 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
TorchTraceAP: A New Benchmark Dataset for Detecting Performance Anti-Patterns in Computer Vision Models
Dec 16, 2025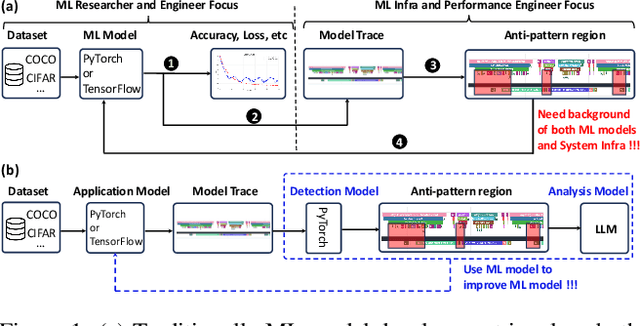
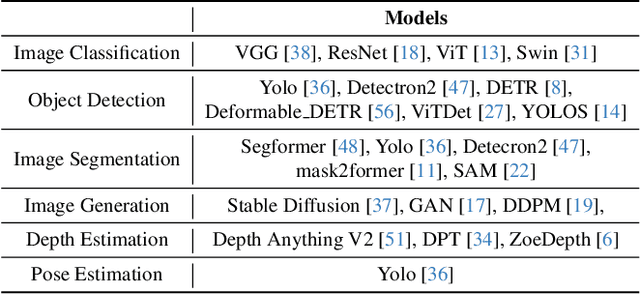
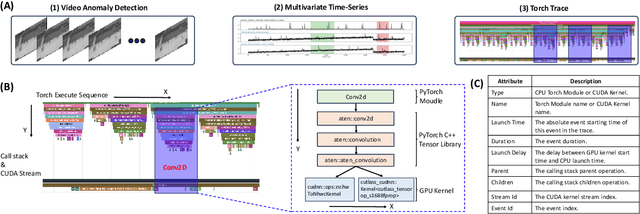

Identifying and addressing performance anti-patterns in machine learning (ML) models is critical for efficient training and inference, but it typically demands deep expertise spanning system infrastructure, ML models and kernel development. While large tech companies rely on dedicated ML infrastructure engineers to analyze torch traces and benchmarks, such resource-intensive workflows are largely inaccessible to computer vision researchers in general. Among the challenges, pinpointing problematic trace segments within lengthy execution traces remains the most time-consuming task, and is difficult to automate with current ML models, including LLMs. In this work, we present the first benchmark dataset specifically designed to evaluate and improve ML models' ability to detect anti patterns in traces. Our dataset contains over 600 PyTorch traces from diverse computer vision models classification, detection, segmentation, and generation collected across multiple hardware platforms. We also propose a novel iterative approach: a lightweight ML model first detects trace segments with anti patterns, followed by a large language model (LLM) for fine grained classification and targeted feedback. Experimental results demonstrate that our method significantly outperforms unsupervised clustering and rule based statistical techniques for detecting anti pattern regions. Our method also effectively compensates LLM's limited context length and reasoning inefficiencies.
Unleashing In-context Learning of Autoregressive Models for Few-shot Image Manipulation
Dec 03, 2024



Text-guided image manipulation has experienced notable advancement in recent years. In order to mitigate linguistic ambiguity, few-shot learning with visual examples has been applied for instructions that are underrepresented in the training set, or difficult to describe purely in language. However, learning from visual prompts requires strong reasoning capability, which diffusion models are struggling with. To address this issue, we introduce a novel multi-modal autoregressive model, dubbed $\textbf{InstaManip}$, that can $\textbf{insta}$ntly learn a new image $\textbf{manip}$ulation operation from textual and visual guidance via in-context learning, and apply it to new query images. Specifically, we propose an innovative group self-attention mechanism to break down the in-context learning process into two separate stages -- learning and applying, which simplifies the complex problem into two easier tasks. We also introduce a relation regularization method to further disentangle image transformation features from irrelevant contents in exemplar images. Extensive experiments suggest that our method surpasses previous few-shot image manipulation models by a notable margin ($\geq$19% in human evaluation). We also find our model can be further boosted by increasing the number or diversity of exemplar images.
Self-Generated Critiques Boost Reward Modeling for Language Models
Nov 25, 2024



Reward modeling is crucial for aligning large language models (LLMs) with human preferences, especially in reinforcement learning from human feedback (RLHF). However, current reward models mainly produce scalar scores and struggle to incorporate critiques in a natural language format. We hypothesize that predicting both critiques and the scalar reward would improve reward modeling ability. Motivated by this, we propose Critic-RM, a framework that improves reward models using self-generated critiques without extra supervision. Critic-RM employs a two-stage process: generating and filtering high-quality critiques, followed by joint fine-tuning on reward prediction and critique generation. Experiments across benchmarks show that Critic-RM improves reward modeling accuracy by 3.7%-7.3% compared to standard reward models and LLM judges, demonstrating strong performance and data efficiency. Additional studies further validate the effectiveness of generated critiques in rectifying flawed reasoning steps with 2.5%-3.2% gains in improving reasoning accuracy.
Multi-IF: Benchmarking LLMs on Multi-Turn and Multilingual Instructions Following
Oct 21, 2024Large Language Models (LLMs) have demonstrated impressive capabilities in various tasks, including instruction following, which is crucial for aligning model outputs with user expectations. However, evaluating LLMs' ability to follow instructions remains challenging due to the complexity and subjectivity of human language. Current benchmarks primarily focus on single-turn, monolingual instructions, which do not adequately reflect the complexities of real-world applications that require handling multi-turn and multilingual interactions. To address this gap, we introduce Multi-IF, a new benchmark designed to assess LLMs' proficiency in following multi-turn and multilingual instructions. Multi-IF, which utilizes a hybrid framework combining LLM and human annotators, expands upon the IFEval by incorporating multi-turn sequences and translating the English prompts into another 7 languages, resulting in a dataset of 4,501 multilingual conversations, where each has three turns. Our evaluation of 14 state-of-the-art LLMs on Multi-IF reveals that it presents a significantly more challenging task than existing benchmarks. All the models tested showed a higher rate of failure in executing instructions correctly with each additional turn. For example, o1-preview drops from 0.877 at the first turn to 0.707 at the third turn in terms of average accuracy over all languages. Moreover, languages with non-Latin scripts (Hindi, Russian, and Chinese) generally exhibit higher error rates, suggesting potential limitations in the models' multilingual capabilities. We release Multi-IF prompts and the evaluation code base to encourage further research in this critical area.
Law of the Weakest Link: Cross Capabilities of Large Language Models
Sep 30, 2024
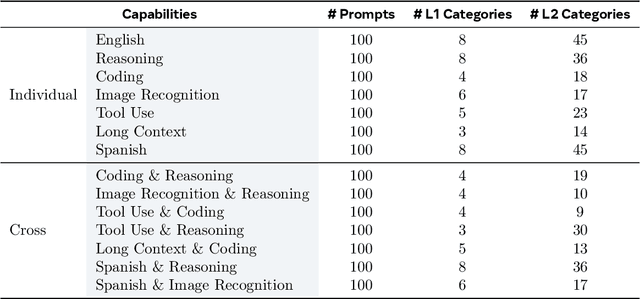
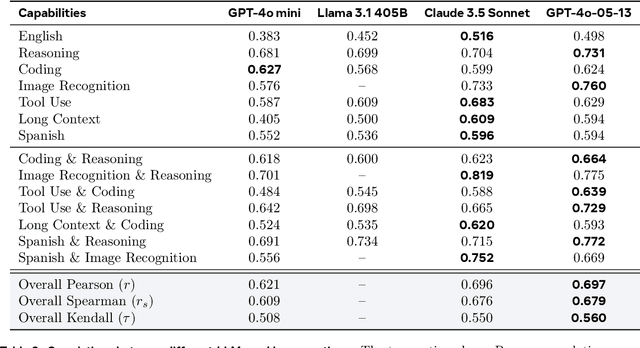
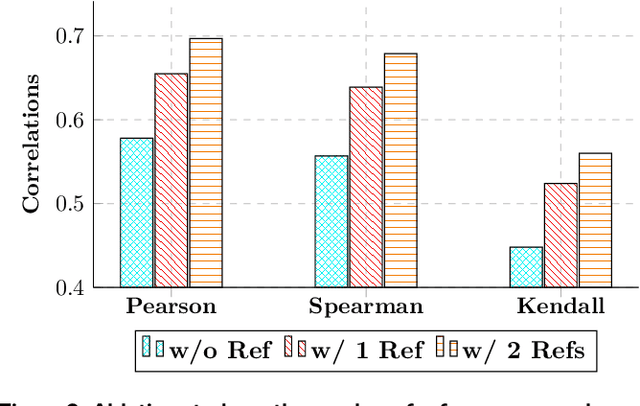
The development and evaluation of Large Language Models (LLMs) have largely focused on individual capabilities. However, this overlooks the intersection of multiple abilities across different types of expertise that are often required for real-world tasks, which we term cross capabilities. To systematically explore this concept, we first define seven core individual capabilities and then pair them to form seven common cross capabilities, each supported by a manually constructed taxonomy. Building on these definitions, we introduce CrossEval, a benchmark comprising 1,400 human-annotated prompts, with 100 prompts for each individual and cross capability. To ensure reliable evaluation, we involve expert annotators to assess 4,200 model responses, gathering 8,400 human ratings with detailed explanations to serve as reference examples. Our findings reveal that, in both static evaluations and attempts to enhance specific abilities, current LLMs consistently exhibit the "Law of the Weakest Link," where cross-capability performance is significantly constrained by the weakest component. Specifically, across 58 cross-capability scores from 17 models, 38 scores are lower than all individual capabilities, while 20 fall between strong and weak, but closer to the weaker ability. These results highlight the under-performance of LLMs in cross-capability tasks, making the identification and improvement of the weakest capabilities a critical priority for future research to optimize performance in complex, multi-dimensional scenarios.
Why mamba is effective? Exploit Linear Transformer-Mamba Network for Multi-Modality Image Fusion
Sep 05, 2024Multi-modality image fusion aims to integrate the merits of images from different sources and render high-quality fusion images. However, existing feature extraction and fusion methods are either constrained by inherent local reduction bias and static parameters during inference (CNN) or limited by quadratic computational complexity (Transformers), and cannot effectively extract and fuse features. To solve this problem, we propose a dual-branch image fusion network called Tmamba. It consists of linear Transformer and Mamba, which has global modeling capabilities while maintaining linear complexity. Due to the difference between the Transformer and Mamba structures, the features extracted by the two branches carry channel and position information respectively. T-M interaction structure is designed between the two branches, using global learnable parameters and convolutional layers to transfer position and channel information respectively. We further propose cross-modal interaction at the attention level to obtain cross-modal attention. Experiments show that our Tmamba achieves promising results in multiple fusion tasks, including infrared-visible image fusion and medical image fusion. Code with checkpoints will be available after the peer-review process.
See What LLMs Cannot Answer: A Self-Challenge Framework for Uncovering LLM Weaknesses
Aug 16, 2024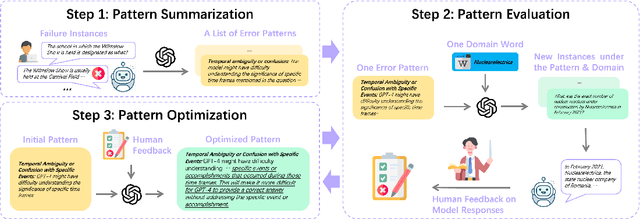
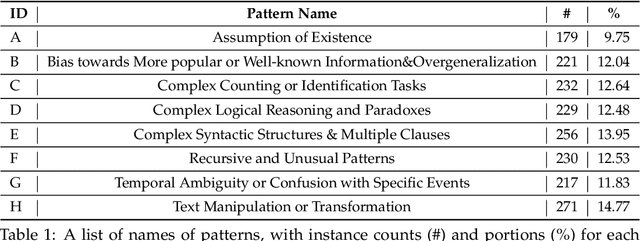


The impressive performance of Large Language Models (LLMs) has consistently surpassed numerous human-designed benchmarks, presenting new challenges in assessing the shortcomings of LLMs. Designing tasks and finding LLMs' limitations are becoming increasingly important. In this paper, we investigate the question of whether an LLM can discover its own limitations from the errors it makes. To this end, we propose a Self-Challenge evaluation framework with human-in-the-loop. Starting from seed instances that GPT-4 fails to answer, we prompt GPT-4 to summarize error patterns that can be used to generate new instances and incorporate human feedback on them to refine these patterns for generating more challenging data, iteratively. We end up with 8 diverse patterns, such as text manipulation and questions with assumptions. We then build a benchmark, SC-G4, consisting of 1,835 instances generated by GPT-4 using these patterns, with human-annotated gold responses. The SC-G4 serves as a challenging benchmark that allows for a detailed assessment of LLMs' abilities. Our results show that only 44.96\% of instances in SC-G4 can be answered correctly by GPT-4. Interestingly, our pilot study indicates that these error patterns also challenge other LLMs, such as Claude-3 and Llama-3, and cannot be fully resolved through fine-tuning. Our work takes the first step to demonstrate that LLMs can autonomously identify their inherent flaws and provide insights for future dynamic and automatic evaluation.
Improving Multilingual Instruction Finetuning via Linguistically Natural and Diverse Datasets
Jul 01, 2024



Advancements in Large Language Models (LLMs) have significantly enhanced instruction-following capabilities. However, most Instruction Fine-Tuning (IFT) datasets are predominantly in English, limiting model performance in other languages. Traditional methods for creating multilingual IFT datasets such as translating existing English IFT datasets or converting existing NLP datasets into IFT datasets by templating, struggle to capture linguistic nuances and ensure prompt (instruction) diversity. To address this issue, we propose a novel method for collecting multilingual IFT datasets that preserves linguistic naturalness and ensures prompt diversity. This approach leverages English-focused LLMs, monolingual corpora, and a scoring function to create high-quality, diversified IFT datasets in multiple languages. Experiments demonstrate that LLMs finetuned using these IFT datasets show notable improvements in both generative and discriminative tasks, indicating enhanced language comprehension by LLMs in non-English contexts. Specifically, on the multilingual summarization task, LLMs using our IFT dataset achieved 17.57% and 15.23% improvements over LLMs fine-tuned with translation-based and template-based datasets, respectively.
WPO: Enhancing RLHF with Weighted Preference Optimization
Jun 17, 2024Reinforcement learning from human feedback (RLHF) is a promising solution to align large language models (LLMs) more closely with human values. Off-policy preference optimization, where the preference data is obtained from other models, is widely adopted due to its cost efficiency and scalability. However, off-policy preference optimization often suffers from a distributional gap between the policy used for data collection and the target policy, leading to suboptimal optimization. In this paper, we propose a novel strategy to mitigate this problem by simulating on-policy learning with off-policy preference data. Our Weighted Preference Optimization (WPO) method adapts off-policy data to resemble on-policy data more closely by reweighting preference pairs according to their probability under the current policy. This method not only addresses the distributional gap problem but also enhances the optimization process without incurring additional costs. We validate our method on instruction following benchmarks including Alpaca Eval 2 and MT-bench. WPO not only outperforms Direct Preference Optimization (DPO) by up to 5.6% on Alpaca Eval 2 but also establishes a remarkable length-controlled winning rate against GPT-4-turbo of 48.6% based on Llama-3-8B-Instruct, making it the strongest 8B model on the leaderboard. We will release the code and models at https://github.com/wzhouad/WPO.