 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Mar 03, 2025



We introduce Phi-4-Mini and Phi-4-Multimodal, compact yet highly capable language and multimodal models. Phi-4-Mini is a 3.8-billion-parameter language model trained on high-quality web and synthetic data, significantly outperforming recent open-source models of similar size and matching the performance of models twice its size on math and coding tasks requiring complex reasoning. This achievement is driven by a carefully curated synthetic data recipe emphasizing high-quality math and coding datasets. Compared to its predecessor, Phi-3.5-Mini, Phi-4-Mini features an expanded vocabulary size of 200K tokens to better support multilingual applications, as well as group query attention for more efficient long-sequence generation. Phi-4-Multimodal is a multimodal model that integrates text, vision, and speech/audio input modalities into a single model. Its novel modality extension approach leverages LoRA adapters and modality-specific routers to allow multiple inference modes combining various modalities without interference. For example, it now ranks first in the OpenASR leaderboard to date, although the LoRA component of the speech/audio modality has just 460 million parameters. Phi-4-Multimodal supports scenarios involving (vision + language), (vision + speech), and (speech/audio) inputs, outperforming larger vision-language and speech-language models on a wide range of tasks. Additionally, we experiment to further train Phi-4-Mini to enhance its reasoning capabilities. Despite its compact 3.8-billion-parameter size, this experimental version achieves reasoning performance on par with or surpassing significantly larger models, including DeepSeek-R1-Distill-Qwen-7B and DeepSeek-R1-Distill-Llama-8B.
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Apr 23, 2024



We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).
Visual Clues: Bridging Vision and Language Foundations for Image Paragraph Captioning
Jun 03, 2022

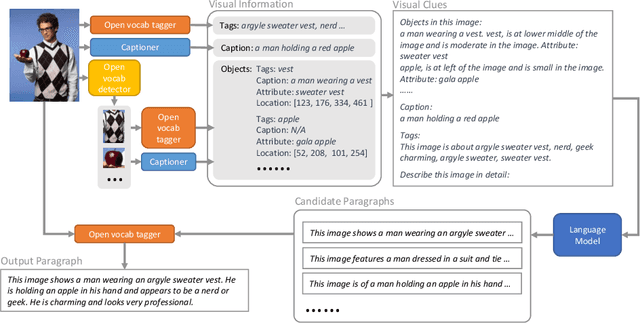

People say, "A picture is worth a thousand words". Then how can we get the rich information out of the image? We argue that by using visual clues to bridge large pretrained vision foundation models and language models, we can do so without any extra cross-modal training. Thanks to the strong zero-shot capability of foundation models, we start by constructing a rich semantic representation of the image (e.g., image tags, object attributes / locations, captions) as a structured textual prompt, called visual clues, using a vision foundation model. Based on visual clues, we use large language model to produce a series of comprehensive descriptions for the visual content, which is then verified by the vision model again to select the candidate that aligns best with the image. We evaluate the quality of generated descriptions by quantitative and qualitative measurement. The results demonstrate the effectiveness of such a structured semantic representation.
ITA: Image-Text Alignments for Multi-Modal Named Entity Recognition
Dec 13, 2021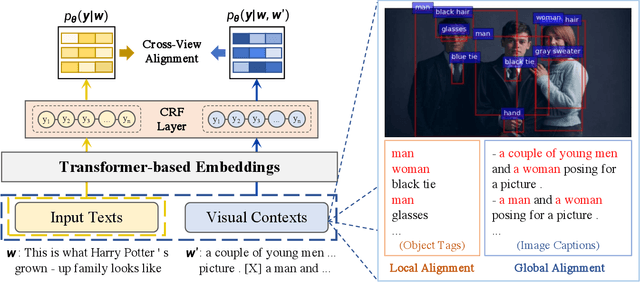
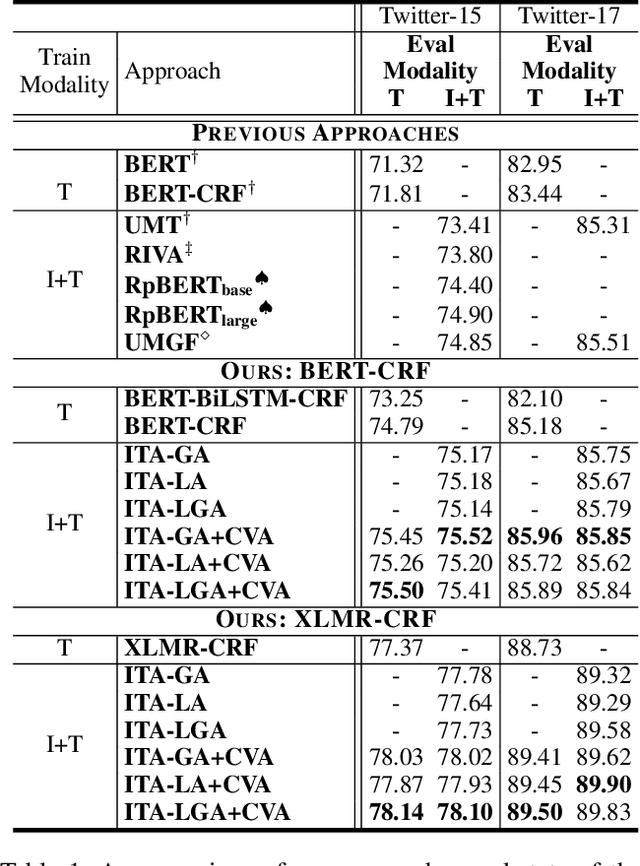
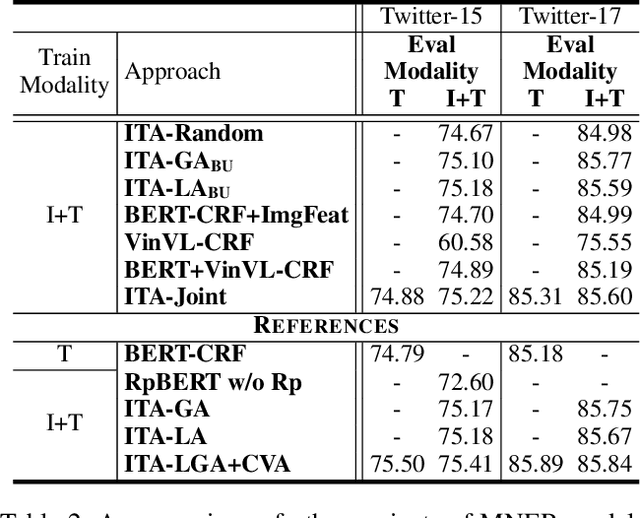
Recently, Multi-modal Named Entity Recognition (MNER) has attracted a lot of attention. Most of the work utilizes image information through region-level visual representations obtained from a pretrained object detector and relies on an attention mechanism to model the interactions between image and text representations. However, it is difficult to model such interactions as image and text representations are trained separately on the data of their respective modality and are not aligned in the same space. As text representations take the most important role in MNER, in this paper, we propose {\bf I}mage-{\bf t}ext {\bf A}lignments (ITA) to align image features into the textual space, so that the attention mechanism in transformer-based pretrained textual embeddings can be better utilized. ITA first locally and globally aligns regional object tags and image-level captions as visual contexts, concatenates them with the input texts as a new cross-modal input, and then feeds it into a pretrained textual embedding model. This makes it easier for the attention module of a pretrained textual embedding model to model the interaction between the two modalities since they are both represented in the textual space. ITA further aligns the output distributions predicted from the cross-modal input and textual input views so that the MNER model can be more practical and robust to noises from images. In our experiments, we show that ITA models can achieve state-of-the-art accuracy on multi-modal Named Entity Recognition datasets, even without image information.
MuVER: Improving First-Stage Entity Retrieval with Multi-View Entity Representations
Sep 13, 2021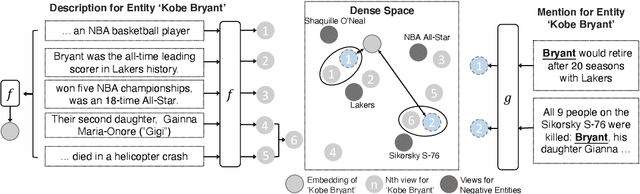



Entity retrieval, which aims at disambiguating mentions to canonical entities from massive KBs, is essential for many tasks in natural language processing. Recent progress in entity retrieval shows that the dual-encoder structure is a powerful and efficient framework to nominate candidates if entities are only identified by descriptions. However, they ignore the property that meanings of entity mentions diverge in different contexts and are related to various portions of descriptions, which are treated equally in previous works. In this work, we propose Multi-View Entity Representations (MuVER), a novel approach for entity retrieval that constructs multi-view representations for entity descriptions and approximates the optimal view for mentions via a heuristic searching method. Our method achieves the state-of-the-art performance on ZESHEL and improves the quality of candidates on three standard Entity Linking datasets
Improving Named Entity Recognition by External Context Retrieving and Cooperative Learning
Jun 02, 2021
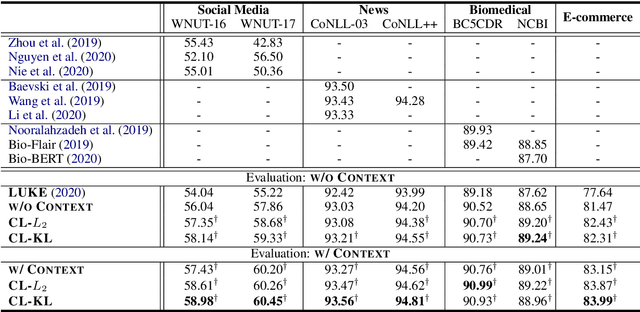

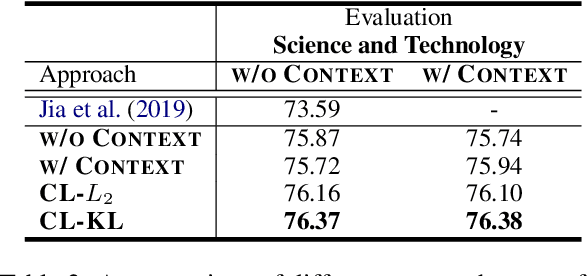
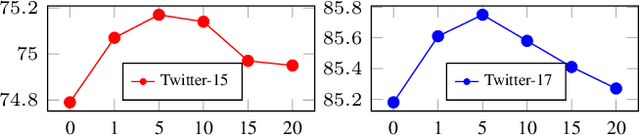
Recent advances in Named Entity Recognition (NER) show that document-level contexts can significantly improve model performance. In many application scenarios, however, such contexts are not available. In this paper, we propose to find external contexts of a sentence by retrieving and selecting a set of semantically relevant texts through a search engine, with the original sentence as the query. We find empirically that the contextual representations computed on the retrieval-based input view, constructed through the concatenation of a sentence and its external contexts, can achieve significantly improved performance compared to the original input view based only on the sentence. Furthermore, we can improve the model performance of both input views by Cooperative Learning, a training method that encourages the two input views to produce similar contextual representations or output label distributions. Experiments show that our approach can achieve new state-of-the-art performance on 8 NER data sets across 5 domains.
An Investigation of Potential Function Designs for Neural CRF
Nov 11, 2020


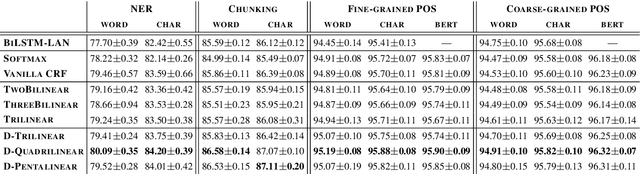
The neural linear-chain CRF model is one of the most widely-used approach to sequence labeling. In this paper, we investigate a series of increasingly expressive potential functions for neural CRF models, which not only integrate the emission and transition functions, but also explicitly take the representations of the contextual words as input. Our extensive experiments show that the decomposed quadrilinear potential function based on the vector representations of two neighboring labels and two neighboring words consistently achieves the best performance.
AIN: Fast and Accurate Sequence Labeling with Approximate Inference Network
Oct 12, 2020

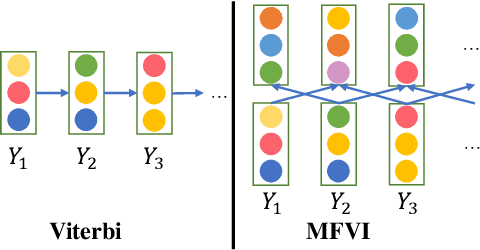

The linear-chain Conditional Random Field (CRF) model is one of the most widely-used neural sequence labeling approaches. Exact probabilistic inference algorithms such as the forward-backward and Viterbi algorithms are typically applied in training and prediction stages of the CRF model. However, these algorithms require sequential computation that makes parallelization impossible. In this paper, we propose to employ a parallelizable approximate variational inference algorithm for the CRF model. Based on this algorithm, we design an approximate inference network that can be connected with the encoder of the neural CRF model to form an end-to-end network, which is amenable to parallelization for faster training and prediction. The empirical results show that our proposed approaches achieve a 12.7-fold improvement in decoding speed with long sentences and a competitive accuracy compared with the traditional CRF approach.
Structural Knowledge Distillation
Oct 10, 2020

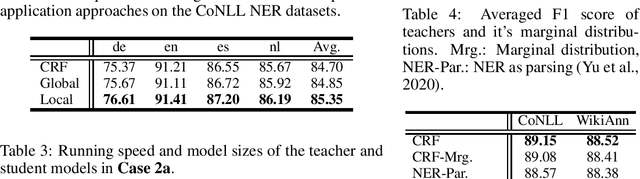
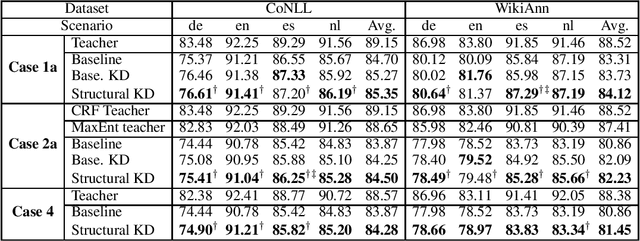
Knowledge distillation is a critical technique to transfer knowledge between models, typically from a large model (the teacher) to a smaller one (the student). The objective function of knowledge distillation is typically the cross-entropy between the teacher and the student's output distributions. However, for structured prediction problems, the output space is exponential in size; therefore, the cross-entropy objective becomes intractable to compute and optimize directly. In this paper, we derive a factorized form of the knowledge distillation objective for structured prediction, which is tractable for many typical choices of the teacher and student models. In particular, we show the tractability and empirical effectiveness of structural knowledge distillation between sequence labeling and dependency parsing models under four different scenarios: 1) the teacher and student share the same factorization form of the output structure scoring function; 2) the student factorization produces smaller substructures than the teacher factorization; 3) the teacher factorization produces smaller substructures than the student factorization; 4) the factorization forms from the teacher and the student are incompatible.
Automated Concatenation of Embeddings for Structured Prediction
Oct 10, 2020
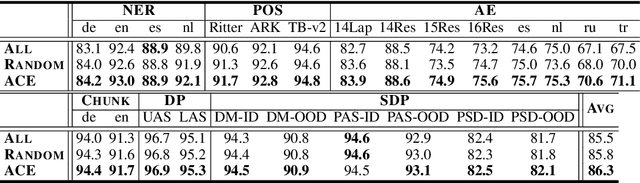


Pretrained contextualized embeddings are powerful word representations for structured prediction tasks. Recent work found that better word representations can be obtained by concatenating different types of embeddings. However, the selection of embeddings to form the best concatenated representation usually varies depending on the task and the collection of candidate embeddings, and the ever-increasing number of embedding types makes it a more difficult problem. In this paper, we propose Automated Concatenation of Embeddings (ACE) to automate the process of finding better concatenations of embeddings for structured prediction tasks, based on a formulation inspired by recent progress on neural architecture search. Specifically, a controller alternately samples a concatenation of embeddings, according to its current belief of the effectiveness of individual embedding types in consideration for a task, and updates the belief based on a reward. We follow strategies in reinforcement learning to optimize the parameters of the controller and compute the reward based on the accuracy of a task model, which is fed with the sampled concatenation as input and trained on a task dataset. Empirical results on 6 tasks and 23 datasets show that our approach outperforms strong baselines and achieves state-of-the-art performance with fine-tuned embeddings in the vast majority of evaluations.