 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgedParallel: Learnable Parallel Decoding for dLLMs
Sep 30, 2025
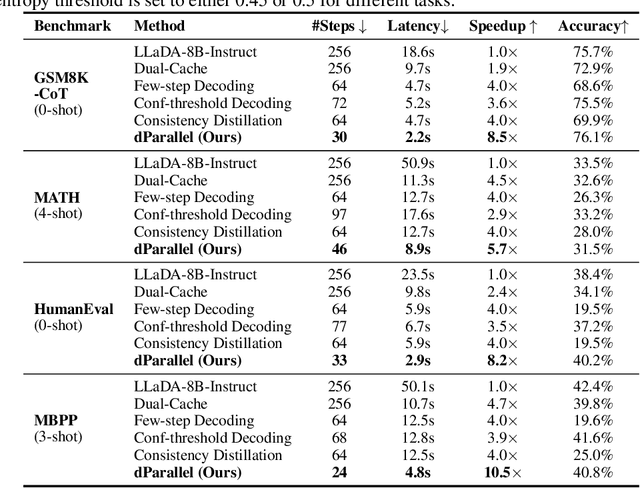
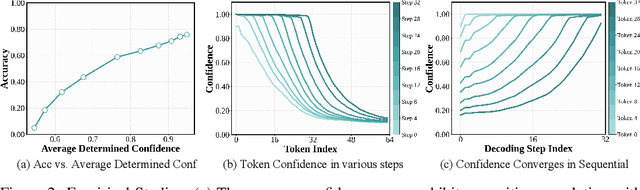
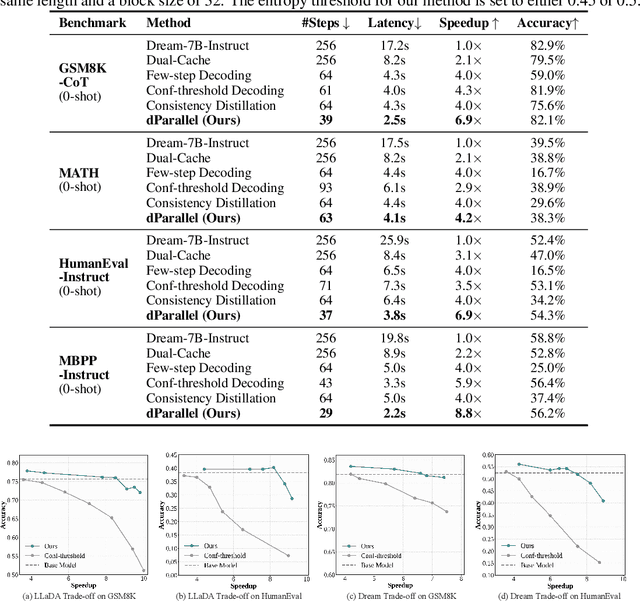
Diffusion large language models (dLLMs) have recently drawn considerable attention within the research community as a promising alternative to autoregressive generation, offering parallel token prediction and lower inference latency. Yet, their parallel decoding potential remains largely underexplored, as existing open-source models still require nearly token-length decoding steps to ensure performance. To address this, we introduce dParallel, a simple and effective method that unlocks the inherent parallelism of dLLMs for fast sampling. We identify that the key bottleneck to parallel decoding arises from the sequential certainty convergence for masked tokens. Building on this insight, we introduce the core of our approach: certainty-forcing distillation, a novel training strategy that distills the model to follow its original sampling trajectories while enforcing it to achieve high certainty on masked tokens more rapidly and in parallel. Extensive experiments across various benchmarks demonstrate that our method can dramatically reduce the number of decoding steps while maintaining performance. When applied to the LLaDA-8B-Instruct model, dParallel reduces decoding steps from 256 to 30 on GSM8K, achieving an 8.5x speedup without performance degradation. On the MBPP benchmark, it cuts decoding steps from 256 to 24, resulting in a 10.5x speedup while maintaining accuracy. Our code is available at https://github.com/czg1225/dParallel
VeriThinker: Learning to Verify Makes Reasoning Model Efficient
May 23, 2025Large Reasoning Models (LRMs) excel at complex tasks using Chain-of-Thought (CoT) reasoning. However, their tendency to overthinking leads to unnecessarily lengthy reasoning chains, dramatically increasing inference costs. To mitigate this issue, we introduce VeriThinker, a novel approach for CoT compression. Unlike conventional methods that fine-tune LRMs directly on the original reasoning task using synthetic concise CoT data, we innovatively fine-tune the model solely through an auxiliary verification task. By training LRMs to accurately verify the correctness of CoT solutions, the LRMs inherently become more discerning about the necessity of subsequent self-reflection steps, thereby effectively suppressing overthinking. Extensive experiments validate that VeriThinker substantially reduces reasoning chain lengths while maintaining or even slightly improving accuracy. When applied to DeepSeek-R1-Distill-Qwen-7B, our approach reduces reasoning tokens on MATH500 from 3790 to 2125 while improving accuracy by 0.8% (94.0% to 94.8%), and on AIME25, tokens decrease from 14321 to 10287 with a 2.1% accuracy gain (38.7% to 40.8%). Additionally, our experiments demonstrate that VeriThinker can also be zero-shot generalized to speculative reasoning. Code is available at https://github.com/czg1225/VeriThinker
Ultra-Resolution Adaptation with Ease
Mar 20, 2025Text-to-image diffusion models have achieved remarkable progress in recent years. However, training models for high-resolution image generation remains challenging, particularly when training data and computational resources are limited. In this paper, we explore this practical problem from two key perspectives: data and parameter efficiency, and propose a set of key guidelines for ultra-resolution adaptation termed \emph{URAE}. For data efficiency, we theoretically and empirically demonstrate that synthetic data generated by some teacher models can significantly promote training convergence. For parameter efficiency, we find that tuning minor components of the weight matrices outperforms widely-used low-rank adapters when synthetic data are unavailable, offering substantial performance gains while maintaining efficiency. Additionally, for models leveraging guidance distillation, such as FLUX, we show that disabling classifier-free guidance, \textit{i.e.}, setting the guidance scale to 1 during adaptation, is crucial for satisfactory performance. Extensive experiments validate that URAE achieves comparable 2K-generation performance to state-of-the-art closed-source models like FLUX1.1 [Pro] Ultra with only 3K samples and 2K iterations, while setting new benchmarks for 4K-resolution generation. Codes are available \href{https://github.com/Huage001/URAE}{here}.
Teddy: Efficient Large-Scale Dataset Distillation via Taylor-Approximated Matching
Oct 10, 2024Dataset distillation or condensation refers to compressing a large-scale dataset into a much smaller one, enabling models trained on this synthetic dataset to generalize effectively on real data. Tackling this challenge, as defined, relies on a bi-level optimization algorithm: a novel model is trained in each iteration within a nested loop, with gradients propagated through an unrolled computation graph. However, this approach incurs high memory and time complexity, posing difficulties in scaling up to large datasets such as ImageNet. Addressing these concerns, this paper introduces Teddy, a Taylor-approximated dataset distillation framework designed to handle large-scale dataset and enhance efficiency. On the one hand, backed up by theoretical analysis, we propose a memory-efficient approximation derived from Taylor expansion, which transforms the original form dependent on multi-step gradients to a first-order one. On the other hand, rather than repeatedly training a novel model in each iteration, we unveil that employing a pre-cached pool of weak models, which can be generated from a single base model, enhances both time efficiency and performance concurrently, particularly when dealing with large-scale datasets. Extensive experiments demonstrate that the proposed Teddy attains state-of-the-art efficiency and performance on the Tiny-ImageNet and original-sized ImageNet-1K dataset, notably surpassing prior methods by up to 12.8%, while reducing 46.6% runtime. Our code will be available at https://github.com/Lexie-YU/Teddy.
Heavy Labels Out! Dataset Distillation with Label Space Lightening
Aug 15, 2024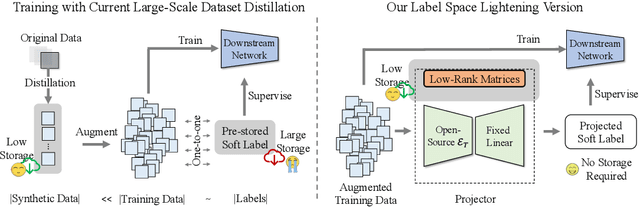


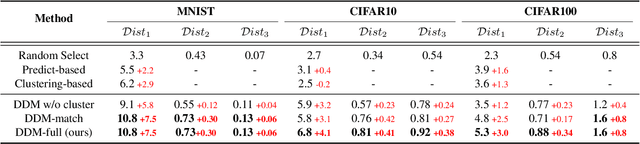
Dataset distillation or condensation aims to condense a large-scale training dataset into a much smaller synthetic one such that the training performance of distilled and original sets on neural networks are similar. Although the number of training samples can be reduced substantially, current state-of-the-art methods heavily rely on enormous soft labels to achieve satisfactory performance. As a result, the required storage can be comparable even to original datasets, especially for large-scale ones. To solve this problem, instead of storing these heavy labels, we propose a novel label-lightening framework termed HeLlO aiming at effective image-to-label projectors, with which synthetic labels can be directly generated online from synthetic images. Specifically, to construct such projectors, we leverage prior knowledge in open-source foundation models, e.g., CLIP, and introduce a LoRA-like fine-tuning strategy to mitigate the gap between pre-trained and target distributions, so that original models for soft-label generation can be distilled into a group of low-rank matrices. Moreover, an effective image optimization method is proposed to further mitigate the potential error between the original and distilled label generators. Extensive experiments demonstrate that with only about 0.003% of the original storage required for a complete set of soft labels, we achieve comparable performance to current state-of-the-art dataset distillation methods on large-scale datasets. Our code will be available.
Distilled Datamodel with Reverse Gradient Matching
Apr 22, 2024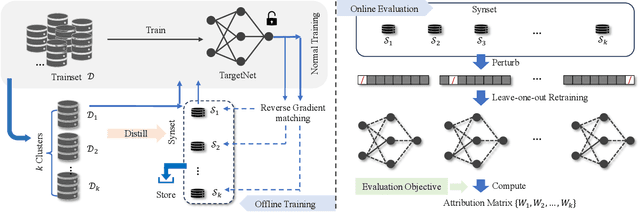
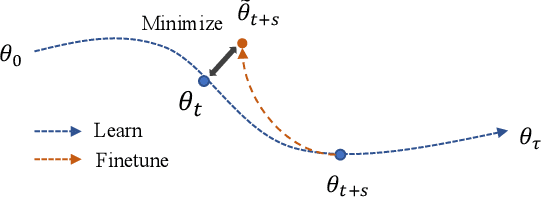
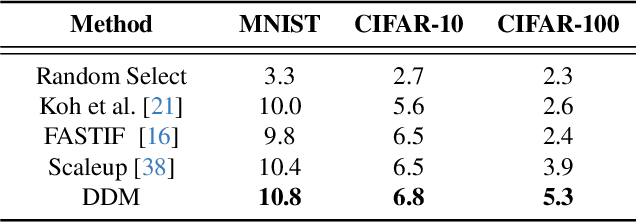
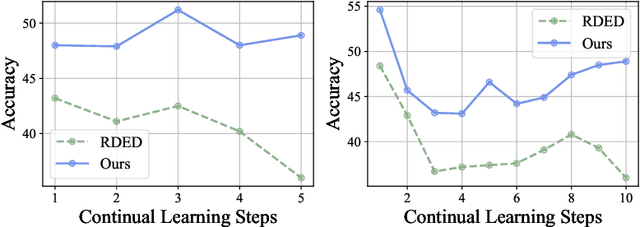
The proliferation of large-scale AI models trained on extensive datasets has revolutionized machine learning. With these models taking on increasingly central roles in various applications, the need to understand their behavior and enhance interpretability has become paramount. To investigate the impact of changes in training data on a pre-trained model, a common approach is leave-one-out retraining. This entails systematically altering the training dataset by removing specific samples to observe resulting changes within the model. However, retraining the model for each altered dataset presents a significant computational challenge, given the need to perform this operation for every dataset variation. In this paper, we introduce an efficient framework for assessing data impact, comprising offline training and online evaluation stages. During the offline training phase, we approximate the influence of training data on the target model through a distilled synset, formulated as a reversed gradient matching problem. For online evaluation, we expedite the leave-one-out process using the synset, which is then utilized to compute the attribution matrix based on the evaluation objective. Experimental evaluations, including training data attribution and assessments of data quality, demonstrate that our proposed method achieves comparable model behavior evaluation while significantly speeding up the process compared to the direct retraining method.
Mutual-modality Adversarial Attack with Semantic Perturbation
Dec 20, 2023



Adversarial attacks constitute a notable threat to machine learning systems, given their potential to induce erroneous predictions and classifications. However, within real-world contexts, the essential specifics of the deployed model are frequently treated as a black box, consequently mitigating the vulnerability to such attacks. Thus, enhancing the transferability of the adversarial samples has become a crucial area of research, which heavily relies on selecting appropriate surrogate models. To address this challenge, we propose a novel approach that generates adversarial attacks in a mutual-modality optimization scheme. Our approach is accomplished by leveraging the pre-trained CLIP model. Firstly, we conduct a visual attack on the clean image that causes semantic perturbations on the aligned embedding space with the other textual modality. Then, we apply the corresponding defense on the textual modality by updating the prompts, which forces the re-matching on the perturbed embedding space. Finally, to enhance the attack transferability, we utilize the iterative training strategy on the visual attack and the textual defense, where the two processes optimize from each other. We evaluate our approach on several benchmark datasets and demonstrate that our mutual-modal attack strategy can effectively produce high-transferable attacks, which are stable regardless of the target networks. Our approach outperforms state-of-the-art attack methods and can be readily deployed as a plug-and-play solution.
Dataset Distillation: A Comprehensive Review
Jan 21, 2023



Recent success of deep learning is largely attributed to the sheer amount of data used for training deep neural networks.Despite the unprecedented success, the massive data, unfortunately, significantly increases the burden on storage and transmission and further gives rise to a cumbersome model training process. Besides, relying on the raw data for training \emph{per se} yields concerns about privacy and copyright. To alleviate these shortcomings, dataset distillation~(DD), also known as dataset condensation (DC), was introduced and has recently attracted much research attention in the community. Given an original dataset, DD aims to derive a much smaller dataset containing synthetic samples, based on which the trained models yield performance comparable with those trained on the original dataset. In this paper, we give a comprehensive review and summary of recent advances in DD and its application. We first introduce the task formally and propose an overall algorithmic framework followed by all existing DD methods. Next, we provide a systematic taxonomy of current methodologies in this area, and discuss their theoretical interconnections. We also present current challenges in DD through extensive experiments and envision possible directions for future works.
Federated Selective Aggregation for Knowledge Amalgamation
Jul 27, 2022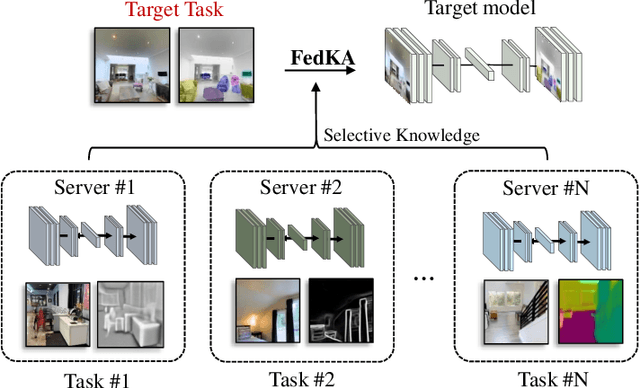

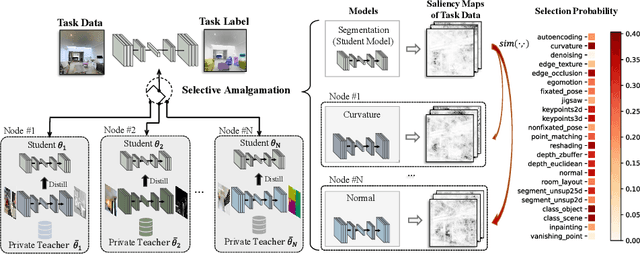
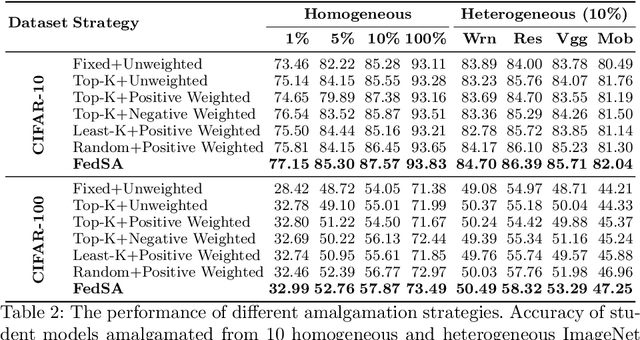
In this paper, we explore a new knowledge-amalgamation problem, termed Federated Selective Aggregation (FedSA). The goal of FedSA is to train a student model for a new task with the help of several decentralized teachers, whose pre-training tasks and data are different and agnostic. Our motivation for investigating such a problem setup stems from a recent dilemma of model sharing. Many researchers or institutes have spent enormous resources on training large and competent networks. Due to the privacy, security, or intellectual property issues, they are, however, not able to share their own pre-trained models, even if they wish to contribute to the community. The proposed FedSA offers a solution to this dilemma and makes it one step further since, again, the learned student may specialize in a new task different from all of the teachers. To this end, we proposed a dedicated strategy for handling FedSA. Specifically, our student-training process is driven by a novel saliency-based approach that adaptively selects teachers as the participants and integrates their representative capabilities into the student. To evaluate the effectiveness of FedSA, we conduct experiments on both single-task and multi-task settings. Experimental results demonstrate that FedSA effectively amalgamates knowledge from decentralized models and achieves competitive performance to centralized baselines.