 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVCformer: Variable Correlation Transformer with Inherent Lagged Correlation for Multivariate Time Series Forecasting
May 19, 2024Multivariate time series (MTS) forecasting has been extensively applied across diverse domains, such as weather prediction and energy consumption. However, current studies still rely on the vanilla point-wise self-attention mechanism to capture cross-variable dependencies, which is inadequate in extracting the intricate cross-correlation implied between variables. To fill this gap, we propose Variable Correlation Transformer (VCformer), which utilizes Variable Correlation Attention (VCA) module to mine the correlations among variables. Specifically, based on the stochastic process theory, VCA calculates and integrates the cross-correlation scores corresponding to different lags between queries and keys, thereby enhancing its ability to uncover multivariate relationships. Additionally, inspired by Koopman dynamics theory, we also develop Koopman Temporal Detector (KTD) to better address the non-stationarity in time series. The two key components enable VCformer to extract both multivariate correlations and temporal dependencies. Our extensive experiments on eight real-world datasets demonstrate the effectiveness of VCformer, achieving top-tier performance compared to other state-of-the-art baseline models. Code is available at this repository: https://github.com/CSyyn/VCformer.
Large Language Model-Aided Evolutionary Search for Constrained Multiobjective Optimization
May 09, 2024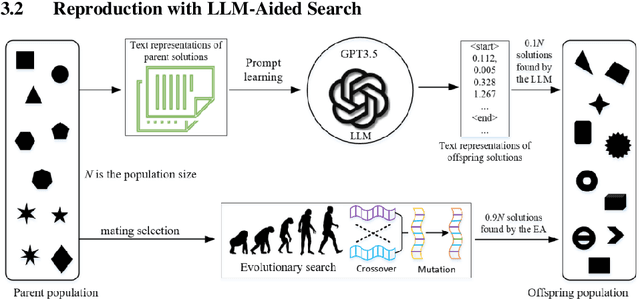
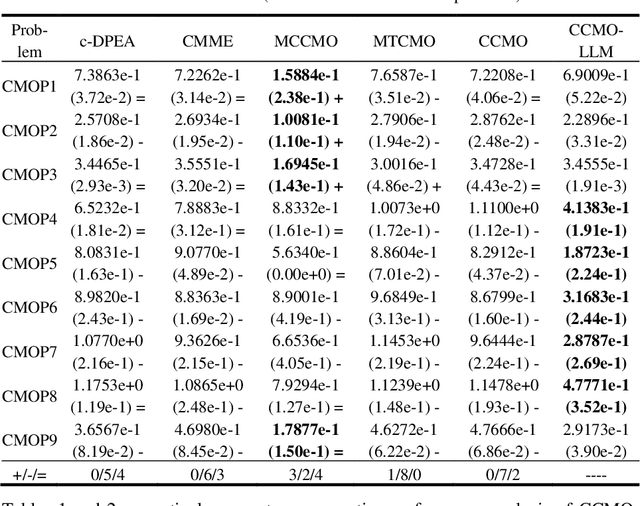
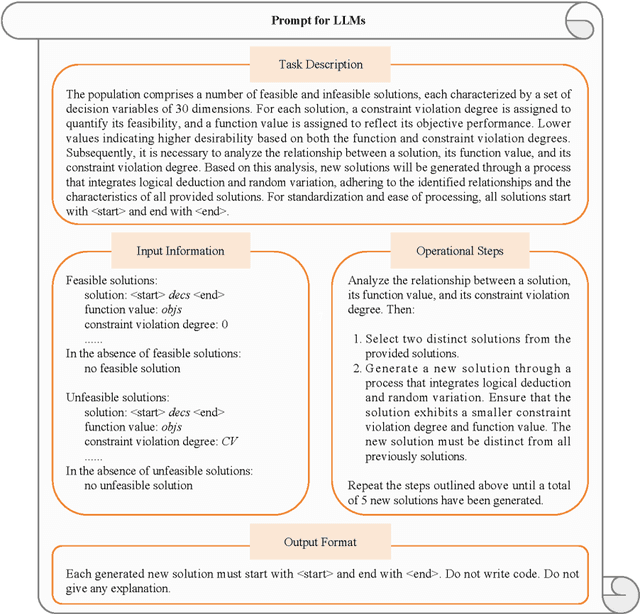
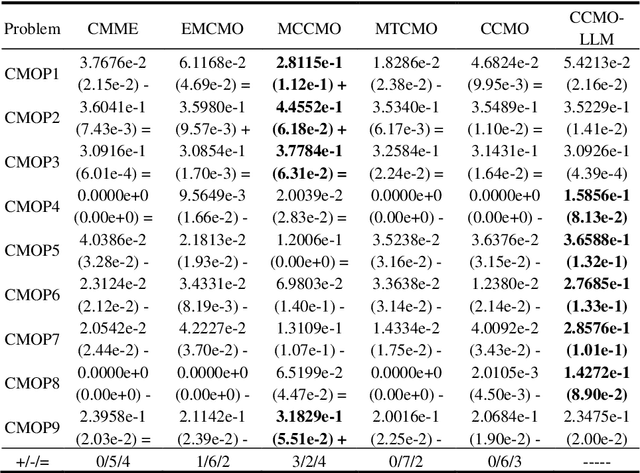
Evolutionary algorithms excel in solving complex optimization problems, especially those with multiple objectives. However, their stochastic nature can sometimes hinder rapid convergence to the global optima, particularly in scenarios involving constraints. In this study, we employ a large language model (LLM) to enhance evolutionary search for solving constrained multi-objective optimization problems. Our aim is to speed up the convergence of the evolutionary population. To achieve this, we finetune the LLM through tailored prompt engineering, integrating information concerning both objective values and constraint violations of solutions. This process enables the LLM to grasp the relationship between well-performing and poorly performing solutions based on the provided input data. Solution's quality is assessed based on their constraint violations and objective-based performance. By leveraging the refined LLM, it can be used as a search operator to generate superior-quality solutions. Experimental evaluations across various test benchmarks illustrate that LLM-aided evolutionary search can significantly accelerate the population's convergence speed and stands out competitively against cutting-edge evolutionary algorithms.
MMOCR: A Comprehensive Toolbox for Text Detection, Recognition and Understanding
Aug 14, 2021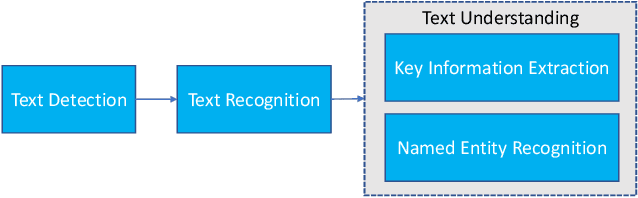



We present MMOCR-an open-source toolbox which provides a comprehensive pipeline for text detection and recognition, as well as their downstream tasks such as named entity recognition and key information extraction. MMOCR implements 14 state-of-the-art algorithms, which is significantly more than all the existing open-source OCR projects we are aware of to date. To facilitate future research and industrial applications of text recognition-related problems, we also provide a large number of trained models and detailed benchmarks to give insights into the performance of text detection, recognition and understanding. MMOCR is publicly released at https://github.com/open-mmlab/mmocr.
Fourier Contour Embedding for Arbitrary-Shaped Text Detection
Apr 22, 2021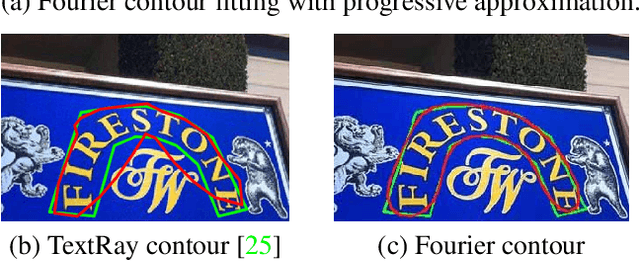
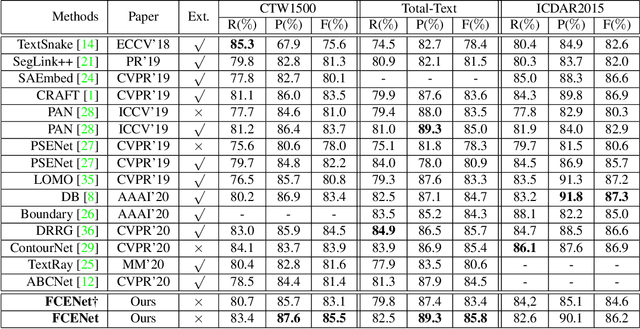
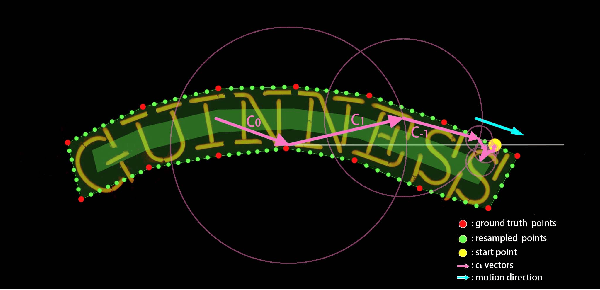
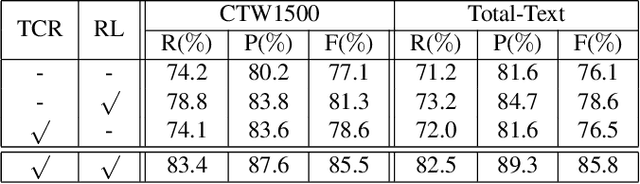
One of the main challenges for arbitrary-shaped text detection is to design a good text instance representation that allows networks to learn diverse text geometry variances. Most of existing methods model text instances in image spatial domain via masks or contour point sequences in the Cartesian or the polar coordinate system. However, the mask representation might lead to expensive post-processing, while the point sequence one may have limited capability to model texts with highly-curved shapes. To tackle these problems, we model text instances in the Fourier domain and propose one novel Fourier Contour Embedding (FCE) method to represent arbitrary shaped text contours as compact signatures. We further construct FCENet with a backbone, feature pyramid networks (FPN) and a simple post-processing with the Inverse Fourier Transformation (IFT) and Non-Maximum Suppression (NMS). Different from previous methods, FCENet first predicts compact Fourier signatures of text instances, and then reconstructs text contours via IFT and NMS during test. Extensive experiments demonstrate that FCE is accurate and robust to fit contours of scene texts even with highly-curved shapes, and also validate the effectiveness and the good generalization of FCENet for arbitrary-shaped text detection. Furthermore, experimental results show that our FCENet is superior to the state-of-the-art (SOTA) methods on CTW1500 and Total-Text, especially on challenging highly-curved text subset.