 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical Recipes for Efficient and Compact Vision-Language Models
Mar 17, 2026Deploying vision-language models (VLMs) in resource-constrained settings demands low latency and high throughput, yet existing compact VLMs often fall short of the inference speedups their smaller parameter counts suggest. To explain this discrepancy, we conduct an empirical end-to-end efficiency analysis and systematically profile inference to identify the dominant bottlenecks. Based on these findings, we develop optimization recipes tailored to compact VLMs that substantially reduce latency while preserving accuracy. These techniques cut time to first token (TTFT) by 53% on InternVL3-2B and by 93% on SmolVLM-256M. Our recipes are broadly applicable across both VLM architectures and common serving frameworks, providing practical guidance for building efficient VLM systems. Beyond efficiency, we study how to extend compact VLMs with structured perception outputs and introduce the resulting model family, ArgusVLM. Across diverse benchmarks, ArgusVLM achieves strong performance while maintaining a compact and efficient design.
StelLA: Subspace Learning in Low-rank Adaptation using Stiefel Manifold
Oct 02, 2025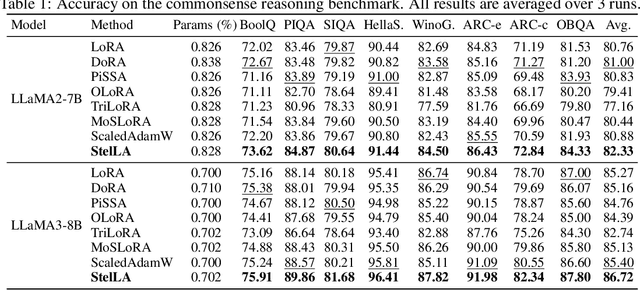
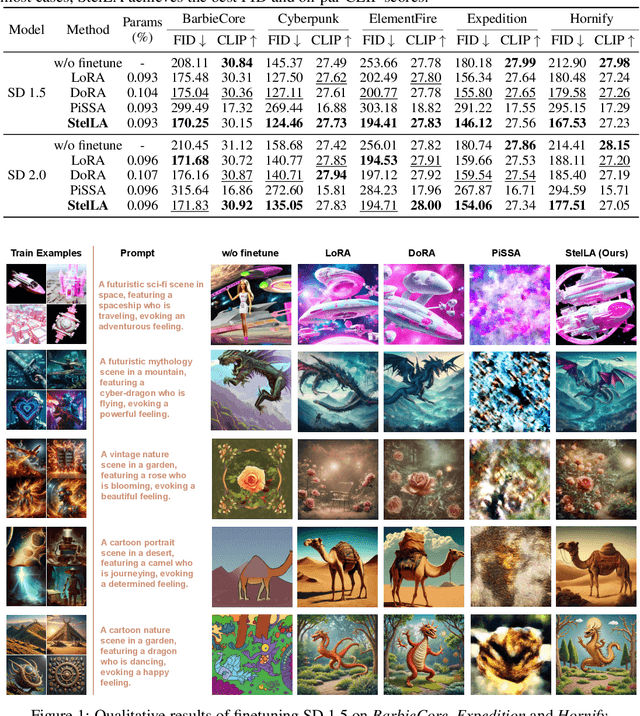
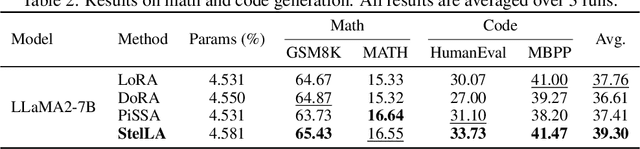
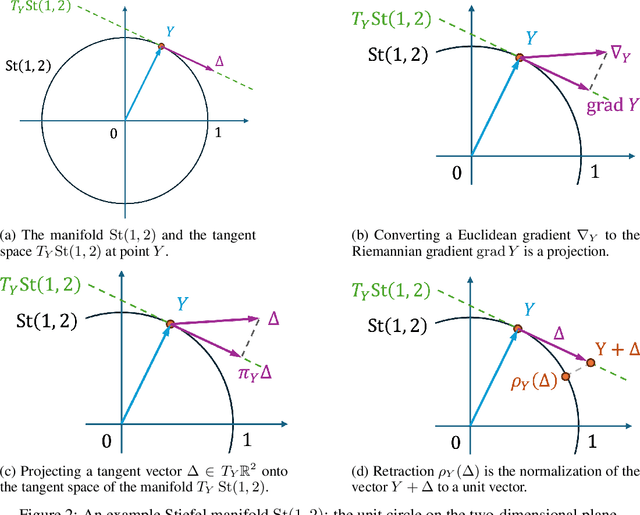
Low-rank adaptation (LoRA) has been widely adopted as a parameter-efficient technique for fine-tuning large-scale pre-trained models. However, it still lags behind full fine-tuning in performance, partly due to its insufficient exploitation of the geometric structure underlying low-rank manifolds. In this paper, we propose a geometry-aware extension of LoRA that uses a three-factor decomposition $U\!SV^\top$. Analogous to the structure of singular value decomposition (SVD), it separates the adapter's input and output subspaces, $V$ and $U$, from the scaling factor $S$. Our method constrains $U$ and $V$ to lie on the Stiefel manifold, ensuring their orthonormality throughout the training. To optimize on the Stiefel manifold, we employ a flexible and modular geometric optimization design that converts any Euclidean optimizer to a Riemannian one. It enables efficient subspace learning while remaining compatible with existing fine-tuning pipelines. Empirical results across a wide range of downstream tasks, including commonsense reasoning, math and code generation, image classification, and image generation, demonstrate the superior performance of our approach against the recent state-of-the-art variants of LoRA. Code is available at https://github.com/SonyResearch/stella.
Investigating the Design Space of Visual Grounding in Multimodal Large Language Model
Aug 11, 2025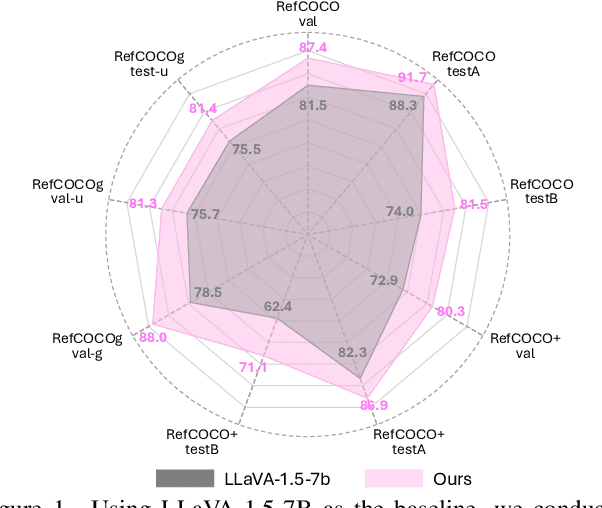
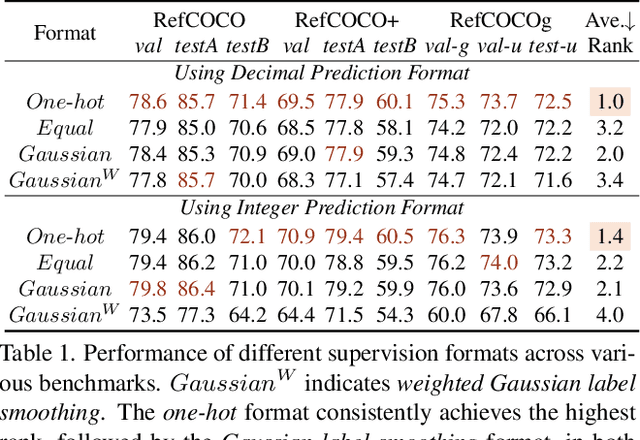
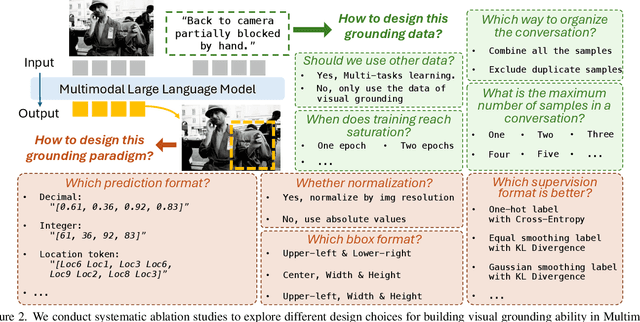
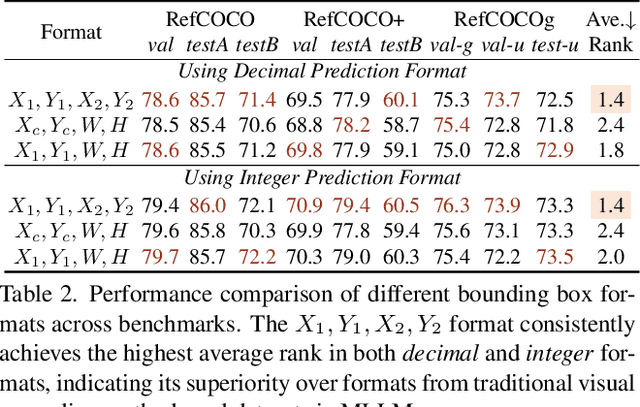
Fine-grained multimodal capability in Multimodal Large Language Models (MLLMs) has emerged as a critical research direction, particularly for tackling the visual grounding (VG) problem. Despite the strong performance achieved by existing approaches, they often employ disparate design choices when fine-tuning MLLMs for VG, lacking systematic verification to support these designs. To bridge this gap, this paper presents a comprehensive study of various design choices that impact the VG performance of MLLMs. We conduct our analysis using LLaVA-1.5, which has been widely adopted in prior empirical studies of MLLMs. While more recent models exist, we follow this convention to ensure our findings remain broadly applicable and extendable to other architectures. We cover two key aspects: (1) exploring different visual grounding paradigms in MLLMs, identifying the most effective design, and providing our insights; and (2) conducting ablation studies on the design of grounding data to optimize MLLMs' fine-tuning for the VG task. Finally, our findings contribute to a stronger MLLM for VG, achieving improvements of +5.6% / +6.9% / +7.0% on RefCOCO/+/g over the LLaVA-1.5.
THRONE: An Object-based Hallucination Benchmark for the Free-form Generations of Large Vision-Language Models
May 08, 2024Mitigating hallucinations in large vision-language models (LVLMs) remains an open problem. Recent benchmarks do not address hallucinations in open-ended free-form responses, which we term "Type I hallucinations". Instead, they focus on hallucinations responding to very specific question formats -- typically a multiple-choice response regarding a particular object or attribute -- which we term "Type II hallucinations". Additionally, such benchmarks often require external API calls to models which are subject to change. In practice, we observe that a reduction in Type II hallucinations does not lead to a reduction in Type I hallucinations but rather that the two forms of hallucinations are often anti-correlated. To address this, we propose THRONE, a novel object-based automatic framework for quantitatively evaluating Type I hallucinations in LVLM free-form outputs. We use public language models (LMs) to identify hallucinations in LVLM responses and compute informative metrics. By evaluating a large selection of recent LVLMs using public datasets, we show that an improvement in existing metrics do not lead to a reduction in Type I hallucinations, and that established benchmarks for measuring Type I hallucinations are incomplete. Finally, we provide a simple and effective data augmentation method to reduce Type I and Type II hallucinations as a strong baseline.
Get the Best of Both Worlds: Improving Accuracy and Transferability by Grassmann Class Representation
Aug 03, 2023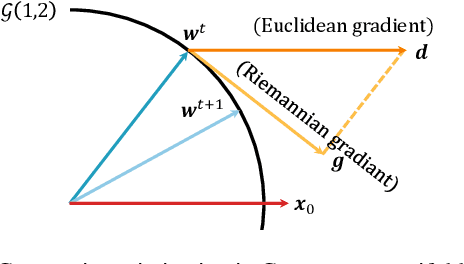


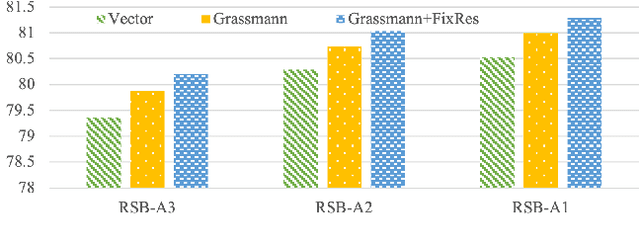
We generalize the class vectors found in neural networks to linear subspaces (i.e.~points in the Grassmann manifold) and show that the Grassmann Class Representation (GCR) enables the simultaneous improvement in accuracy and feature transferability. In GCR, each class is a subspace and the logit is defined as the norm of the projection of a feature onto the class subspace. We integrate Riemannian SGD into deep learning frameworks such that class subspaces in a Grassmannian are jointly optimized with the rest model parameters. Compared to the vector form, the representative capability of subspaces is more powerful. We show that on ImageNet-1K, the top-1 error of ResNet50-D, ResNeXt50, Swin-T and Deit3-S are reduced by 5.6%, 4.5%, 3.0% and 3.5%, respectively. Subspaces also provide freedom for features to vary and we observed that the intra-class feature variability grows when the subspace dimension increases. Consequently, we found the quality of GCR features is better for downstream tasks. For ResNet50-D, the average linear transfer accuracy across 6 datasets improves from 77.98% to 79.70% compared to the strong baseline of vanilla softmax. For Swin-T, it improves from 81.5% to 83.4% and for Deit3, it improves from 73.8% to 81.4%. With these encouraging results, we believe that more applications could benefit from the Grassmann class representation. Code is released at https://github.com/innerlee/GCR.
Collaborative Anomaly Detection
Sep 20, 2022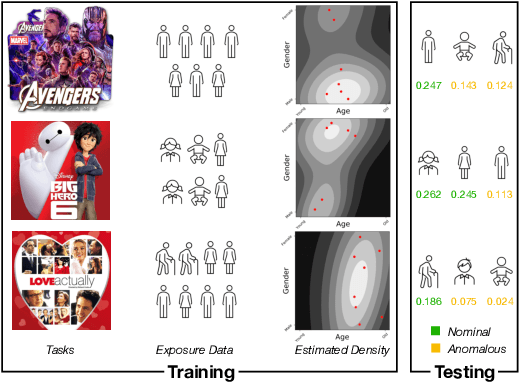
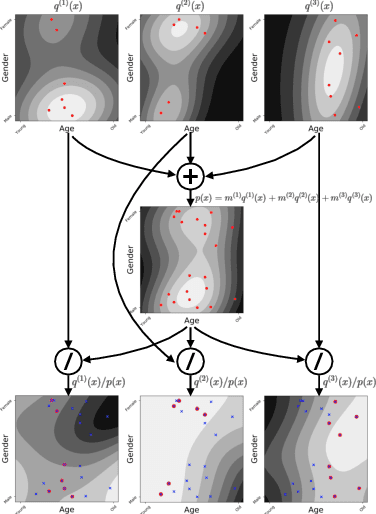

In recommendation systems, items are likely to be exposed to various users and we would like to learn about the familiarity of a new user with an existing item. This can be formulated as an anomaly detection (AD) problem distinguishing between "common users" (nominal) and "fresh users" (anomalous). Considering the sheer volume of items and the sparsity of user-item paired data, independently applying conventional single-task detection methods on each item quickly becomes difficult, while correlations between items are ignored. To address this multi-task anomaly detection problem, we propose collaborative anomaly detection (CAD) to jointly learn all tasks with an embedding encoding correlations among tasks. We explore CAD with conditional density estimation and conditional likelihood ratio estimation. We found that: $i$) estimating a likelihood ratio enjoys more efficient learning and yields better results than density estimation. $ii$) It is beneficial to select a small number of tasks in advance to learn a task embedding model, and then use it to warm-start all task embeddings. Consequently, these embeddings can capture correlations between tasks and generalize to new correlated tasks.
Class-Incremental Learning with Strong Pre-trained Models
Apr 07, 2022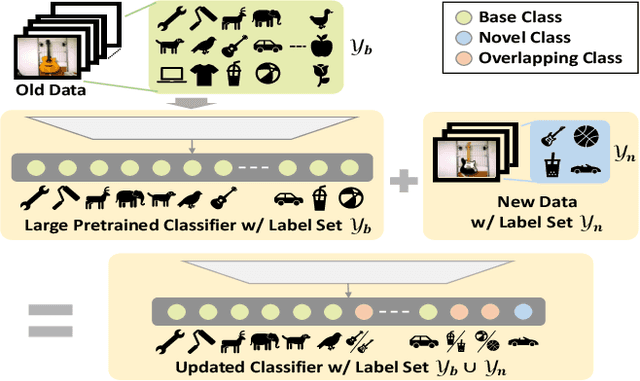
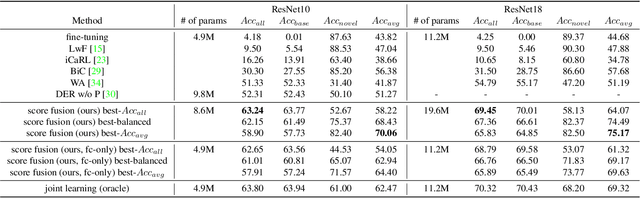
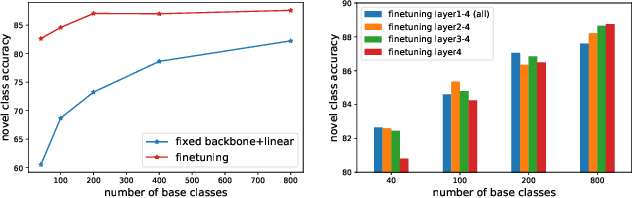
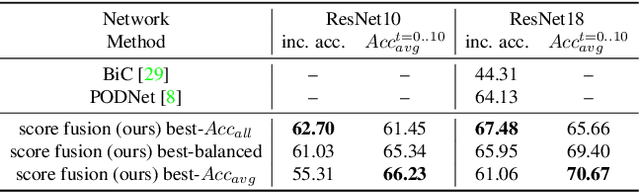
Class-incremental learning (CIL) has been widely studied under the setting of starting from a small number of classes (base classes). Instead, we explore an understudied real-world setting of CIL that starts with a strong model pre-trained on a large number of base classes. We hypothesize that a strong base model can provide a good representation for novel classes and incremental learning can be done with small adaptations. We propose a 2-stage training scheme, i) feature augmentation -- cloning part of the backbone and fine-tuning it on the novel data, and ii) fusion -- combining the base and novel classifiers into a unified classifier. Experiments show that the proposed method significantly outperforms state-of-the-art CIL methods on the large-scale ImageNet dataset (e.g. +10% overall accuracy than the best). We also propose and analyze understudied practical CIL scenarios, such as base-novel overlap with distribution shift. Our proposed method is robust and generalizes to all analyzed CIL settings.
ViM: Out-Of-Distribution with Virtual-logit Matching
Mar 21, 2022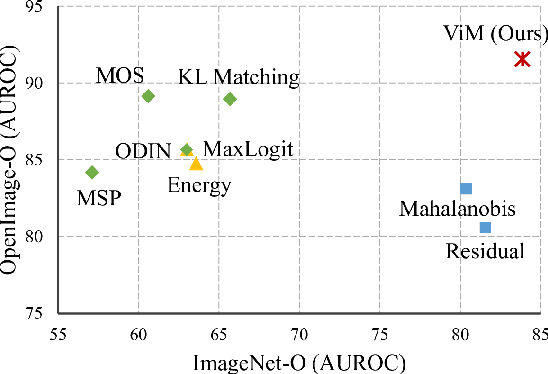

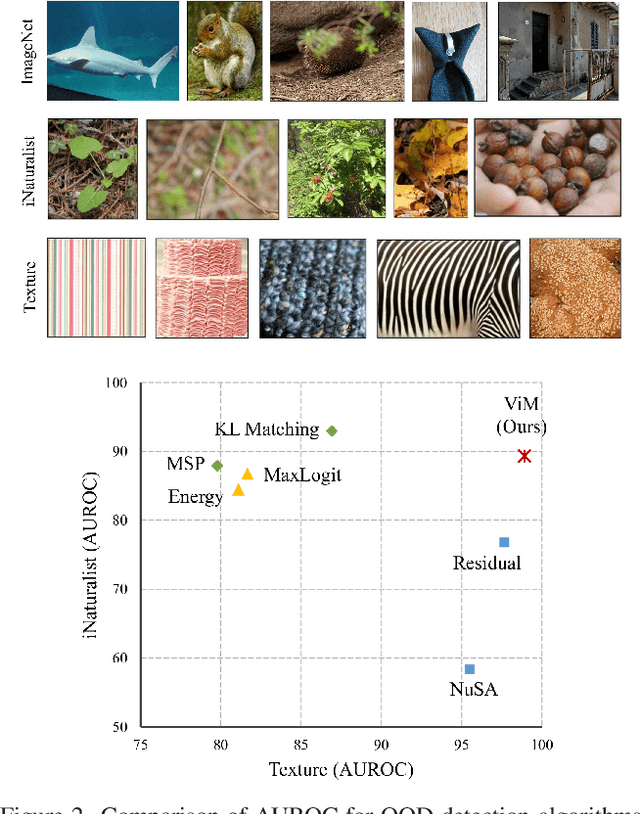
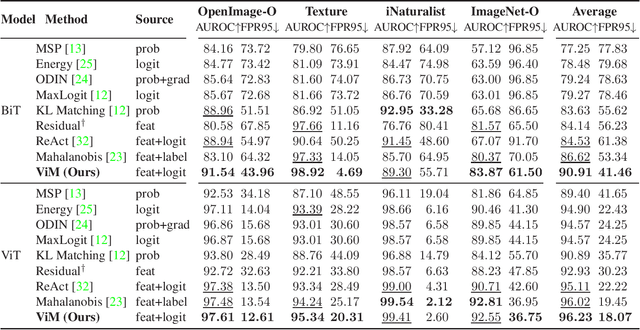
Most of the existing Out-Of-Distribution (OOD) detection algorithms depend on single input source: the feature, the logit, or the softmax probability. However, the immense diversity of the OOD examples makes such methods fragile. There are OOD samples that are easy to identify in the feature space while hard to distinguish in the logit space and vice versa. Motivated by this observation, we propose a novel OOD scoring method named Virtual-logit Matching (ViM), which combines the class-agnostic score from feature space and the In-Distribution (ID) class-dependent logits. Specifically, an additional logit representing the virtual OOD class is generated from the residual of the feature against the principal space, and then matched with the original logits by a constant scaling. The probability of this virtual logit after softmax is the indicator of OOD-ness. To facilitate the evaluation of large-scale OOD detection in academia, we create a new OOD dataset for ImageNet-1K, which is human-annotated and is 8.8x the size of existing datasets. We conducted extensive experiments, including CNNs and vision transformers, to demonstrate the effectiveness of the proposed ViM score. In particular, using the BiT-S model, our method gets an average AUROC 90.91% on four difficult OOD benchmarks, which is 4% ahead of the best baseline. Code and dataset are available at https://github.com/haoqiwang/vim.
MMOCR: A Comprehensive Toolbox for Text Detection, Recognition and Understanding
Aug 14, 2021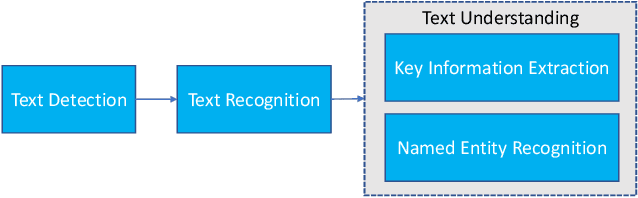



We present MMOCR-an open-source toolbox which provides a comprehensive pipeline for text detection and recognition, as well as their downstream tasks such as named entity recognition and key information extraction. MMOCR implements 14 state-of-the-art algorithms, which is significantly more than all the existing open-source OCR projects we are aware of to date. To facilitate future research and industrial applications of text recognition-related problems, we also provide a large number of trained models and detailed benchmarks to give insights into the performance of text detection, recognition and understanding. MMOCR is publicly released at https://github.com/open-mmlab/mmocr.
Representation Consolidation for Training Expert Students
Jul 16, 2021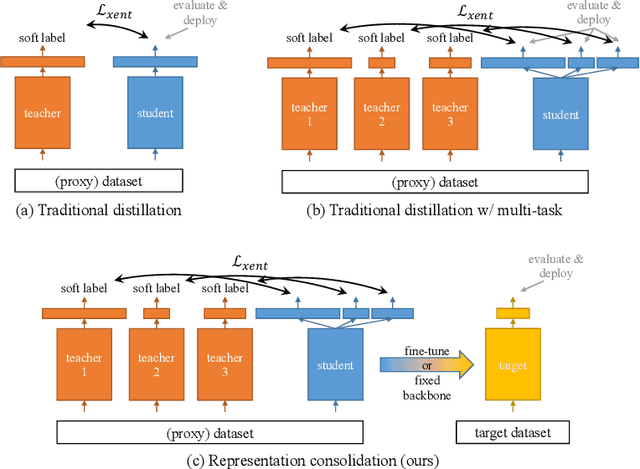

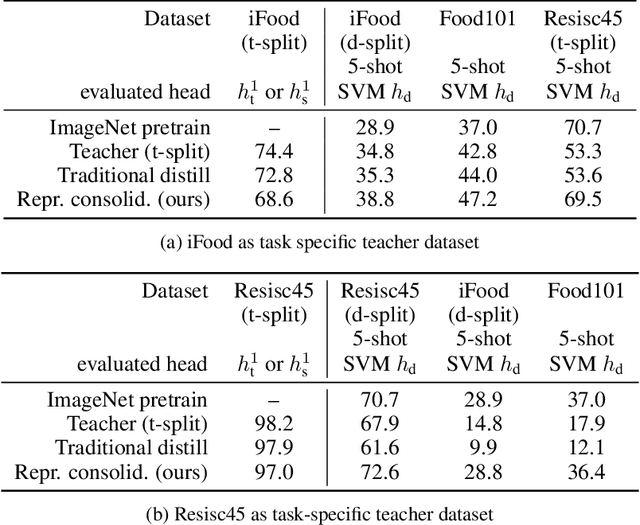

Traditionally, distillation has been used to train a student model to emulate the input/output functionality of a teacher. A more useful goal than emulation, yet under-explored, is for the student to learn feature representations that transfer well to future tasks. However, we observe that standard distillation of task-specific teachers actually *reduces* the transferability of student representations to downstream tasks. We show that a multi-head, multi-task distillation method using an unlabeled proxy dataset and a generalist teacher is sufficient to consolidate representations from task-specific teacher(s) and improve downstream performance, outperforming the teacher(s) and the strong baseline of ImageNet pretrained features. Our method can also combine the representational knowledge of multiple teachers trained on one or multiple domains into a single model, whose representation is improved on all teachers' domain(s).