 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHRBench: Benchmarking and Understanding Thinking-Mode Switch Strategies in Hybrid-Reasoning LLMs
May 27, 2026Hybrid-reasoning large language models (LLMs) expose explicit controls over reasoning effort, allowing users or systems to trade off answer quality against inference cost. However, existing methods for adaptive thinking-mode selection are typically evaluated under different models, datasets, and implementation assumptions, making it difficult to compare their practical behavior. We introduce HRBench, a unified evaluation framework for studying thinking-mode switching in hybrid-reasoning LLMs. HRBench organizes the design space along two axes: three switching strategy families, prompt-based selection, external routing, and speculative execution, and four training regimes, training-free, SFT, offline and online RL, yielding 12 controlled evaluation settings. We evaluate these settings across 6 LLMs, from Qwen3.5-2B to Kimi-K2.5-1.1T, and 5 reasoning benchmarks covering mathematics, science, and code, while reimplementing 12+ representative prior methods within the same pipeline. Our analysis characterizes how different switching strategies occupy distinct effectiveness-efficiency trade-off regions: prompt-based methods often provide favorable token-accuracy trade-offs, routing methods offer more stable cost reduction, and speculative methods tend to improve accuracy at higher token cost. We further find that training affects strategies differently, and that the preferred strategy varies with model scale and task domain. HRBench provides reference implementations and a unified evaluation platform to support more controlled research on efficient reasoning in hybrid-reasoning LLMs. Our data, code and repository are available at https://github.com/usail-hkust/HRBench.
Vision-Language-Action Safety: Threats, Challenges, Evaluations, and Mechanisms
Apr 26, 2026Vision-Language-Action (VLA) models are emerging as a unified substrate for embodied intelligence. This shift raises a new class of safety challenges, stemming from the embodied nature of VLA systems, including irreversible physical consequences, a multimodal attack surface across vision, language, and state, real-time latency constraints on defense, error propagation over long-horizon trajectories, and vulnerabilities in the data supply chain. Yet the literature remains fragmented across robotic learning, adversarial machine learning, AI alignment, and autonomous systems safety. This survey provides a unified and up-to-date overview of safety in Vision-Language-Action models. We organize the field along two parallel timing axes, attack timing (training-time vs. inference-time and defense timing (training-time vs. inference-time, linking each class of threat to the stage at which it can be mitigated. We first define the scope of VLA safety, distinguishing it from text-only LLM safety and classical robotic safety, and review the foundations of VLA models, including architectures, training paradigms, and inference mechanisms. We then examine the literature through four lenses: Attacks, Defenses, Evaluation, and Deployment. We survey training-time threats such as data poisoning and backdoors, as well as inference-time attacks including adversarial patches, cross-modal perturbations, semantic jailbreaks, and freezing attacks. We review training-time and runtime defenses, analyze existing benchmarks and metrics, and discuss safety challenges across six deployment domains. Finally, we highlight key open problems, including certified robustness for embodied trajectories, physically realizable defenses, safety-aware training, unified runtime safety architectures, and standardized evaluation.
Anatomy of a Lie: A Multi-Stage Diagnostic Framework for Tracing Hallucinations in Vision-Language Models
Mar 16, 2026Vision-Language Models (VLMs) frequently "hallucinate" - generate plausible yet factually incorrect statements - posing a critical barrier to their trustworthy deployment. In this work, we propose a new paradigm for diagnosing hallucinations, recasting them from static output errors into dynamic pathologies of a model's computational cognition. Our framework is grounded in a normative principle of computational rationality, allowing us to model a VLM's generation as a dynamic cognitive trajectory. We design a suite of information-theoretic probes that project this trajectory onto an interpretable, low-dimensional Cognitive State Space. Our central discovery is a governing principle we term the geometric-information duality: a cognitive trajectory's geometric abnormality within this space is fundamentally equivalent to its high information-theoretic surprisal. Hallucination detection is counts as a geometric anomaly detection problem. Evaluated across diverse settings - from rigorous binary QA (POPE) and comprehensive reasoning (MME) to unconstrained open-ended captioning (MS-COCO) - our framework achieves state-of-the-art performance. Crucially, it operates with high efficiency under weak supervision and remains highly robust even when calibration data is heavily contaminated. This approach enables a causal attribution of failures, mapping observable errors to distinct pathological states: perceptual instability (measured by Perceptual Entropy), logical-causal failure (measured by Inferential Conflict), and decisional ambiguity (measured by Decision Entropy). Ultimately, this opens a path toward building AI systems whose reasoning is transparent, auditable, and diagnosable by design.
FastPhysGS: Accelerating Physics-based Dynamic 3DGS Simulation via Interior Completion and Adaptive Optimization
Feb 02, 2026Extending 3D Gaussian Splatting (3DGS) to 4D physical simulation remains challenging. Based on the Material Point Method (MPM), existing methods either rely on manual parameter tuning or distill dynamics from video diffusion models, limiting the generalization and optimization efficiency. Recent attempts using LLMs/VLMs suffer from a text/image-to-3D perceptual gap, yielding unstable physics behavior. In addition, they often ignore the surface structure of 3DGS, leading to implausible motion. We propose FastPhysGS, a fast and robust framework for physics-based dynamic 3DGS simulation:(1) Instance-aware Particle Filling (IPF) with Monte Carlo Importance Sampling (MCIS) to efficiently populate interior particles while preserving geometric fidelity; (2) Bidirectional Graph Decoupling Optimization (BGDO), an adaptive strategy that rapidly optimizes material parameters predicted from a VLM. Experiments show FastPhysGS achieves high-fidelity physical simulation in 1 minute using only 7 GB runtime memory, outperforming prior works with broad potential applications.
StdGEN++: A Comprehensive System for Semantic-Decomposed 3D Character Generation
Jan 12, 2026We present StdGEN++, a novel and comprehensive system for generating high-fidelity, semantically decomposed 3D characters from diverse inputs. Existing 3D generative methods often produce monolithic meshes that lack the structural flexibility required by industrial pipelines in gaming and animation. Addressing this gap, StdGEN++ is built upon a Dual-branch Semantic-aware Large Reconstruction Model (Dual-Branch S-LRM), which jointly reconstructs geometry, color, and per-component semantics in a feed-forward manner. To achieve production-level fidelity, we introduce a novel semantic surface extraction formalism compatible with hybrid implicit fields. This mechanism is accelerated by a coarse-to-fine proposal scheme, which significantly reduces memory footprint and enables high-resolution mesh generation. Furthermore, we propose a video-diffusion-based texture decomposition module that disentangles appearance into editable layers (e.g., separated iris and skin), resolving semantic confusion in facial regions. Experiments demonstrate that StdGEN++ achieves state-of-the-art performance, significantly outperforming existing methods in geometric accuracy and semantic disentanglement. Crucially, the resulting structural independence unlocks advanced downstream capabilities, including non-destructive editing, physics-compliant animation, and gaze tracking, making it a robust solution for automated character asset production.
OpenView: Empowering MLLMs with Out-of-view VQA
Dec 21, 2025Recent multimodal large language models (MLLMs) show great potential in natural image understanding. Yet, they perform well, mainly on reasoning in-view contents within the image frame. This paper presents the first study on out-of-view (OOV) understanding, i.e., the ability to reason objects, activities, and scenes beyond the visible frame of a perspective view. Our technical contributions are threefold. First, we design OpenView, a four-stage pipeline to massively generate multi-choice VQA by leveraging panoramic imagery to enable context-rich and spatial-grounded VQA synthesis with free-view framing. Second, we curate OpenView-Dataset, a high-quality synthetic dataset from diverse real-world panoramas to empower MLLMs upon supervised fine-tuning. Third, we build OpenView-Bench, a benchmark that jointly measures choice and rationale accuracy for interpretable and diagnosable evaluation. Experimental results show that despite having a large gap from human performance in OOV VQA answer selection, upon empowered by OpenView, multiple MLLMs can consistently boost their performance, uplifted from 48.6% to 64.1% on average. Code, benchmark, and data will be available at https://github.com/q1xiangchen/OpenView.
Semantic Surgery: Zero-Shot Concept Erasure in Diffusion Models
Oct 26, 2025Concept erasure in text-to-image diffusion models is crucial for mitigating harmful content, yet existing methods often compromise generative quality. We introduce Semantic Surgery, a novel training-free, zero-shot framework for concept erasure that operates directly on text embeddings before the diffusion process. It dynamically estimates the presence of target concepts in a prompt and performs a calibrated vector subtraction to neutralize their influence at the source, enhancing both erasure completeness and locality. The framework includes a Co-Occurrence Encoding module for robust multi-concept erasure and a visual feedback loop to address latent concept persistence. As a training-free method, Semantic Surgery adapts dynamically to each prompt, ensuring precise interventions. Extensive experiments on object, explicit content, artistic style, and multi-celebrity erasure tasks show our method significantly outperforms state-of-the-art approaches. We achieve superior completeness and robustness while preserving locality and image quality (e.g., 93.58 H-score in object erasure, reducing explicit content to just 1 instance, and 8.09 H_a in style erasure with no quality degradation). This robustness also allows our framework to function as a built-in threat detection system, offering a practical solution for safer text-to-image generation.
PrimitiveAnything: Human-Crafted 3D Primitive Assembly Generation with Auto-Regressive Transformer
May 07, 2025
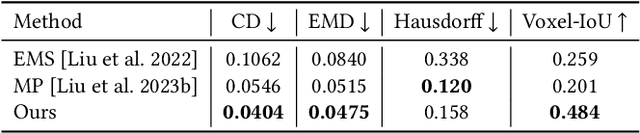
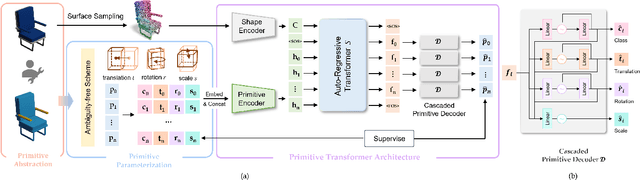
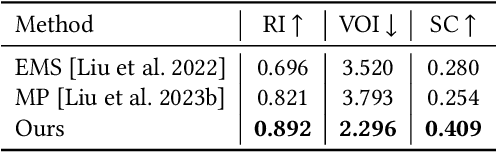
Shape primitive abstraction, which decomposes complex 3D shapes into simple geometric elements, plays a crucial role in human visual cognition and has broad applications in computer vision and graphics. While recent advances in 3D content generation have shown remarkable progress, existing primitive abstraction methods either rely on geometric optimization with limited semantic understanding or learn from small-scale, category-specific datasets, struggling to generalize across diverse shape categories. We present PrimitiveAnything, a novel framework that reformulates shape primitive abstraction as a primitive assembly generation task. PrimitiveAnything includes a shape-conditioned primitive transformer for auto-regressive generation and an ambiguity-free parameterization scheme to represent multiple types of primitives in a unified manner. The proposed framework directly learns the process of primitive assembly from large-scale human-crafted abstractions, enabling it to capture how humans decompose complex shapes into primitive elements. Through extensive experiments, we demonstrate that PrimitiveAnything can generate high-quality primitive assemblies that better align with human perception while maintaining geometric fidelity across diverse shape categories. It benefits various 3D applications and shows potential for enabling primitive-based user-generated content (UGC) in games. Project page: https://primitiveanything.github.io
Reinforced Model Merging
Mar 27, 2025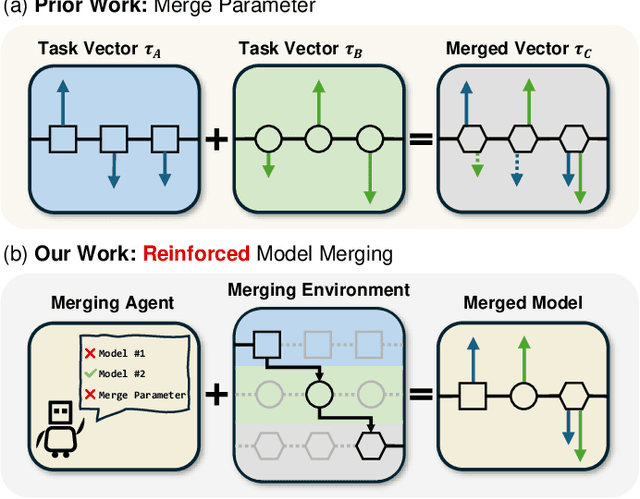
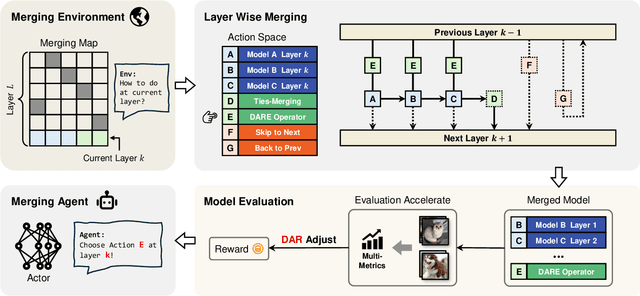
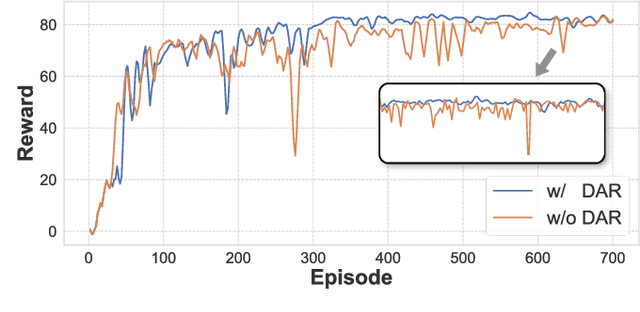
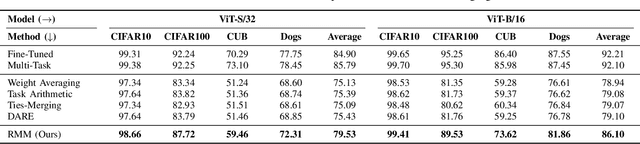
The success of large language models has garnered widespread attention for model merging techniques, especially training-free methods which combine model capabilities within the parameter space. However, two challenges remain: (1) uniform treatment of all parameters leads to performance degradation; (2) search-based algorithms are often inefficient. In this paper, we present an innovative framework termed Reinforced Model Merging (RMM), which encompasses an environment and agent tailored for merging tasks. These components interact to execute layer-wise merging actions, aiming to search the optimal merging architecture. Notably, RMM operates without any gradient computations on the original models, rendering it feasible for edge devices. Furthermore, by utilizing data subsets during the evaluation process, we addressed the bottleneck in the reward feedback phase, thereby accelerating RMM by up to 100 times. Extensive experiments demonstrate that RMM achieves state-of-the-art performance across various vision and NLP datasets and effectively overcomes the limitations of the existing baseline methods. Our code is available at https://github.com/WuDiHJQ/Reinforced-Model-Merging.
Adversarial Training: A Survey
Oct 19, 2024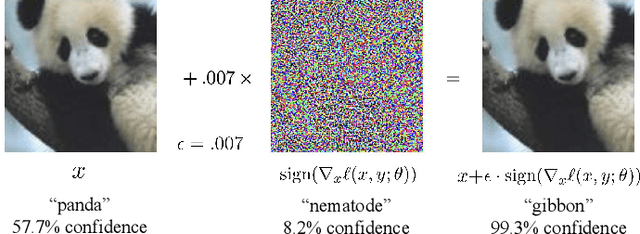
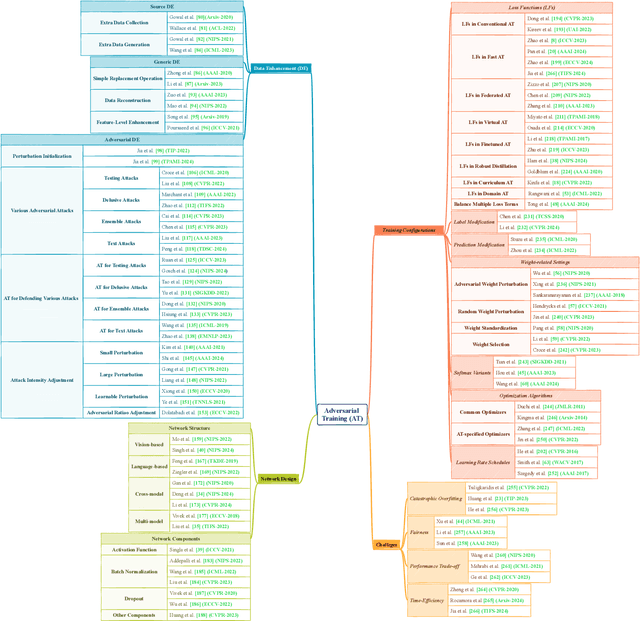
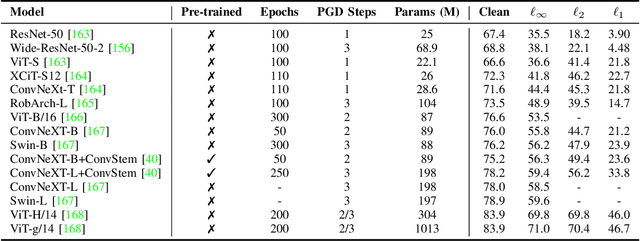
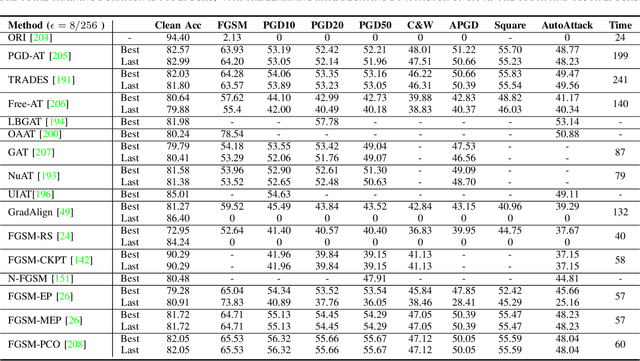
Adversarial training (AT) refers to integrating adversarial examples -- inputs altered with imperceptible perturbations that can significantly impact model predictions -- into the training process. Recent studies have demonstrated the effectiveness of AT in improving the robustness of deep neural networks against diverse adversarial attacks. However, a comprehensive overview of these developments is still missing. This survey addresses this gap by reviewing a broad range of recent and representative studies. Specifically, we first describe the implementation procedures and practical applications of AT, followed by a comprehensive review of AT techniques from three perspectives: data enhancement, network design, and training configurations. Lastly, we discuss common challenges in AT and propose several promising directions for future research.