 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReplayCAD: Generative Diffusion Replay for Continual Anomaly Detection
May 10, 2025



Continual Anomaly Detection (CAD) enables anomaly detection models in learning new classes while preserving knowledge of historical classes. CAD faces two key challenges: catastrophic forgetting and segmentation of small anomalous regions. Existing CAD methods store image distributions or patch features to mitigate catastrophic forgetting, but they fail to preserve pixel-level detailed features for accurate segmentation. To overcome this limitation, we propose ReplayCAD, a novel diffusion-driven generative replay framework that replay high-quality historical data, thus effectively preserving pixel-level detailed features. Specifically, we compress historical data by searching for a class semantic embedding in the conditional space of the pre-trained diffusion model, which can guide the model to replay data with fine-grained pixel details, thus improving the segmentation performance. However, relying solely on semantic features results in limited spatial diversity. Hence, we further use spatial features to guide data compression, achieving precise control of sample space, thereby generating more diverse data. Our method achieves state-of-the-art performance in both classification and segmentation, with notable improvements in segmentation: 11.5% on VisA and 8.1% on MVTec. Our source code is available at https://github.com/HULEI7/ReplayCAD.
KMTalk: Speech-Driven 3D Facial Animation with Key Motion Embedding
Sep 02, 2024We present a novel approach for synthesizing 3D facial motions from audio sequences using key motion embeddings. Despite recent advancements in data-driven techniques, accurately mapping between audio signals and 3D facial meshes remains challenging. Direct regression of the entire sequence often leads to over-smoothed results due to the ill-posed nature of the problem. To this end, we propose a progressive learning mechanism that generates 3D facial animations by introducing key motion capture to decrease cross-modal mapping uncertainty and learning complexity. Concretely, our method integrates linguistic and data-driven priors through two modules: the linguistic-based key motion acquisition and the cross-modal motion completion. The former identifies key motions and learns the associated 3D facial expressions, ensuring accurate lip-speech synchronization. The latter extends key motions into a full sequence of 3D talking faces guided by audio features, improving temporal coherence and audio-visual consistency. Extensive experimental comparisons against existing state-of-the-art methods demonstrate the superiority of our approach in generating more vivid and consistent talking face animations. Consistent enhancements in results through the integration of our proposed learning scheme with existing methods underscore the efficacy of our approach. Our code and weights will be at the project website: \url{https://github.com/ffxzh/KMTalk}.
A Multi-Stage Goal-Driven Network for Pedestrian Trajectory Prediction
Jun 26, 2024



Pedestrian trajectory prediction plays a pivotal role in ensuring the safety and efficiency of various applications, including autonomous vehicles and traffic management systems. This paper proposes a novel method for pedestrian trajectory prediction, called multi-stage goal-driven network (MGNet). Diverging from prior approaches relying on stepwise recursive prediction and the singular forecasting of a long-term goal, MGNet directs trajectory generation by forecasting intermediate stage goals, thereby reducing prediction errors. The network comprises three main components: a conditional variational autoencoder (CVAE), an attention module, and a multi-stage goal evaluator. Trajectories are encoded using conditional variational autoencoders to acquire knowledge about the approximate distribution of pedestrians' future trajectories, and combined with an attention mechanism to capture the temporal dependency between trajectory sequences. The pivotal module is the multi-stage goal evaluator, which utilizes the encoded feature vectors to predict intermediate goals, effectively minimizing cumulative errors in the recursive inference process. The effectiveness of MGNet is demonstrated through comprehensive experiments on the JAAD and PIE datasets. Comparative evaluations against state-of-the-art algorithms reveal significant performance improvements achieved by our proposed method.
Towards Efficient Information Fusion: Concentric Dual Fusion Attention Based Multiple Instance Learning for Whole Slide Images
Mar 21, 2024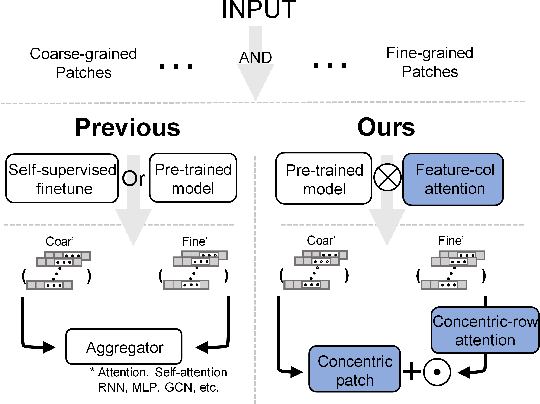
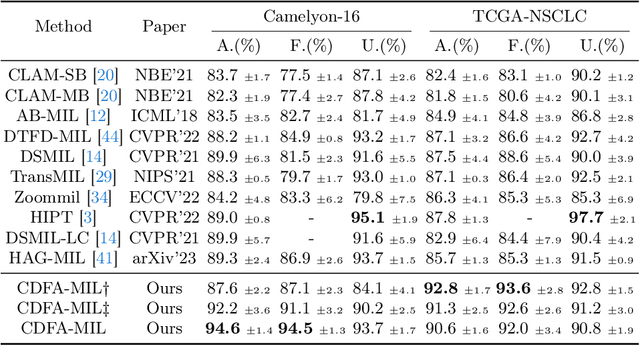
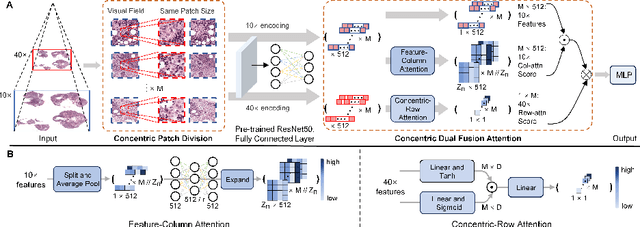

In the realm of digital pathology, multi-magnification Multiple Instance Learning (multi-mag MIL) has proven effective in leveraging the hierarchical structure of Whole Slide Images (WSIs) to reduce information loss and redundant data. However, current methods fall short in bridging the domain gap between pretrained models and medical imaging, and often fail to account for spatial relationships across different magnifications. Addressing these challenges, we introduce the Concentric Dual Fusion Attention-MIL (CDFA-MIL) framework,which innovatively combines point-to-area feature-colum attention and point-to-point concentric-row attention using concentric patch. This approach is designed to effectively fuse correlated information, enhancing feature representation and providing stronger correlation guidance for WSI analysis. CDFA-MIL distinguishes itself by offering a robust fusion strategy that leads to superior WSI recognition. Its application has demonstrated exceptional performance, significantly surpassing existing MIL methods in accuracy and F1 scores on prominent datasets like Camelyon16 and TCGA-NSCLC. Specifically, CDFA-MIL achieved an average accuracy and F1-score of 93.7\% and 94.1\% respectively on these datasets, marking a notable advancement over traditional MIL approaches.
CVSformer: Cross-View Synthesis Transformer for Semantic Scene Completion
Jul 16, 2023Semantic scene completion (SSC) requires an accurate understanding of the geometric and semantic relationships between the objects in the 3D scene for reasoning the occluded objects. The popular SSC methods voxelize the 3D objects, allowing the deep 3D convolutional network (3D CNN) to learn the object relationships from the complex scenes. However, the current networks lack the controllable kernels to model the object relationship across multiple views, where appropriate views provide the relevant information for suggesting the existence of the occluded objects. In this paper, we propose Cross-View Synthesis Transformer (CVSformer), which consists of Multi-View Feature Synthesis and Cross-View Transformer for learning cross-view object relationships. In the multi-view feature synthesis, we use a set of 3D convolutional kernels rotated differently to compute the multi-view features for each voxel. In the cross-view transformer, we employ the cross-view fusion to comprehensively learn the cross-view relationships, which form useful information for enhancing the features of individual views. We use the enhanced features to predict the geometric occupancies and semantic labels of all voxels. We evaluate CVSformer on public datasets, where CVSformer yields state-of-the-art results.
Spatio-Temporal Context Modeling for Road Obstacle Detection
Jan 19, 2023Road obstacle detection is an important problem for vehicle driving safety. In this paper, we aim to obtain robust road obstacle detection based on spatio-temporal context modeling. Firstly, a data-driven spatial context model of the driving scene is constructed with the layouts of the training data. Then, obstacles in the input image are detected via the state-of-the-art object detection algorithms, and the results are combined with the generated scene layout. In addition, to further improve the performance and robustness, temporal information in the image sequence is taken into consideration, and the optical flow is obtained in the vicinity of the detected objects to track the obstacles across neighboring frames. Qualitative and quantitative experiments were conducted on the Small Obstacle Detection (SOD) dataset and the Lost and Found dataset. The results indicate that our method with spatio-temporal context modeling is superior to existing methods for road obstacle detection.
A Multi-Scale Framework for Out-of-Distribution Detection in Dermoscopic Images
Jan 18, 2023The automatic detection of skin diseases via dermoscopic images can improve the efficiency in diagnosis and help doctors make more accurate judgments. However, conventional skin disease recognition systems may produce high confidence for out-of-distribution (OOD) data, which may become a major security vulnerability in practical applications. In this paper, we propose a multi-scale detection framework to detect out-of-distribution skin disease image data to ensure the robustness of the system. Our framework extracts features from different layers of the neural network. In the early layers, rectified activation is used to make the output features closer to the well-behaved distribution, and then an one-class SVM is trained to detect OOD data; in the penultimate layer, an adapted Gram matrix is used to calculate the features after rectified activation, and finally the layer with the best performance is chosen to compute a normality score. Experiments show that the proposed framework achieves superior performance when compared with other state-of-the-art methods in the task of skin disease recognition.
Fourier Contour Embedding for Arbitrary-Shaped Text Detection
Apr 22, 2021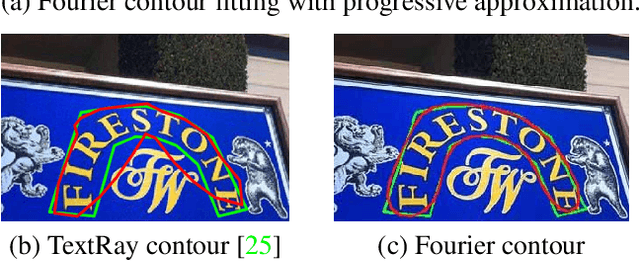
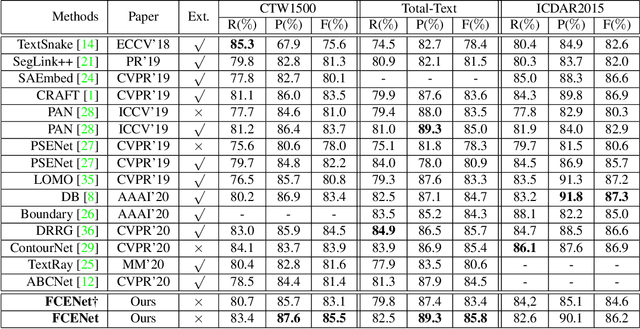
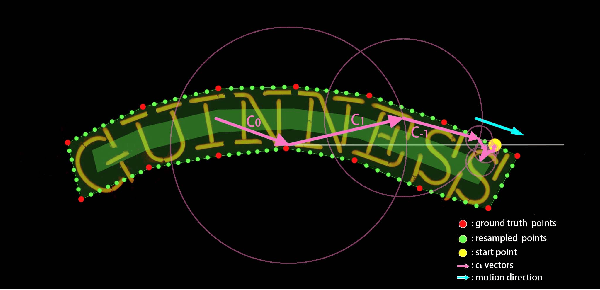
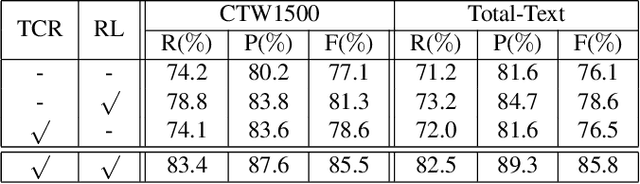
One of the main challenges for arbitrary-shaped text detection is to design a good text instance representation that allows networks to learn diverse text geometry variances. Most of existing methods model text instances in image spatial domain via masks or contour point sequences in the Cartesian or the polar coordinate system. However, the mask representation might lead to expensive post-processing, while the point sequence one may have limited capability to model texts with highly-curved shapes. To tackle these problems, we model text instances in the Fourier domain and propose one novel Fourier Contour Embedding (FCE) method to represent arbitrary shaped text contours as compact signatures. We further construct FCENet with a backbone, feature pyramid networks (FPN) and a simple post-processing with the Inverse Fourier Transformation (IFT) and Non-Maximum Suppression (NMS). Different from previous methods, FCENet first predicts compact Fourier signatures of text instances, and then reconstructs text contours via IFT and NMS during test. Extensive experiments demonstrate that FCE is accurate and robust to fit contours of scene texts even with highly-curved shapes, and also validate the effectiveness and the good generalization of FCENet for arbitrary-shaped text detection. Furthermore, experimental results show that our FCENet is superior to the state-of-the-art (SOTA) methods on CTW1500 and Total-Text, especially on challenging highly-curved text subset.
A Multi-Level Approach to Waste Object Segmentation
Jul 08, 2020

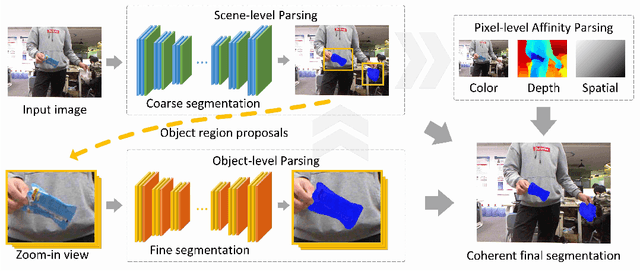
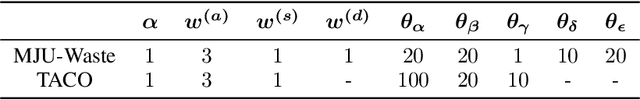
We address the problem of localizing waste objects from a color image and an optional depth image, which is a key perception component for robotic interaction with such objects. Specifically, our method integrates the intensity and depth information at multiple levels of spatial granularity. Firstly, a scene-level deep network produces an initial coarse segmentation, based on which we select a few potential object regions to zoom in and perform fine segmentation. The results of the above steps are further integrated into a densely connected conditional random field that learns to respect the appearance, depth, and spatial affinities with pixel-level accuracy. In addition, we create a new RGBD waste object segmentation dataset, MJU-Waste, that is made public to facilitate future research in this area. The efficacy of our method is validated on both MJU-Waste and the Trash Annotation in Context (TACO) dataset.
SCUT-FBP5500: A Diverse Benchmark Dataset for Multi-Paradigm Facial Beauty Prediction
Jan 19, 2018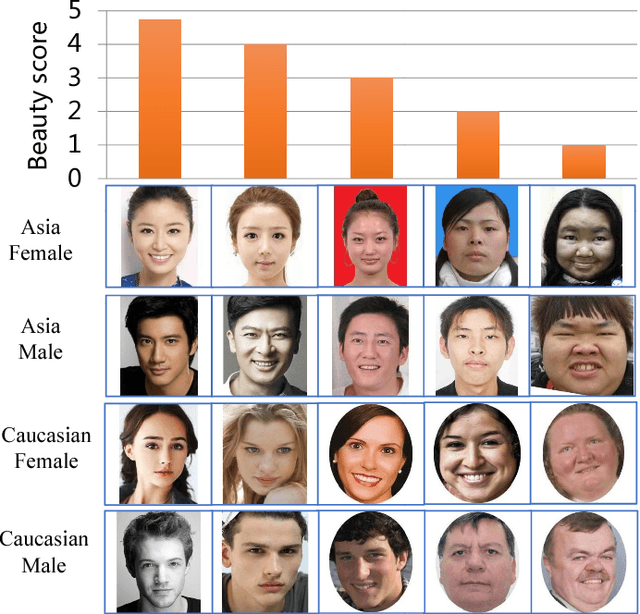
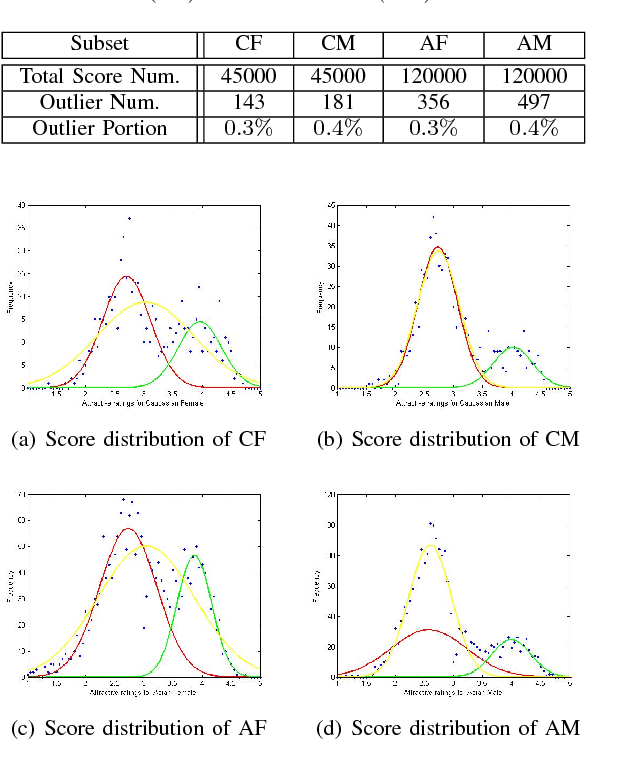

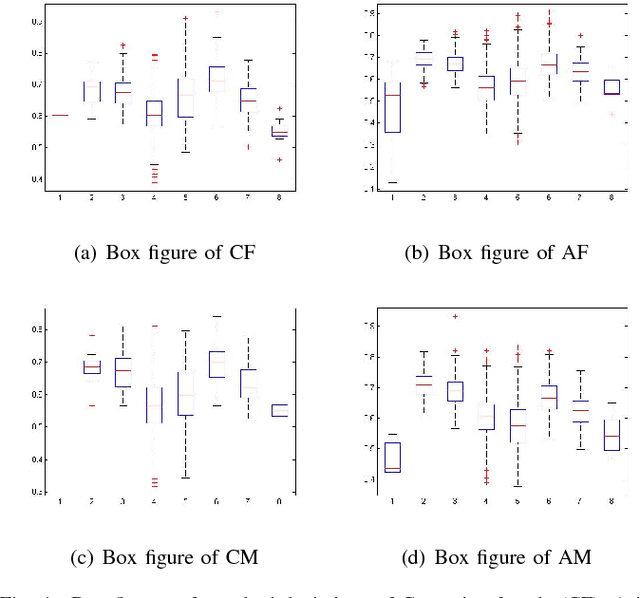
Facial beauty prediction (FBP) is a significant visual recognition problem to make assessment of facial attractiveness that is consistent to human perception. To tackle this problem, various data-driven models, especially state-of-the-art deep learning techniques, were introduced, and benchmark dataset become one of the essential elements to achieve FBP. Previous works have formulated the recognition of facial beauty as a specific supervised learning problem of classification, regression or ranking, which indicates that FBP is intrinsically a computation problem with multiple paradigms. However, most of FBP benchmark datasets were built under specific computation constrains, which limits the performance and flexibility of the computational model trained on the dataset. In this paper, we argue that FBP is a multi-paradigm computation problem, and propose a new diverse benchmark dataset, called SCUT-FBP5500, to achieve multi-paradigm facial beauty prediction. The SCUT-FBP5500 dataset has totally 5500 frontal faces with diverse properties (male/female, Asian/Caucasian, ages) and diverse labels (face landmarks, beauty scores within [1,~5], beauty score distribution), which allows different computational models with different FBP paradigms, such as appearance-based/shape-based facial beauty classification/regression model for male/female of Asian/Caucasian. We evaluated the SCUT-FBP5500 dataset for FBP using different combinations of feature and predictor, and various deep learning methods. The results indicates the improvement of FBP and the potential applications based on the SCUT-FBP5500.