 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Multilingual Instruction Finetuning via Linguistically Natural and Diverse Datasets
Jul 01, 2024



Advancements in Large Language Models (LLMs) have significantly enhanced instruction-following capabilities. However, most Instruction Fine-Tuning (IFT) datasets are predominantly in English, limiting model performance in other languages. Traditional methods for creating multilingual IFT datasets such as translating existing English IFT datasets or converting existing NLP datasets into IFT datasets by templating, struggle to capture linguistic nuances and ensure prompt (instruction) diversity. To address this issue, we propose a novel method for collecting multilingual IFT datasets that preserves linguistic naturalness and ensures prompt diversity. This approach leverages English-focused LLMs, monolingual corpora, and a scoring function to create high-quality, diversified IFT datasets in multiple languages. Experiments demonstrate that LLMs finetuned using these IFT datasets show notable improvements in both generative and discriminative tasks, indicating enhanced language comprehension by LLMs in non-English contexts. Specifically, on the multilingual summarization task, LLMs using our IFT dataset achieved 17.57% and 15.23% improvements over LLMs fine-tuned with translation-based and template-based datasets, respectively.
Can Automatic Post-Editing Improve NMT?
Sep 30, 2020
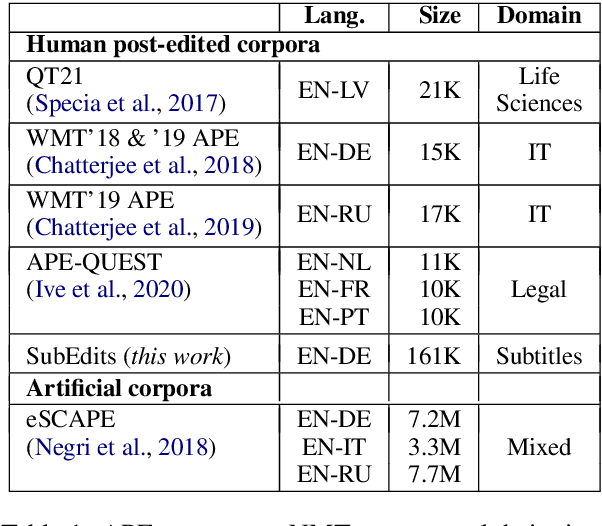


Automatic post-editing (APE) aims to improve machine translations, thereby reducing human post-editing effort. APE has had notable success when used with statistical machine translation (SMT) systems but has not been as successful over neural machine translation (NMT) systems. This has raised questions on the relevance of APE task in the current scenario. However, the training of APE models has been heavily reliant on large-scale artificial corpora combined with only limited human post-edited data. We hypothesize that APE models have been underperforming in improving NMT translations due to the lack of adequate supervision. To ascertain our hypothesis, we compile a larger corpus of human post-edits of English to German NMT. We empirically show that a state-of-art neural APE model trained on this corpus can significantly improve a strong in-domain NMT system, challenging the current understanding in the field. We further investigate the effects of varying training data sizes, using artificial training data, and domain specificity for the APE task. We release this new corpus under CC BY-NC-SA 4.0 license at https://github.com/shamilcm/pedra.
Lexically Constrained Neural Machine Translation with Levenshtein Transformer
Apr 27, 2020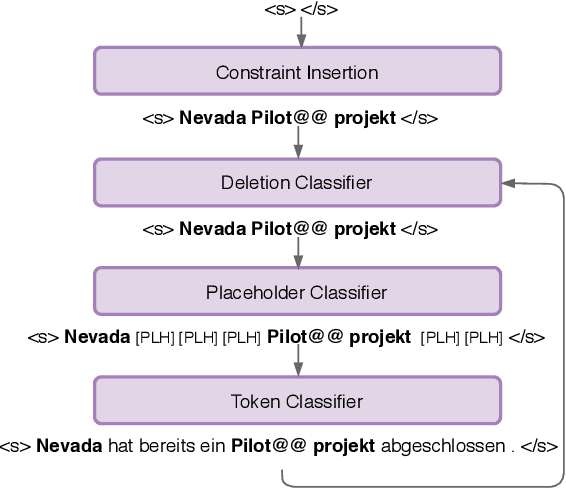
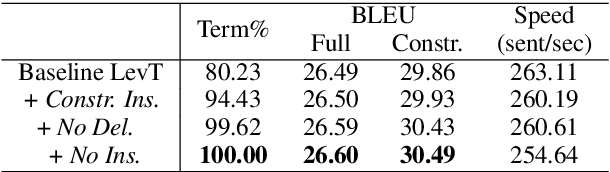

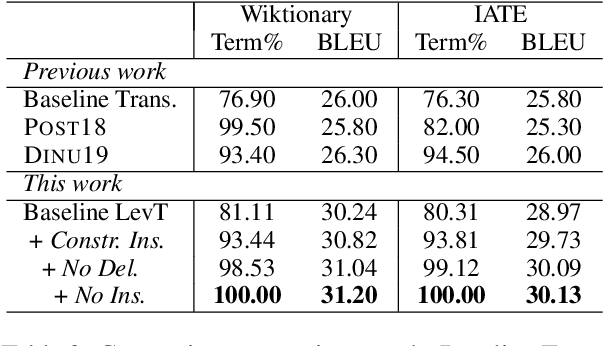
This paper proposes a simple and effective algorithm for incorporating lexical constraints in neural machine translation. Previous work either required re-training existing models with the lexical constraints or incorporating them during beam search decoding with significantly higher computational overheads. Leveraging the flexibility and speed of a recently proposed Levenshtein Transformer model (Gu et al., 2019), our method injects terminology constraints at inference time without any impact on decoding speed. Our method does not require any modification to the training procedure and can be easily applied at runtime with custom dictionaries. Experiments on English-German WMT datasets show that our approach improves an unconstrained baseline and previous approaches.
A Multilayer Convolutional Encoder-Decoder Neural Network for Grammatical Error Correction
Jan 26, 2018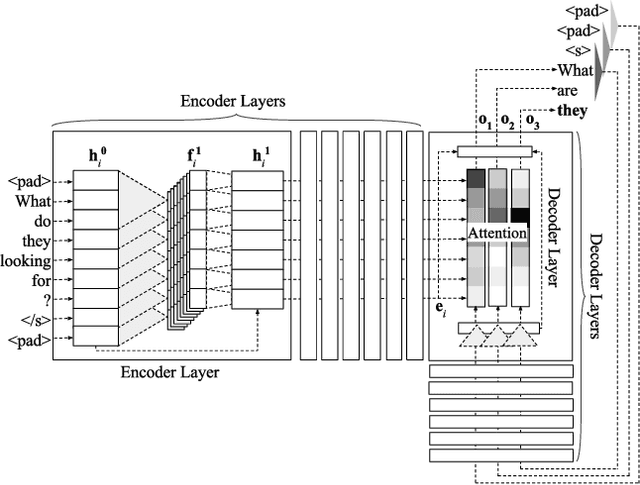
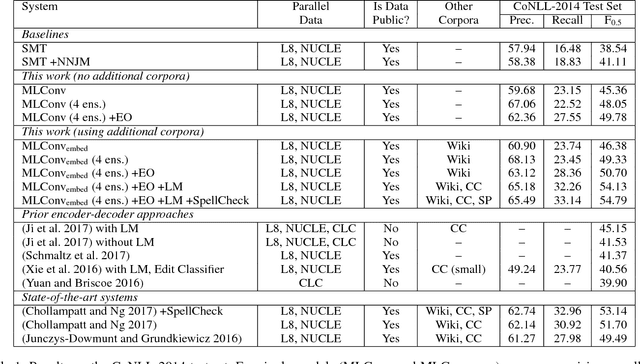
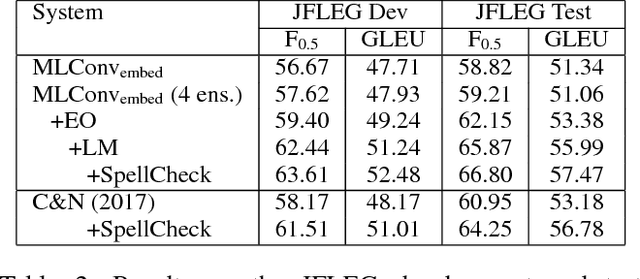
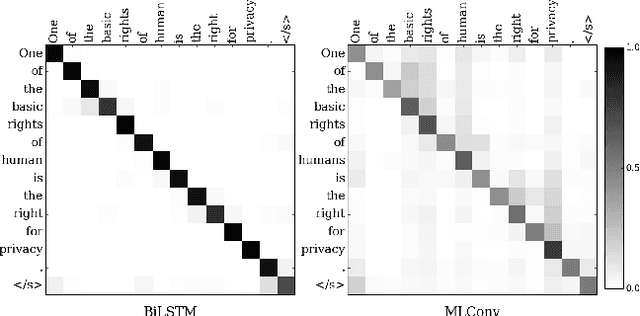
We improve automatic correction of grammatical, orthographic, and collocation errors in text using a multilayer convolutional encoder-decoder neural network. The network is initialized with embeddings that make use of character N-gram information to better suit this task. When evaluated on common benchmark test data sets (CoNLL-2014 and JFLEG), our model substantially outperforms all prior neural approaches on this task as well as strong statistical machine translation-based systems with neural and task-specific features trained on the same data. Our analysis shows the superiority of convolutional neural networks over recurrent neural networks such as long short-term memory (LSTM) networks in capturing the local context via attention, and thereby improving the coverage in correcting grammatical errors. By ensembling multiple models, and incorporating an N-gram language model and edit features via rescoring, our novel method becomes the first neural approach to outperform the current state-of-the-art statistical machine translation-based approach, both in terms of grammaticality and fluency.
Exploiting N-Best Hypotheses to Improve an SMT Approach to Grammatical Error Correction
Jun 01, 2016
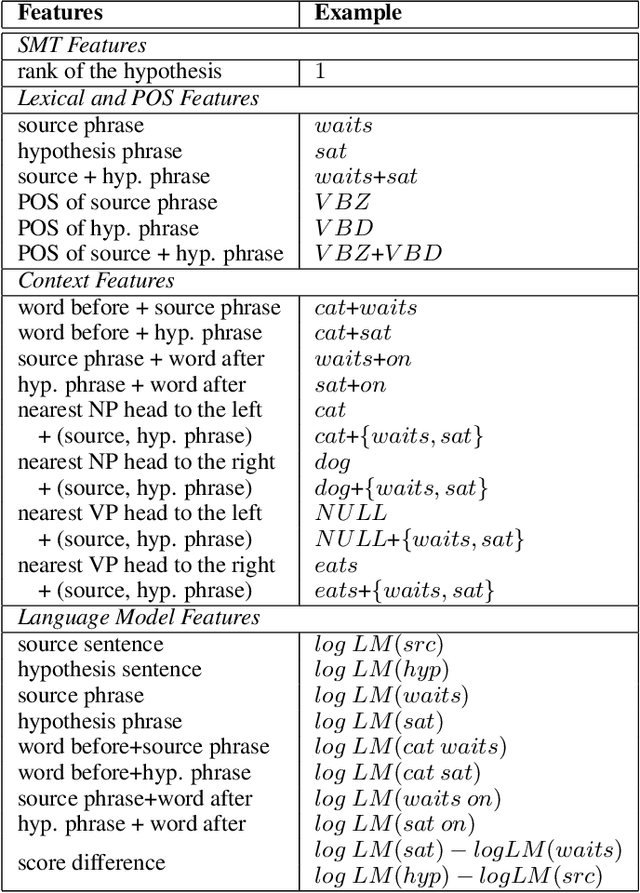


Grammatical error correction (GEC) is the task of detecting and correcting grammatical errors in texts written by second language learners. The statistical machine translation (SMT) approach to GEC, in which sentences written by second language learners are translated to grammatically correct sentences, has achieved state-of-the-art accuracy. However, the SMT approach is unable to utilize global context. In this paper, we propose a novel approach to improve the accuracy of GEC, by exploiting the n-best hypotheses generated by an SMT approach. Specifically, we build a classifier to score the edits in the n-best hypotheses. The classifier can be used to select appropriate edits or re-rank the n-best hypotheses. We apply these methods to a state-of-the-art GEC system that uses the SMT approach. Our experiments show that our methods achieve statistically significant improvements in accuracy over the best published results on a benchmark test dataset on GEC.
Neural Network Translation Models for Grammatical Error Correction
Jun 01, 2016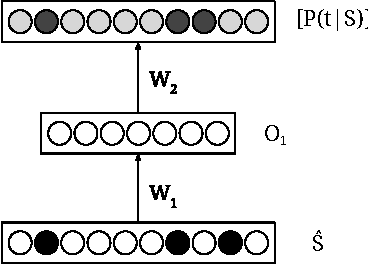
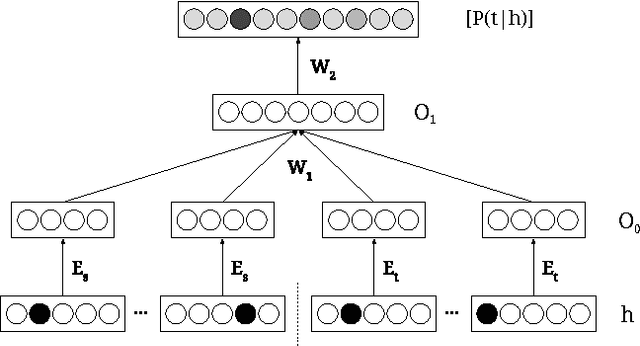

Phrase-based statistical machine translation (SMT) systems have previously been used for the task of grammatical error correction (GEC) to achieve state-of-the-art accuracy. The superiority of SMT systems comes from their ability to learn text transformations from erroneous to corrected text, without explicitly modeling error types. However, phrase-based SMT systems suffer from limitations of discrete word representation, linear mapping, and lack of global context. In this paper, we address these limitations by using two different yet complementary neural network models, namely a neural network global lexicon model and a neural network joint model. These neural networks can generalize better by using continuous space representation of words and learn non-linear mappings. Moreover, they can leverage contextual information from the source sentence more effectively. By adding these two components, we achieve statistically significant improvement in accuracy for grammatical error correction over a state-of-the-art GEC system.