 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVVS: Accelerating Speculative Decoding for Visual Autoregressive Generation via Partial Verification Skipping
Nov 17, 2025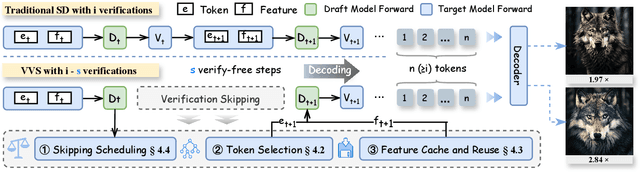
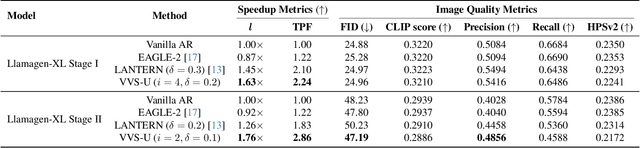
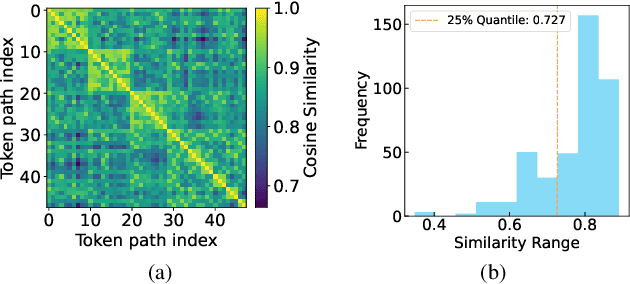
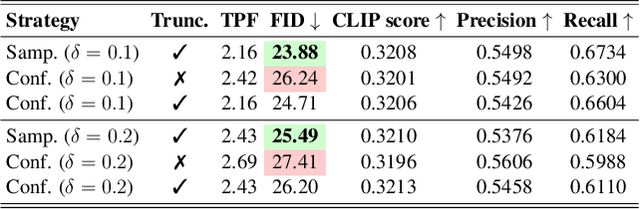
Visual autoregressive (AR) generation models have demonstrated strong potential for image generation, yet their next-token-prediction paradigm introduces considerable inference latency. Although speculative decoding (SD) has been proven effective for accelerating visual AR models, its "draft one step, then verify one step" paradigm prevents a direct reduction of the forward passes, thus restricting acceleration potential. Motivated by the visual token interchangeability, we for the first time to explore verification skipping in the SD process of visual AR model generation to explicitly cut the number of target model forward passes, thereby reducing inference latency. Based on an analysis of the drafting stage's characteristics, we observe that verification redundancy and stale feature reusability are key factors to retain generation quality and speedup for verification-free steps. Inspired by these two observations, we propose a novel SD framework VVS to accelerate visual AR generation via partial verification skipping, which integrates three complementary modules: (1) a verification-free token selector with dynamical truncation, (2) token-level feature caching and reuse, and (3) fine-grained skipped step scheduling. Consequently, VVS reduces the number of target model forward passes by a factor of $2.8\times$ relative to vanilla AR decoding while maintaining competitive generation quality, offering a superior speed-quality trade-off over conventional SD frameworks and revealing strong potential to reshape the SD paradigm.
DeCo-SGD: Joint Optimization of Delay Staleness and Gradient Compression Ratio for Distributed SGD
Jul 23, 2025Distributed machine learning in high end-to-end latency and low, varying bandwidth network environments undergoes severe throughput degradation. Due to its low communication requirements, distributed SGD (D-SGD) remains the mainstream optimizer in such challenging networks, but it still suffers from significant throughput reduction. To mitigate these limitations, existing approaches typically employ gradient compression and delayed aggregation to alleviate low bandwidth and high latency, respectively. To address both challenges simultaneously, these strategies are often combined, introducing a complex three-way trade-off among compression ratio, staleness (delayed synchronization steps), and model convergence rate. To achieve the balance under varying bandwidth conditions, an adaptive policy is required to dynamically adjust these parameters. Unfortunately, existing works rely on static heuristic strategies due to the lack of theoretical guidance, which prevents them from achieving this goal. This study fills in this theoretical gap by introducing a new theoretical tool, decomposing the joint optimization problem into a traditional convergence rate analysis with multiple analyzable noise terms. We are the first to reveal that staleness exponentially amplifies the negative impact of gradient compression on training performance, filling a critical gap in understanding how compressed and delayed gradients affect training. Furthermore, by integrating the convergence rate with a network-aware time minimization condition, we propose DeCo-SGD, which dynamically adjusts the compression ratio and staleness based on the real-time network condition and training task. DeCo-SGD achieves up to 5.07 and 1.37 speed-ups over D-SGD and static strategy in high-latency and low, varying bandwidth networks, respectively.
NoiseController: Towards Consistent Multi-view Video Generation via Noise Decomposition and Collaboration
Apr 25, 2025High-quality video generation is crucial for many fields, including the film industry and autonomous driving. However, generating videos with spatiotemporal consistencies remains challenging. Current methods typically utilize attention mechanisms or modify noise to achieve consistent videos, neglecting global spatiotemporal information that could help ensure spatial and temporal consistency during video generation. In this paper, we propose the NoiseController, consisting of Multi-Level Noise Decomposition, Multi-Frame Noise Collaboration, and Joint Denoising, to enhance spatiotemporal consistencies in video generation. In multi-level noise decomposition, we first decompose initial noises into scene-level foreground/background noises, capturing distinct motion properties to model multi-view foreground/background variations. Furthermore, each scene-level noise is further decomposed into individual-level shared and residual components. The shared noise preserves consistency, while the residual component maintains diversity. In multi-frame noise collaboration, we introduce an inter-view spatiotemporal collaboration matrix and an intra-view impact collaboration matrix , which captures mutual cross-view effects and historical cross-frame impacts to enhance video quality. The joint denoising contains two parallel denoising U-Nets to remove each scene-level noise, mutually enhancing video generation. We evaluate our NoiseController on public datasets focusing on video generation and downstream tasks, demonstrating its state-of-the-art performance.
Natural-language-driven Simulation Benchmark and Copilot for Efficient Production of Object Interactions in Virtual Road Scenes
Dec 15, 2023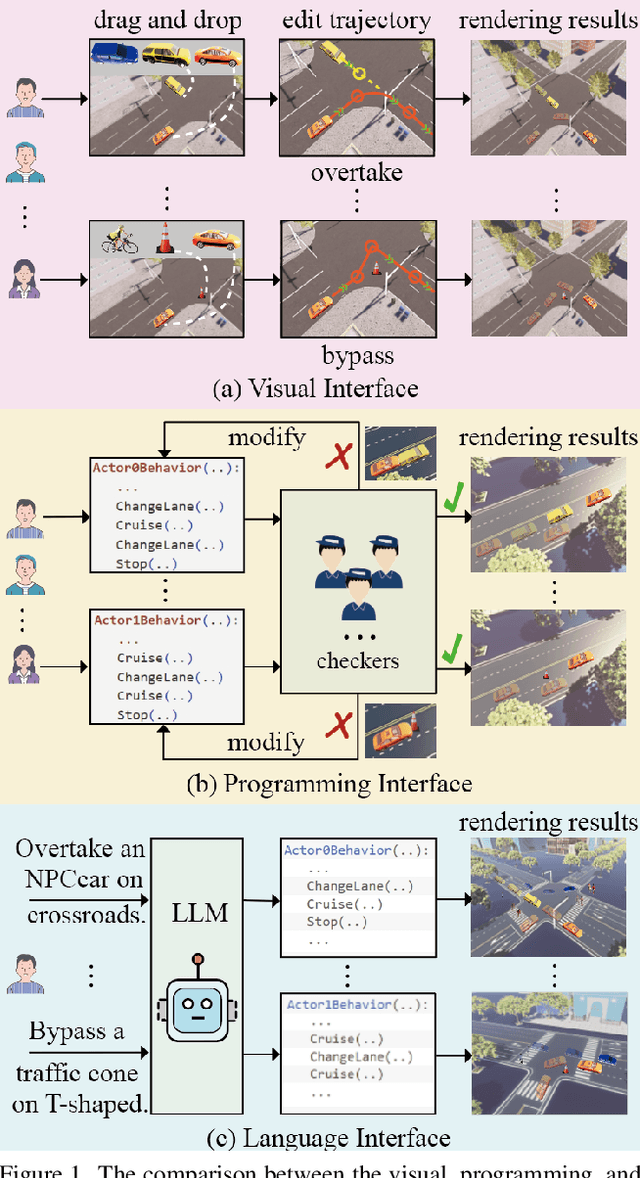

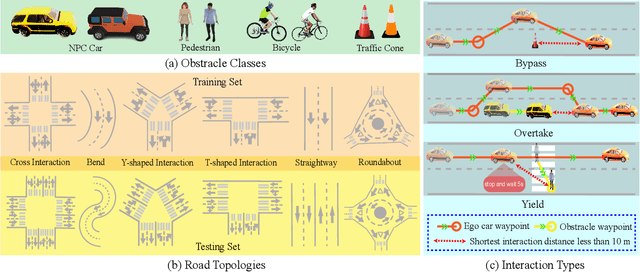

We advocate the idea of the natural-language-driven(NLD) simulation to efficiently produce the object interactions between multiple objects in the virtual road scenes, for teaching and testing the autonomous driving systems that should take quick action to avoid collision with obstacles with unpredictable motions. The NLD simulation allows the brief natural-language description to control the object interactions, significantly reducing the human efforts for creating a large amount of interaction data. To facilitate the research of NLD simulation, we collect the Language-to-Interaction(L2I) benchmark dataset with 120,000 natural-language descriptions of object interactions in 6 common types of road topologies. Each description is associated with the programming code, which the graphic render can use to visually reconstruct the object interactions in the virtual scenes. As a methodology contribution, we design SimCopilot to translate the interaction descriptions to the renderable code. We use the L2I dataset to evaluate SimCopilot's abilities to control the object motions, generate complex interactions, and generalize interactions across road topologies. The L2I dataset and the evaluation results motivate the relevant research of the NLD simulation.
CVSformer: Cross-View Synthesis Transformer for Semantic Scene Completion
Jul 16, 2023Semantic scene completion (SSC) requires an accurate understanding of the geometric and semantic relationships between the objects in the 3D scene for reasoning the occluded objects. The popular SSC methods voxelize the 3D objects, allowing the deep 3D convolutional network (3D CNN) to learn the object relationships from the complex scenes. However, the current networks lack the controllable kernels to model the object relationship across multiple views, where appropriate views provide the relevant information for suggesting the existence of the occluded objects. In this paper, we propose Cross-View Synthesis Transformer (CVSformer), which consists of Multi-View Feature Synthesis and Cross-View Transformer for learning cross-view object relationships. In the multi-view feature synthesis, we use a set of 3D convolutional kernels rotated differently to compute the multi-view features for each voxel. In the cross-view transformer, we employ the cross-view fusion to comprehensively learn the cross-view relationships, which form useful information for enhancing the features of individual views. We use the enhanced features to predict the geometric occupancies and semantic labels of all voxels. We evaluate CVSformer on public datasets, where CVSformer yields state-of-the-art results.