 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgedParallel: Learnable Parallel Decoding for dLLMs
Sep 30, 2025
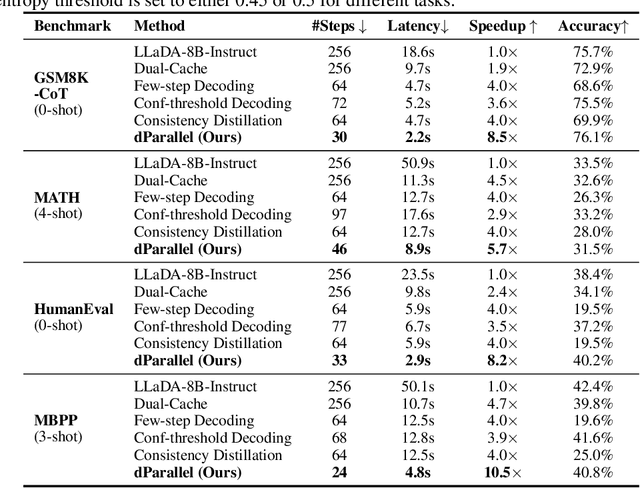
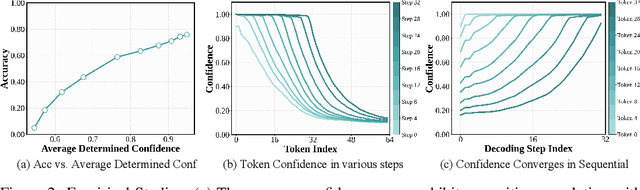
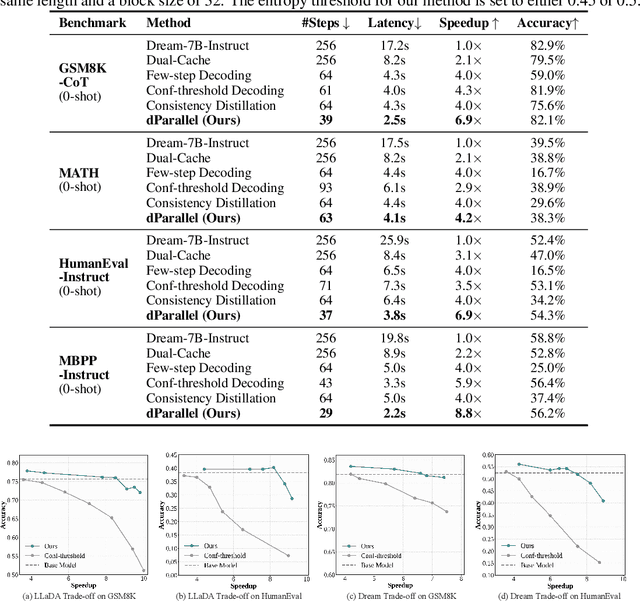
Diffusion large language models (dLLMs) have recently drawn considerable attention within the research community as a promising alternative to autoregressive generation, offering parallel token prediction and lower inference latency. Yet, their parallel decoding potential remains largely underexplored, as existing open-source models still require nearly token-length decoding steps to ensure performance. To address this, we introduce dParallel, a simple and effective method that unlocks the inherent parallelism of dLLMs for fast sampling. We identify that the key bottleneck to parallel decoding arises from the sequential certainty convergence for masked tokens. Building on this insight, we introduce the core of our approach: certainty-forcing distillation, a novel training strategy that distills the model to follow its original sampling trajectories while enforcing it to achieve high certainty on masked tokens more rapidly and in parallel. Extensive experiments across various benchmarks demonstrate that our method can dramatically reduce the number of decoding steps while maintaining performance. When applied to the LLaDA-8B-Instruct model, dParallel reduces decoding steps from 256 to 30 on GSM8K, achieving an 8.5x speedup without performance degradation. On the MBPP benchmark, it cuts decoding steps from 256 to 24, resulting in a 10.5x speedup while maintaining accuracy. Our code is available at https://github.com/czg1225/dParallel
Memory-Efficient Visual Autoregressive Modeling with Scale-Aware KV Cache Compression
May 26, 2025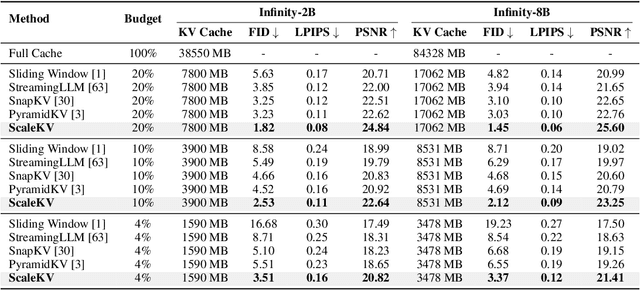
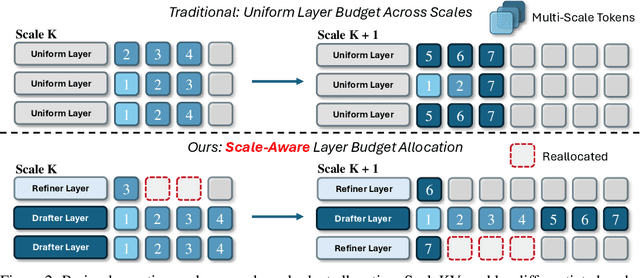
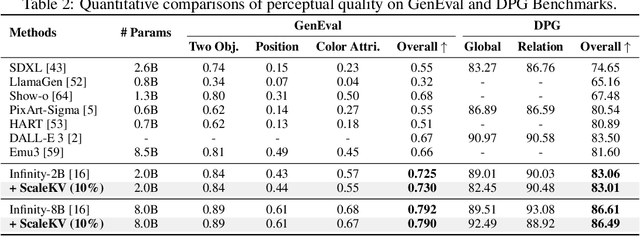
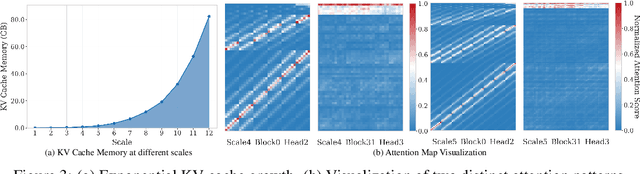
Visual Autoregressive (VAR) modeling has garnered significant attention for its innovative next-scale prediction approach, which yields substantial improvements in efficiency, scalability, and zero-shot generalization. Nevertheless, the coarse-to-fine methodology inherent in VAR results in exponential growth of the KV cache during inference, causing considerable memory consumption and computational redundancy. To address these bottlenecks, we introduce ScaleKV, a novel KV cache compression framework tailored for VAR architectures. ScaleKV leverages two critical observations: varying cache demands across transformer layers and distinct attention patterns at different scales. Based on these insights, ScaleKV categorizes transformer layers into two functional groups: drafters and refiners. Drafters exhibit dispersed attention across multiple scales, thereby requiring greater cache capacity. Conversely, refiners focus attention on the current token map to process local details, consequently necessitating substantially reduced cache capacity. ScaleKV optimizes the multi-scale inference pipeline by identifying scale-specific drafters and refiners, facilitating differentiated cache management tailored to each scale. Evaluation on the state-of-the-art text-to-image VAR model family, Infinity, demonstrates that our approach effectively reduces the required KV cache memory to 10% while preserving pixel-level fidelity.
VeriThinker: Learning to Verify Makes Reasoning Model Efficient
May 23, 2025Large Reasoning Models (LRMs) excel at complex tasks using Chain-of-Thought (CoT) reasoning. However, their tendency to overthinking leads to unnecessarily lengthy reasoning chains, dramatically increasing inference costs. To mitigate this issue, we introduce VeriThinker, a novel approach for CoT compression. Unlike conventional methods that fine-tune LRMs directly on the original reasoning task using synthetic concise CoT data, we innovatively fine-tune the model solely through an auxiliary verification task. By training LRMs to accurately verify the correctness of CoT solutions, the LRMs inherently become more discerning about the necessity of subsequent self-reflection steps, thereby effectively suppressing overthinking. Extensive experiments validate that VeriThinker substantially reduces reasoning chain lengths while maintaining or even slightly improving accuracy. When applied to DeepSeek-R1-Distill-Qwen-7B, our approach reduces reasoning tokens on MATH500 from 3790 to 2125 while improving accuracy by 0.8% (94.0% to 94.8%), and on AIME25, tokens decrease from 14321 to 10287 with a 2.1% accuracy gain (38.7% to 40.8%). Additionally, our experiments demonstrate that VeriThinker can also be zero-shot generalized to speculative reasoning. Code is available at https://github.com/czg1225/VeriThinker
Collaborative Decoding Makes Visual Auto-Regressive Modeling Efficient
Nov 26, 2024



In the rapidly advancing field of image generation, Visual Auto-Regressive (VAR) modeling has garnered considerable attention for its innovative next-scale prediction approach. This paradigm offers substantial improvements in efficiency, scalability, and zero-shot generalization. Yet, the inherently coarse-to-fine nature of VAR introduces a prolonged token sequence, leading to prohibitive memory consumption and computational redundancies. To address these bottlenecks, we propose Collaborative Decoding (CoDe), a novel efficient decoding strategy tailored for the VAR framework. CoDe capitalizes on two critical observations: the substantially reduced parameter demands at larger scales and the exclusive generation patterns across different scales. Based on these insights, we partition the multi-scale inference process into a seamless collaboration between a large model and a small model. The large model serves as the 'drafter', specializing in generating low-frequency content at smaller scales, while the smaller model serves as the 'refiner', solely focusing on predicting high-frequency details at larger scales. This collaboration yields remarkable efficiency with minimal impact on quality: CoDe achieves a 1.7x speedup, slashes memory usage by around 50%, and preserves image quality with only a negligible FID increase from 1.95 to 1.98. When drafting steps are further decreased, CoDe can achieve an impressive 2.9x acceleration ratio, reaching 41 images/s at 256x256 resolution on a single NVIDIA 4090 GPU, while preserving a commendable FID of 2.27. The code is available at https://github.com/czg1225/CoDe
Heavy Labels Out! Dataset Distillation with Label Space Lightening
Aug 15, 2024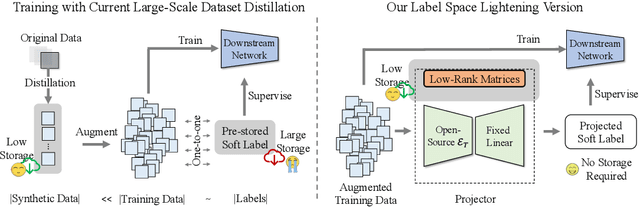


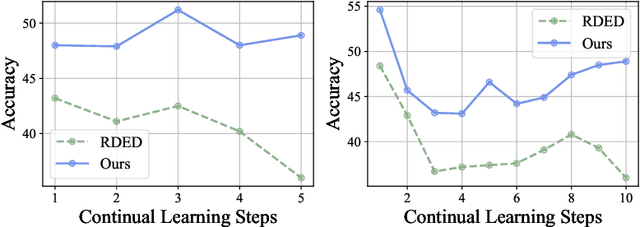
Dataset distillation or condensation aims to condense a large-scale training dataset into a much smaller synthetic one such that the training performance of distilled and original sets on neural networks are similar. Although the number of training samples can be reduced substantially, current state-of-the-art methods heavily rely on enormous soft labels to achieve satisfactory performance. As a result, the required storage can be comparable even to original datasets, especially for large-scale ones. To solve this problem, instead of storing these heavy labels, we propose a novel label-lightening framework termed HeLlO aiming at effective image-to-label projectors, with which synthetic labels can be directly generated online from synthetic images. Specifically, to construct such projectors, we leverage prior knowledge in open-source foundation models, e.g., CLIP, and introduce a LoRA-like fine-tuning strategy to mitigate the gap between pre-trained and target distributions, so that original models for soft-label generation can be distilled into a group of low-rank matrices. Moreover, an effective image optimization method is proposed to further mitigate the potential error between the original and distilled label generators. Extensive experiments demonstrate that with only about 0.003% of the original storage required for a complete set of soft labels, we achieve comparable performance to current state-of-the-art dataset distillation methods on large-scale datasets. Our code will be available.
AsyncDiff: Parallelizing Diffusion Models by Asynchronous Denoising
Jun 11, 2024



Diffusion models have garnered significant interest from the community for their great generative ability across various applications. However, their typical multi-step sequential-denoising nature gives rise to high cumulative latency, thereby precluding the possibilities of parallel computation. To address this, we introduce AsyncDiff, a universal and plug-and-play acceleration scheme that enables model parallelism across multiple devices. Our approach divides the cumbersome noise prediction model into multiple components, assigning each to a different device. To break the dependency chain between these components, it transforms the conventional sequential denoising into an asynchronous process by exploiting the high similarity between hidden states in consecutive diffusion steps. Consequently, each component is facilitated to compute in parallel on separate devices. The proposed strategy significantly reduces inference latency while minimally impacting the generative quality. Specifically, for the Stable Diffusion v2.1, AsyncDiff achieves a 2.7x speedup with negligible degradation and a 4.0x speedup with only a slight reduction of 0.38 in CLIP Score, on four NVIDIA A5000 GPUs. Our experiments also demonstrate that AsyncDiff can be readily applied to video diffusion models with encouraging performances. The code is available at https://github.com/czg1225/AsyncDiff.
0.1% Data Makes Segment Anything Slim
Dec 12, 2023



The formidable model size and demanding computational requirements of Segment Anything Model (SAM) have rendered it cumbersome for deployment on resource-constrained devices. Existing approaches for SAM compression typically involve training a new network from scratch, posing a challenging trade-off between compression costs and model performance. To address this issue, this paper introduces SlimSAM, a novel SAM compression method that achieves superior performance with remarkably low training costs. This is achieved by the efficient reuse of pre-trained SAMs through a unified pruning-distillation framework. To enhance knowledge inheritance from the original SAM, we employ an innovative alternate slimming strategy that partitions the compression process into a progressive procedure. Diverging from prior pruning techniques, we meticulously prune and distill decoupled model structures in an alternating fashion. Furthermore, a novel label-free pruning criterion is also proposed to align the pruning objective with the optimization target, thereby boosting the post-distillation after pruning. SlimSAM yields significant performance improvements while demanding over 10 times less training costs than any other existing methods. Even when compared to the original SAM-H, SlimSAM achieves approaching performance while reducing parameter counts to merely 0.9% (5.7M), MACs to 0.8% (21G), and requiring only 0.1% (10k) of the SAM training data. Code is available at url{http://github.com/czg1225/SlimSAM}.