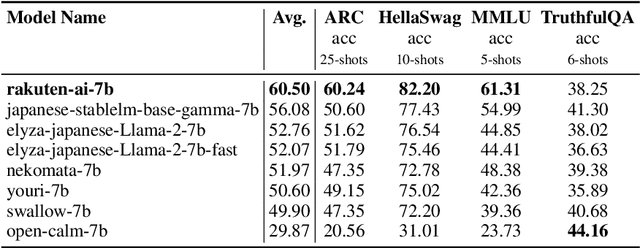
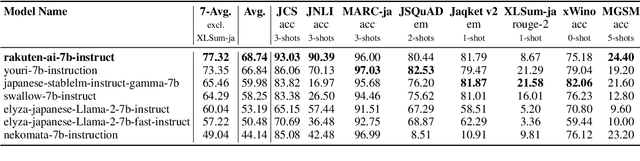
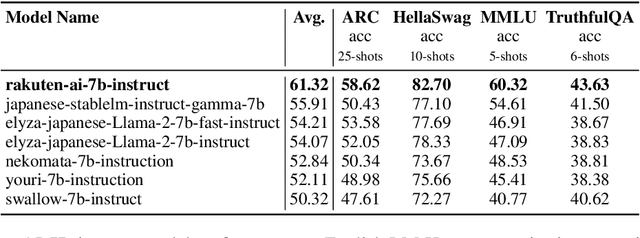
We introduce RakutenAI-7B, a suite of Japanese-oriented large language models that achieve the best performance on the Japanese LM Harness benchmarks among the open 7B models. Along with the foundation model, we release instruction- and chat-tuned models, RakutenAI-7B-instruct and RakutenAI-7B-chat respectively, under the Apache 2.0 license.
Can Automatic Post-Editing Improve NMT?
Sep 30, 2020
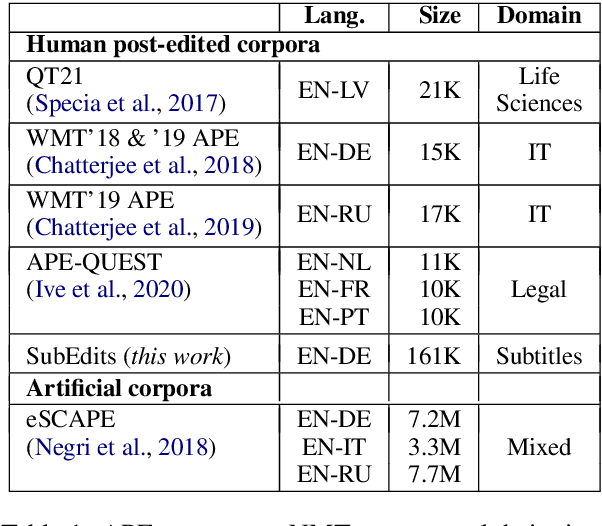


Automatic post-editing (APE) aims to improve machine translations, thereby reducing human post-editing effort. APE has had notable success when used with statistical machine translation (SMT) systems but has not been as successful over neural machine translation (NMT) systems. This has raised questions on the relevance of APE task in the current scenario. However, the training of APE models has been heavily reliant on large-scale artificial corpora combined with only limited human post-edited data. We hypothesize that APE models have been underperforming in improving NMT translations due to the lack of adequate supervision. To ascertain our hypothesis, we compile a larger corpus of human post-edits of English to German NMT. We empirically show that a state-of-art neural APE model trained on this corpus can significantly improve a strong in-domain NMT system, challenging the current understanding in the field. We further investigate the effects of varying training data sizes, using artificial training data, and domain specificity for the APE task. We release this new corpus under CC BY-NC-SA 4.0 license at https://github.com/shamilcm/pedra.