 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvisible Safety Threat: Malicious Finetuning for LLM via Steganography
Mar 09, 2026Understanding and addressing potential safety alignment risks in large language models (LLMs) is critical for ensuring their safe and trustworthy deployment. In this paper, we highlight an insidious safety threat: a compromised LLM can maintain a facade of proper safety alignment while covertly generating harmful content. To achieve this, we finetune the model to understand and apply a steganographic technique. At inference time, we input a prompt that contains a steganographically embedded malicious target question along with a plaintext cover question. The model, in turn, produces a target response similarly embedded within a benign-looking cover response. In this process, human observers only see the model being prompted with a cover question and generating a corresponding cover response, while the malicious content is hidden from view. We demonstrate this invisible safety threat on GPT-4.1 despite the OpenAI finetuning API's safeguards. The finetuned model produces steganographic malicious outputs in response to hidden malicious prompts, while the user interface displays only a fully benign cover interaction. We also replicate the attack on three open-source models, Llama-3.3-70B-Instruct, Phi-4, and Mistral-Small-24B-Base-2501, confirming the generality of our method. We quantitatively evaluate our method on the AdvBench dataset, using Llama-Guard-3-8B for content safety classification. Across all four models, all stegotexts containing malicious content are incorrectly classified as safe.
Self-Purification Mitigates Backdoors in Multimodal Diffusion Language Models
Feb 24, 2026Multimodal Diffusion Language Models (MDLMs) have recently emerged as a competitive alternative to their autoregressive counterparts. Yet their vulnerability to backdoor attacks remains largely unexplored. In this work, we show that well-established data-poisoning pipelines can successfully implant backdoors into MDLMs, enabling attackers to manipulate model behavior via specific triggers while maintaining normal performance on clean inputs. However, defense strategies effective to these models are yet to emerge. To bridge this gap, we introduce a backdoor defense framework for MDLMs named DiSP (Diffusion Self-Purification). DiSP is driven by a key observation: selectively masking certain vision tokens at inference time can neutralize a backdoored model's trigger-induced behaviors and restore normal functionality. Building on this, we purify the poisoned dataset using the compromised model itself, then fine-tune the model on the purified data to recover it to a clean one. Given such a specific design, DiSP can remove backdoors without requiring any auxiliary models or clean reference data. Extensive experiments demonstrate that our approach effectively mitigates backdoor effects, reducing the attack success rate (ASR) from over 90% to typically under 5%, while maintaining model performance on benign tasks.
dVoting: Fast Voting for dLLMs
Feb 12, 2026Diffusion Large Language Models (dLLMs) represent a new paradigm beyond autoregressive modeling, offering competitive performance while naturally enabling a flexible decoding process. Specifically, dLLMs can generate tokens at arbitrary positions in parallel, endowing them with significant potential for parallel test-time scaling, which was previously constrained by severe inefficiency in autoregressive modeling. In this work, we introduce dVoting, a fast voting technique that boosts reasoning capability without training, with only an acceptable extra computational overhead. dVoting is motivated by the observation that, across multiple samples for the same prompt, token predictions remain largely consistent, whereas performance is determined by a small subset of tokens exhibiting cross-sample variability. Leveraging the arbitrary-position generation capability of dLLMs, dVoting performs iterative refinement by sampling, identifying uncertain tokens via consistency analysis, regenerating them through voting, and repeating this process until convergence. Extensive evaluations demonstrate that dVoting consistently improves performance across various benchmarks. It achieves gains of 6.22%-7.66% on GSM8K, 4.40%-7.20% on MATH500, 3.16%-14.84% on ARC-C, and 4.83%-5.74% on MMLU. Our code is available at https://github.com/fscdc/dVoting
dParallel: Learnable Parallel Decoding for dLLMs
Sep 30, 2025
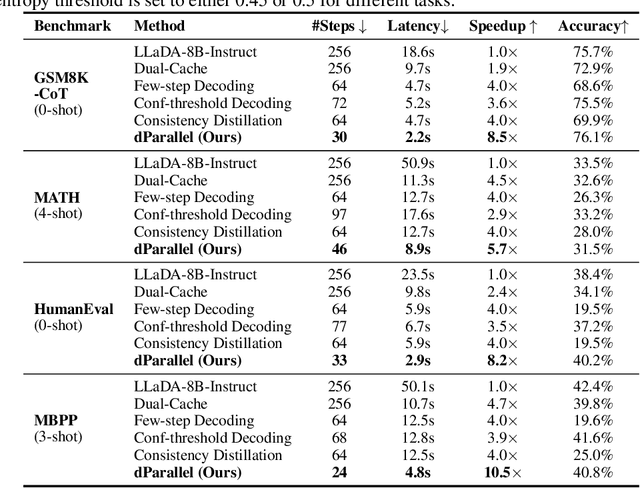
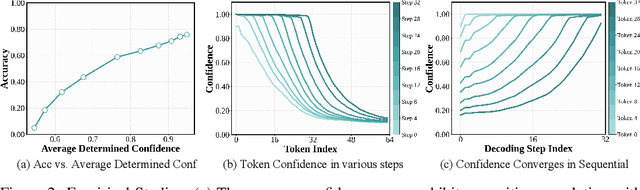
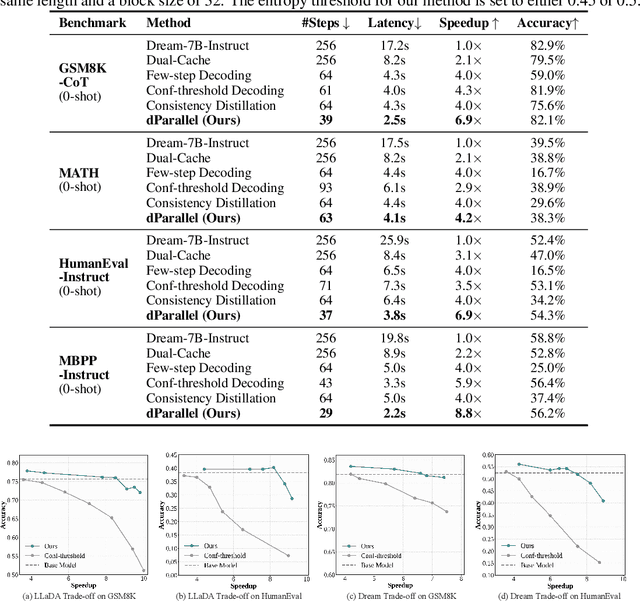
Diffusion large language models (dLLMs) have recently drawn considerable attention within the research community as a promising alternative to autoregressive generation, offering parallel token prediction and lower inference latency. Yet, their parallel decoding potential remains largely underexplored, as existing open-source models still require nearly token-length decoding steps to ensure performance. To address this, we introduce dParallel, a simple and effective method that unlocks the inherent parallelism of dLLMs for fast sampling. We identify that the key bottleneck to parallel decoding arises from the sequential certainty convergence for masked tokens. Building on this insight, we introduce the core of our approach: certainty-forcing distillation, a novel training strategy that distills the model to follow its original sampling trajectories while enforcing it to achieve high certainty on masked tokens more rapidly and in parallel. Extensive experiments across various benchmarks demonstrate that our method can dramatically reduce the number of decoding steps while maintaining performance. When applied to the LLaDA-8B-Instruct model, dParallel reduces decoding steps from 256 to 30 on GSM8K, achieving an 8.5x speedup without performance degradation. On the MBPP benchmark, it cuts decoding steps from 256 to 24, resulting in a 10.5x speedup while maintaining accuracy. Our code is available at https://github.com/czg1225/dParallel
ConciseHint: Boosting Efficient Reasoning via Continuous Concise Hints during Generation
Jun 24, 2025Recent advancements in large reasoning models (LRMs) like DeepSeek-R1 and OpenAI o1 series have achieved notable performance enhancements on complex reasoning tasks by scaling up the generation length by Chain-of-Thought (CoT). However, an emerging issue is their inclination to produce excessively verbose reasoning processes, leading to the inefficiency problem. Existing literature on improving efficiency mainly adheres to the before-reasoning paradigms such as prompting and reasoning or fine-tuning and reasoning, but ignores the promising direction of directly encouraging the model to speak concisely by intervening during the generation of reasoning. In order to fill the blank, we propose a framework dubbed ConciseHint, which continuously encourages the reasoning model to speak concisely by injecting the textual hint (manually designed or trained on the concise data) during the token generation of the reasoning process. Besides, ConciseHint is adaptive to the complexity of the query by adaptively adjusting the hint intensity, which ensures it will not undermine model performance. Experiments on the state-of-the-art LRMs, including DeepSeek-R1 and Qwen-3 series, demonstrate that our method can effectively produce concise reasoning processes while maintaining performance well. For instance, we achieve a reduction ratio of 65\% for the reasoning length on GSM8K benchmark with Qwen-3 4B with nearly no accuracy loss.
VeriThinker: Learning to Verify Makes Reasoning Model Efficient
May 23, 2025Large Reasoning Models (LRMs) excel at complex tasks using Chain-of-Thought (CoT) reasoning. However, their tendency to overthinking leads to unnecessarily lengthy reasoning chains, dramatically increasing inference costs. To mitigate this issue, we introduce VeriThinker, a novel approach for CoT compression. Unlike conventional methods that fine-tune LRMs directly on the original reasoning task using synthetic concise CoT data, we innovatively fine-tune the model solely through an auxiliary verification task. By training LRMs to accurately verify the correctness of CoT solutions, the LRMs inherently become more discerning about the necessity of subsequent self-reflection steps, thereby effectively suppressing overthinking. Extensive experiments validate that VeriThinker substantially reduces reasoning chain lengths while maintaining or even slightly improving accuracy. When applied to DeepSeek-R1-Distill-Qwen-7B, our approach reduces reasoning tokens on MATH500 from 3790 to 2125 while improving accuracy by 0.8% (94.0% to 94.8%), and on AIME25, tokens decrease from 14321 to 10287 with a 2.1% accuracy gain (38.7% to 40.8%). Additionally, our experiments demonstrate that VeriThinker can also be zero-shot generalized to speculative reasoning. Code is available at https://github.com/czg1225/VeriThinker
Dimple: Discrete Diffusion Multimodal Large Language Model with Parallel Decoding
May 22, 2025In this work, we propose Dimple, the first Discrete Diffusion Multimodal Large Language Model (DMLLM). We observe that training with a purely discrete diffusion approach leads to significant training instability, suboptimal performance, and severe length bias issues. To address these challenges, we design a novel training paradigm that combines an initial autoregressive phase with a subsequent diffusion phase. This approach yields the Dimple-7B model, trained on the same dataset and using a similar training pipeline as LLaVA-NEXT. Dimple-7B ultimately surpasses LLaVA-NEXT in performance by 3.9%, demonstrating that DMLLM can achieve performance comparable to that of autoregressive models. To improve inference efficiency, we propose a decoding strategy termed confident decoding, which dynamically adjusts the number of tokens generated at each step, significantly reducing the number of generation iterations. In autoregressive models, the number of forward iterations during generation equals the response length. With confident decoding, however, the number of iterations needed by Dimple is even only $\frac{\text{response length}}{3}$. We also re-implement the prefilling technique in autoregressive models and demonstrate that it does not significantly impact performance on most benchmark evaluations, while offering a speedup of 1.5x to 7x. Additionally, we explore Dimple's capability to precisely control its response using structure priors. These priors enable structured responses in a manner distinct from instruction-based or chain-of-thought prompting, and allow fine-grained control over response format and length, which is difficult to achieve in autoregressive models. Overall, this work validates the feasibility and advantages of DMLLM and enhances its inference efficiency and controllability. Code and models are available at https://github.com/yu-rp/Dimple.
dKV-Cache: The Cache for Diffusion Language Models
May 21, 2025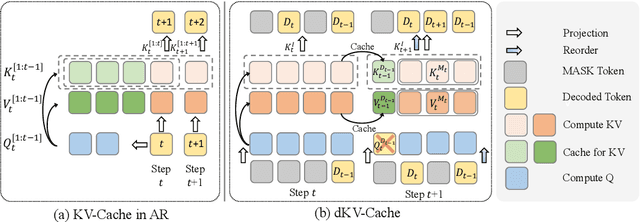
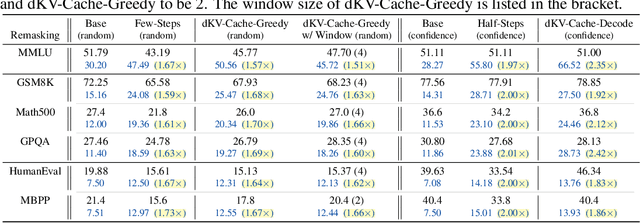
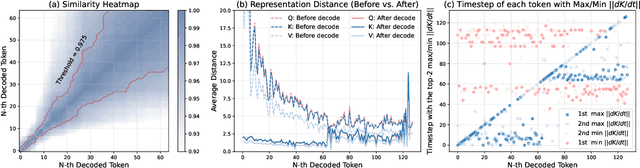
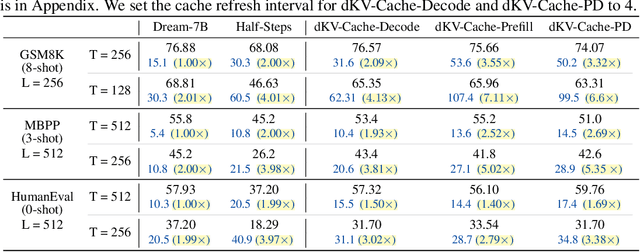
Diffusion Language Models (DLMs) have been seen as a promising competitor for autoregressive language models. However, diffusion language models have long been constrained by slow inference. A core challenge is that their non-autoregressive architecture and bidirectional attention preclude the key-value cache that accelerates decoding. We address this bottleneck by proposing a KV-cache-like mechanism, delayed KV-Cache, for the denoising process of DLMs. Our approach is motivated by the observation that different tokens have distinct representation dynamics throughout the diffusion process. Accordingly, we propose a delayed and conditioned caching strategy for key and value states. We design two complementary variants to cache key and value step-by-step: (1) dKV-Cache-Decode, which provides almost lossless acceleration, and even improves performance on long sequences, suggesting that existing DLMs may under-utilise contextual information during inference. (2) dKV-Cache-Greedy, which has aggressive caching with reduced lifespan, achieving higher speed-ups with quadratic time complexity at the cost of some performance degradation. dKV-Cache, in final, achieves from 2-10x speedup in inference, largely narrowing the gap between ARs and DLMs. We evaluate our dKV-Cache on several benchmarks, delivering acceleration across general language understanding, mathematical, and code-generation benchmarks. Experiments demonstrate that cache can also be used in DLMs, even in a training-free manner from current DLMs.
Thinkless: LLM Learns When to Think
May 19, 2025Reasoning Language Models, capable of extended chain-of-thought reasoning, have demonstrated remarkable performance on tasks requiring complex logical inference. However, applying elaborate reasoning for all queries often results in substantial computational inefficiencies, particularly when many problems admit straightforward solutions. This motivates an open question: Can LLMs learn when to think? To answer this, we propose Thinkless, a learnable framework that empowers an LLM to adaptively select between short-form and long-form reasoning, based on both task complexity and the model's ability. Thinkless is trained under a reinforcement learning paradigm and employs two control tokens, <short> for concise responses and <think> for detailed reasoning. At the core of our method is a Decoupled Group Relative Policy Optimization (DeGRPO) algorithm, which decomposes the learning objective of hybrid reasoning into two components: (1) a control token loss that governs the selection of the reasoning mode, and (2) a response loss that improves the accuracy of the generated answers. This decoupled formulation enables fine-grained control over the contributions of each objective, stabilizing training and effectively preventing collapse observed in vanilla GRPO. Empirically, on several benchmarks such as Minerva Algebra, MATH-500, and GSM8K, Thinkless is able to reduce the usage of long-chain thinking by 50% - 90%, significantly improving the efficiency of Reasoning Language Models. The code is available at https://github.com/VainF/Thinkless
Efficient Reasoning Models: A Survey
Apr 15, 2025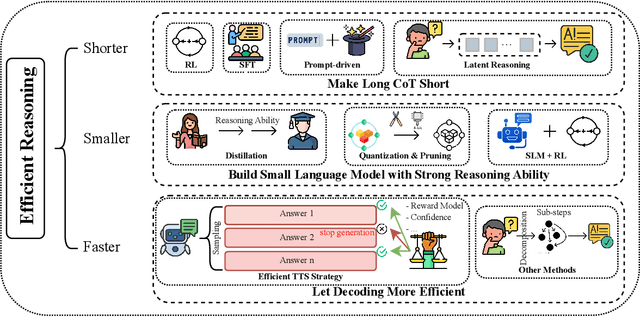
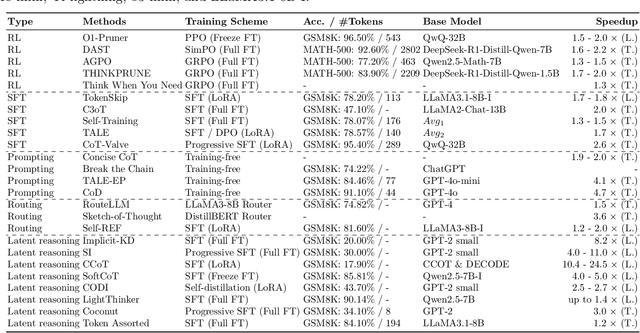
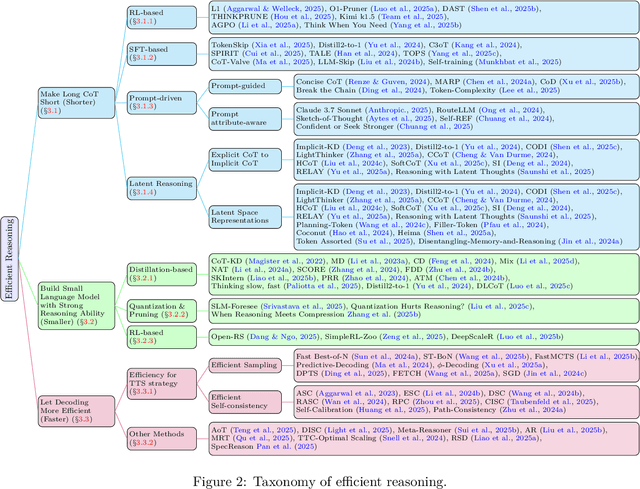
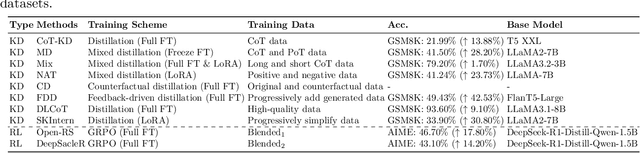
Reasoning models have demonstrated remarkable progress in solving complex and logic-intensive tasks by generating extended Chain-of-Thoughts (CoTs) prior to arriving at a final answer. Yet, the emergence of this "slow-thinking" paradigm, with numerous tokens generated in sequence, inevitably introduces substantial computational overhead. To this end, it highlights an urgent need for effective acceleration. This survey aims to provide a comprehensive overview of recent advances in efficient reasoning. It categorizes existing works into three key directions: (1) shorter - compressing lengthy CoTs into concise yet effective reasoning chains; (2) smaller - developing compact language models with strong reasoning capabilities through techniques such as knowledge distillation, other model compression techniques, and reinforcement learning; and (3) faster - designing efficient decoding strategies to accelerate inference. A curated collection of papers discussed in this survey is available in our GitHub repository.