 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrimitiveAnything: Human-Crafted 3D Primitive Assembly Generation with Auto-Regressive Transformer
May 07, 2025
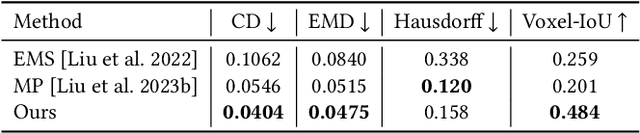
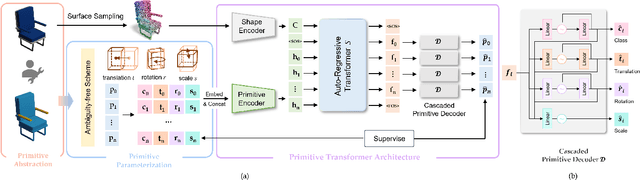
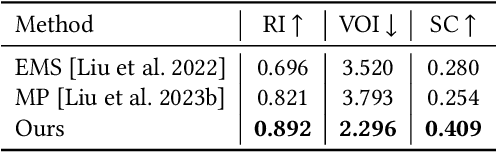
Shape primitive abstraction, which decomposes complex 3D shapes into simple geometric elements, plays a crucial role in human visual cognition and has broad applications in computer vision and graphics. While recent advances in 3D content generation have shown remarkable progress, existing primitive abstraction methods either rely on geometric optimization with limited semantic understanding or learn from small-scale, category-specific datasets, struggling to generalize across diverse shape categories. We present PrimitiveAnything, a novel framework that reformulates shape primitive abstraction as a primitive assembly generation task. PrimitiveAnything includes a shape-conditioned primitive transformer for auto-regressive generation and an ambiguity-free parameterization scheme to represent multiple types of primitives in a unified manner. The proposed framework directly learns the process of primitive assembly from large-scale human-crafted abstractions, enabling it to capture how humans decompose complex shapes into primitive elements. Through extensive experiments, we demonstrate that PrimitiveAnything can generate high-quality primitive assemblies that better align with human perception while maintaining geometric fidelity across diverse shape categories. It benefits various 3D applications and shows potential for enabling primitive-based user-generated content (UGC) in games. Project page: https://primitiveanything.github.io
RLTF: Reinforcement Learning from Unit Test Feedback
Jul 10, 2023



The goal of program synthesis, or code generation, is to generate executable code based on given descriptions. Recently, there has been an increasing number of studies employing reinforcement learning (RL) to improve the performance of large language models (LLMs) for code. However, these RL methods have only used offline frameworks, limiting their exploration of new sample spaces. Additionally, current approaches that utilize unit test signals are rather simple, not accounting for specific error locations within the code. To address these issues, we proposed RLTF, i.e., Reinforcement Learning from Unit Test Feedback, a novel online RL framework with unit test feedback of multi-granularity for refining code LLMs. Our approach generates data in real-time during training and simultaneously utilizes fine-grained feedback signals to guide the model towards producing higher-quality code. Extensive experiments show that RLTF achieves state-of-the-art performance on the APPS and the MBPP benchmarks. Our code can be found at: https://github.com/Zyq-scut/RLTF.
MMOCR: A Comprehensive Toolbox for Text Detection, Recognition and Understanding
Aug 14, 2021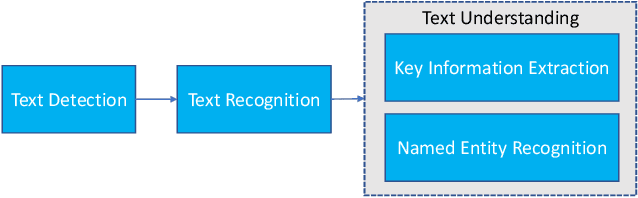



We present MMOCR-an open-source toolbox which provides a comprehensive pipeline for text detection and recognition, as well as their downstream tasks such as named entity recognition and key information extraction. MMOCR implements 14 state-of-the-art algorithms, which is significantly more than all the existing open-source OCR projects we are aware of to date. To facilitate future research and industrial applications of text recognition-related problems, we also provide a large number of trained models and detailed benchmarks to give insights into the performance of text detection, recognition and understanding. MMOCR is publicly released at https://github.com/open-mmlab/mmocr.
Fourier Contour Embedding for Arbitrary-Shaped Text Detection
Apr 22, 2021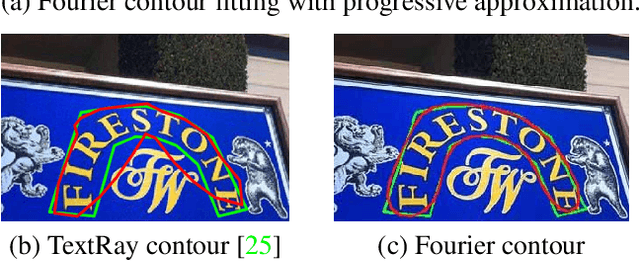
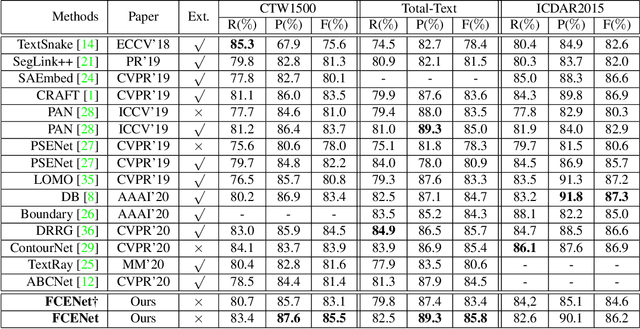
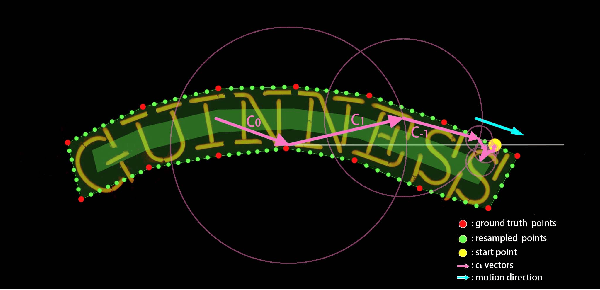
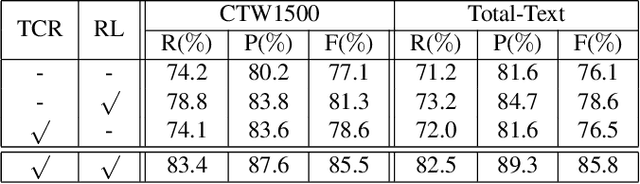
One of the main challenges for arbitrary-shaped text detection is to design a good text instance representation that allows networks to learn diverse text geometry variances. Most of existing methods model text instances in image spatial domain via masks or contour point sequences in the Cartesian or the polar coordinate system. However, the mask representation might lead to expensive post-processing, while the point sequence one may have limited capability to model texts with highly-curved shapes. To tackle these problems, we model text instances in the Fourier domain and propose one novel Fourier Contour Embedding (FCE) method to represent arbitrary shaped text contours as compact signatures. We further construct FCENet with a backbone, feature pyramid networks (FPN) and a simple post-processing with the Inverse Fourier Transformation (IFT) and Non-Maximum Suppression (NMS). Different from previous methods, FCENet first predicts compact Fourier signatures of text instances, and then reconstructs text contours via IFT and NMS during test. Extensive experiments demonstrate that FCE is accurate and robust to fit contours of scene texts even with highly-curved shapes, and also validate the effectiveness and the good generalization of FCENet for arbitrary-shaped text detection. Furthermore, experimental results show that our FCENet is superior to the state-of-the-art (SOTA) methods on CTW1500 and Total-Text, especially on challenging highly-curved text subset.