 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Apr 23, 2024



We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).
Auto-Instruct: Automatic Instruction Generation and Ranking for Black-Box Language Models
Oct 19, 2023Large language models (LLMs) can perform a wide range of tasks by following natural language instructions, without the necessity of task-specific fine-tuning. Unfortunately, the performance of LLMs is greatly influenced by the quality of these instructions, and manually writing effective instructions for each task is a laborious and subjective process. In this paper, we introduce Auto-Instruct, a novel method to automatically improve the quality of instructions provided to LLMs. Our method leverages the inherent generative ability of LLMs to produce diverse candidate instructions for a given task, and then ranks them using a scoring model trained on a variety of 575 existing NLP tasks. In experiments on 118 out-of-domain tasks, Auto-Instruct surpasses both human-written instructions and existing baselines of LLM-generated instructions. Furthermore, our method exhibits notable generalizability even with other LLMs that are not incorporated into its training process.
The Shifted and The Overlooked: A Task-oriented Investigation of User-GPT Interactions
Oct 19, 2023Recent progress in Large Language Models (LLMs) has produced models that exhibit remarkable performance across a variety of NLP tasks. However, it remains unclear whether the existing focus of NLP research accurately captures the genuine requirements of human users. This paper provides a comprehensive analysis of the divergence between current NLP research and the needs of real-world NLP applications via a large-scale collection of user-GPT conversations. We analyze a large-scale collection of real user queries to GPT. We compare these queries against existing NLP benchmark tasks and identify a significant gap between the tasks that users frequently request from LLMs and the tasks that are commonly studied in academic research. For example, we find that tasks such as ``design'' and ``planning'' are prevalent in user interactions but are largely neglected or different from traditional NLP benchmarks. We investigate these overlooked tasks, dissect the practical challenges they pose, and provide insights toward a roadmap to make LLMs better aligned with user needs.
In-Context Demonstration Selection with Cross Entropy Difference
May 24, 2023Large language models (LLMs) can use in-context demonstrations to improve performance on zero-shot tasks. However, selecting the best in-context examples is challenging because model performance can vary widely depending on the selected examples. We present a cross-entropy difference (CED) method for selecting in-context demonstrations. Our method is based on the observation that the effectiveness of in-context demonstrations negatively correlates with the perplexity of the test example by a language model that was finetuned on that demonstration. We utilize parameter efficient finetuning to train small models on training data that are used for computing the cross-entropy difference between a test example and every candidate in-context demonstration. This metric is used to rank and select in-context demonstrations independently for each test input. We evaluate our method on a mix-domain dataset that combines 8 benchmarks, representing 4 text generation tasks, showing that CED for in-context demonstration selection can improve performance for a variety of LLMs.
LMGQS: A Large-scale Dataset for Query-focused Summarization
May 22, 2023



Query-focused summarization (QFS) aims to extract or generate a summary of an input document that directly answers or is relevant to a given query. The lack of large-scale datasets in the form of documents, queries, and summaries has hindered model development in this area. In contrast, multiple large-scale high-quality datasets for generic summarization exist. We hypothesize that there is a hidden query for each summary sentence in a generic summarization annotation, and we utilize a large-scale pretrained language model to recover it. In this way, we convert four generic summarization benchmarks into a new QFS benchmark dataset, LMGQS, which consists of over 1 million document-query-summary samples. We thoroughly investigate the properties of our proposed dataset and establish baselines with state-of-the-art summarization models. By fine-tuning a language model on LMGQS, we achieve state-of-the-art zero-shot and supervised performance on multiple existing QFS benchmarks, demonstrating the high quality and diversity of LMGQS.
InheritSumm: A General, Versatile and Compact Summarizer by Distilling from GPT
May 22, 2023While large models such as GPT-3 demonstrate exceptional performance in zeroshot and fewshot summarization tasks, their extensive serving and fine-tuning costs hinder their utilization in various applications. Conversely, previous studies have found that although automatic metrics tend to favor smaller fine-tuned models, the quality of the summaries they generate is inferior to that of larger models like GPT-3 when assessed by human evaluators. To address this issue, we propose InheritSumm, a versatile and compact summarization model derived from GPT-3.5 through distillation. InheritSumm not only exhibits comparable zeroshot and fewshot summarization capabilities to GPT-3.5 but is also sufficiently compact for fine-tuning purposes. Experimental results demonstrate that InheritSumm achieves similar or superior performance to GPT-3.5 in zeroshot and fewshot settings. Furthermore, it outperforms the previously established best small models in both prefix-tuning and full-data fine-tuning scenarios.
Automatic Prompt Optimization with "Gradient Descent" and Beam Search
May 04, 2023Large Language Models (LLMs) have shown impressive performance as general purpose agents, but their abilities remain highly dependent on prompts which are hand written with onerous trial-and-error effort. We propose a simple and nonparametric solution to this problem, Automatic Prompt Optimization (APO), which is inspired by numerical gradient descent to automatically improve prompts, assuming access to training data and an LLM API. The algorithm uses minibatches of data to form natural language ``gradients'' that criticize the current prompt. The gradients are then ``propagated'' into the prompt by editing the prompt in the opposite semantic direction of the gradient. These gradient descent steps are guided by a beam search and bandit selection procedure which significantly improves algorithmic efficiency. Preliminary results across three benchmark NLP tasks and the novel problem of LLM jailbreak detection suggest that Automatic Prompt Optimization can outperform prior prompt editing techniques and improve an initial prompt's performance by up to 31\%, by using data to rewrite vague task descriptions into more precise annotation instructions.
G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment
Apr 06, 2023The quality of texts generated by natural language generation (NLG) systems is hard to measure automatically. Conventional reference-based metrics, such as BLEU and ROUGE, have been shown to have relatively low correlation with human judgments, especially for tasks that require creativity and diversity. Recent studies suggest using large language models (LLMs) as reference-free metrics for NLG evaluation, which have the benefit of being applicable to new tasks that lack human references. However, these LLM-based evaluators still have lower human correspondence than medium-size neural evaluators. In this work, we present G-Eval, a framework of using large language models with chain-of-thoughts (CoT) and a form-filling paradigm, to assess the quality of NLG outputs. We experiment with two generation tasks, text summarization and dialogue generation. We show that G-Eval with GPT-4 as the backbone model achieves a Spearman correlation of 0.514 with human on summarization task, outperforming all previous methods by a large margin. We also propose preliminary analysis on the behavior of LLM-based evaluators, and highlight the potential issue of LLM-based evaluators having a bias towards the LLM-generated texts.
How Does In-Context Learning Help Prompt Tuning?
Feb 22, 2023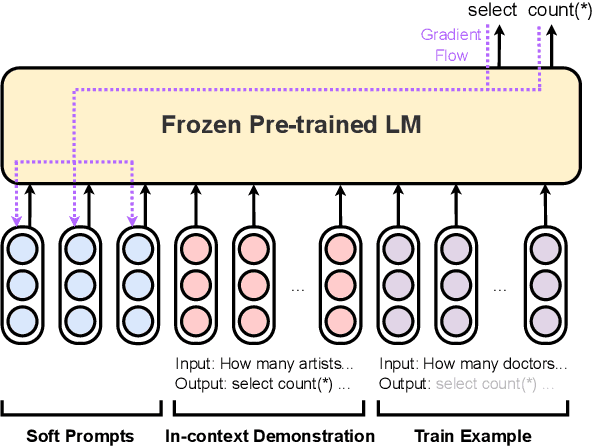
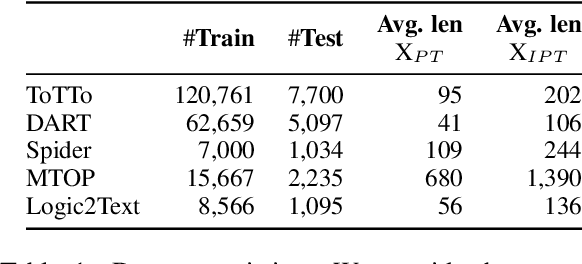
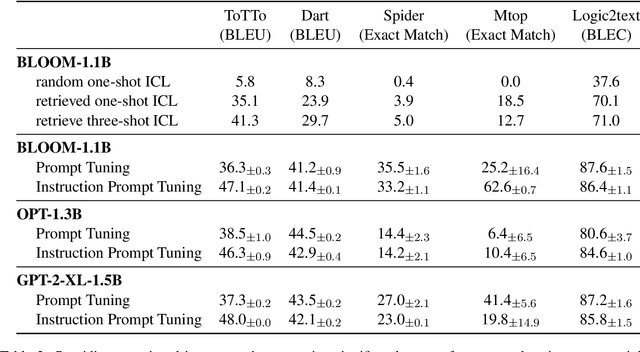
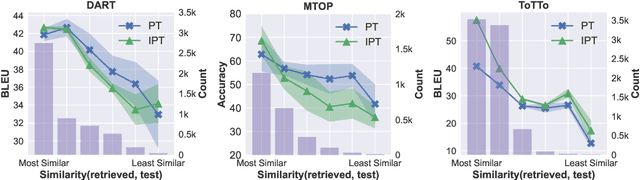
Fine-tuning large language models is becoming ever more impractical due to their rapidly-growing scale. This motivates the use of parameter-efficient adaptation methods such as prompt tuning (PT), which adds a small number of tunable embeddings to an otherwise frozen model, and in-context learning (ICL), in which demonstrations of the task are provided to the model in natural language without any additional training. Recently, Singhal et al. (2022) propose ``instruction prompt tuning'' (IPT), which combines PT with ICL by concatenating a natural language demonstration with learned prompt embeddings. While all of these methods have proven effective on different tasks, how they interact with each other remains unexplored. In this paper, we empirically study when and how in-context examples improve prompt tuning by measuring the effectiveness of ICL, PT, and IPT on five text generation tasks with multiple base language models. We observe that (1) IPT does \emph{not} always outperform PT, and in fact requires the in-context demonstration to be semantically similar to the test input to yield improvements; (2) PT is unstable and exhibits high variance, but combining PT and ICL (into IPT) consistently reduces variance across all five tasks; and (3) prompts learned for a specific source task via PT exhibit positive transfer when paired with in-context examples of a different target task. Our results offer actionable insights on choosing a suitable parameter-efficient adaptation method for a given task.
Generate rather than Retrieve: Large Language Models are Strong Context Generators
Sep 29, 2022
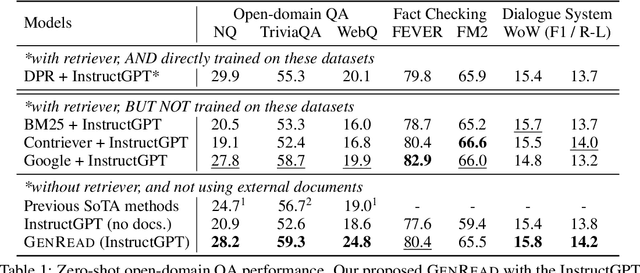
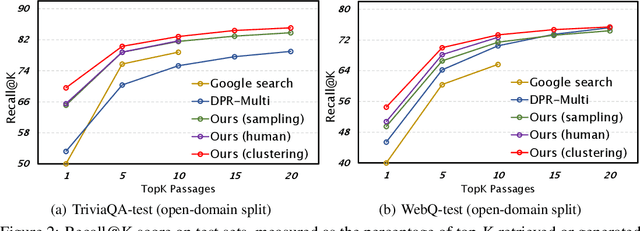
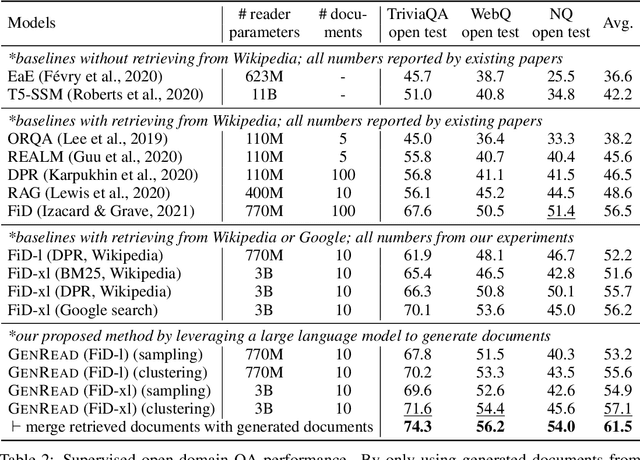
Knowledge-intensive tasks, such as open-domain question answering (QA), require access to a large amount of world or domain knowledge. A common approach for knowledge-intensive tasks is to employ a retrieve-then-read pipeline that first retrieves a handful of relevant contextual documents from an external corpus such as Wikipedia and then predicts an answer conditioned on the retrieved documents. In this paper, we present a novel perspective for solving knowledge-intensive tasks by replacing document retrievers with large language model generators. We call our method generate-then-read (GenRead), which first prompts a large language model to generate contextutal documents based on a given question, and then reads the generated documents to produce the final answer. Furthermore, we propose a novel clustering-based prompting method that selects distinct prompts, resulting in the generated documents that cover different perspectives, leading to better recall over acceptable answers. We conduct extensive experiments on three different knowledge-intensive tasks, including open-domain QA, fact checking, and dialogue system. Notably, GenRead achieves 71.6 and 54.4 exact match scores on TriviaQA and WebQ, significantly outperforming the state-of-the-art retrieve-then-read pipeline DPR-FiD by +4.0 and +3.9, without retrieving any documents from any external knowledge source. Lastly, we demonstrate the model performance can be further improved by combining retrieval and generation.