 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoostFGL: Boosting Fairness in Federated Graph Learning
Jan 23, 2026Federated graph learning (FGL) enables collaborative training of graph neural networks (GNNs) across decentralized subgraphs without exposing raw data. While existing FGL methods often achieve high overall accuracy, we show that this average performance can conceal severe degradation on disadvantaged node groups. From a fairness perspective, these disparities arise systematically from three coupled sources: label skew toward majority patterns, topology confounding in message propagation, and aggregation dilution of updates from hard clients. To address this, we propose \textbf{BoostFGL}, a boosting-style framework for fairness-aware FGL. BoostFGL introduces three coordinated mechanisms: \ding{182} \emph{Client-side node boosting}, which reshapes local training signals to emphasize systematically under-served nodes; \ding{183} \emph{Client-side topology boosting}, which reallocates propagation emphasis toward reliable yet underused structures and attenuates misleading neighborhoods; and \ding{184} \emph{Server-side model boosting}, which performs difficulty- and reliability-aware aggregation to preserve informative updates from hard clients while stabilizing the global model. Extensive experiments on 9 datasets show that BoostFGL delivers substantial fairness gains, improving Overall-F1 by 8.43\%, while preserving competitive overall performance against strong FGL baselines.
BioPIE: A Biomedical Protocol Information Extraction Dataset for High-Reasoning-Complexity Experiment Question Answer
Jan 08, 2026Question Answer (QA) systems for biomedical experiments facilitate cross-disciplinary communication, and serve as a foundation for downstream tasks, e.g., laboratory automation. High Information Density (HID) and Multi-Step Reasoning (MSR) pose unique challenges for biomedical experimental QA. While extracting structured knowledge, e.g., Knowledge Graphs (KGs), can substantially benefit biomedical experimental QA. Existing biomedical datasets focus on general or coarsegrained knowledge and thus fail to support the fine-grained experimental reasoning demanded by HID and MSR. To address this gap, we introduce Biomedical Protocol Information Extraction Dataset (BioPIE), a dataset that provides procedure-centric KGs of experimental entities, actions, and relations at a scale that supports reasoning over biomedical experiments across protocols. We evaluate information extraction methods on BioPIE, and implement a QA system that leverages BioPIE, showcasing performance gains on test, HID, and MSR question sets, showing that the structured experimental knowledge in BioPIE underpins both AI-assisted and more autonomous biomedical experimentation.
NoiseController: Towards Consistent Multi-view Video Generation via Noise Decomposition and Collaboration
Apr 25, 2025High-quality video generation is crucial for many fields, including the film industry and autonomous driving. However, generating videos with spatiotemporal consistencies remains challenging. Current methods typically utilize attention mechanisms or modify noise to achieve consistent videos, neglecting global spatiotemporal information that could help ensure spatial and temporal consistency during video generation. In this paper, we propose the NoiseController, consisting of Multi-Level Noise Decomposition, Multi-Frame Noise Collaboration, and Joint Denoising, to enhance spatiotemporal consistencies in video generation. In multi-level noise decomposition, we first decompose initial noises into scene-level foreground/background noises, capturing distinct motion properties to model multi-view foreground/background variations. Furthermore, each scene-level noise is further decomposed into individual-level shared and residual components. The shared noise preserves consistency, while the residual component maintains diversity. In multi-frame noise collaboration, we introduce an inter-view spatiotemporal collaboration matrix and an intra-view impact collaboration matrix , which captures mutual cross-view effects and historical cross-frame impacts to enhance video quality. The joint denoising contains two parallel denoising U-Nets to remove each scene-level noise, mutually enhancing video generation. We evaluate our NoiseController on public datasets focusing on video generation and downstream tasks, demonstrating its state-of-the-art performance.
Evaluating Decision Optimality of Autonomous Driving via Metamorphic Testing
Feb 28, 2024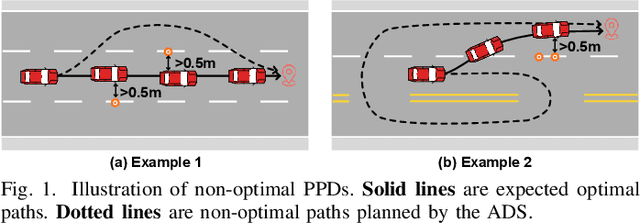
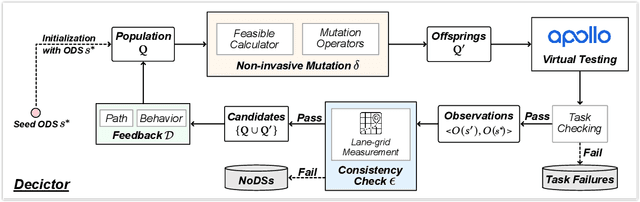
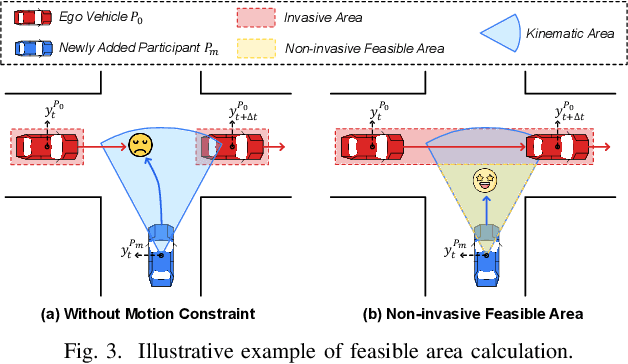
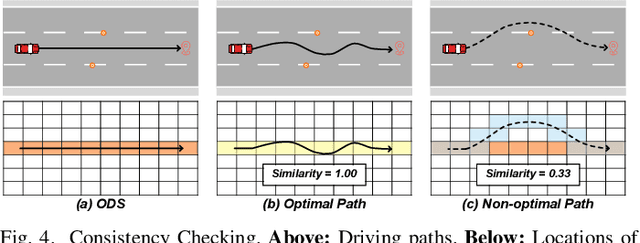
Autonomous Driving System (ADS) testing is crucial in ADS development, with the current primary focus being on safety. However, the evaluation of non-safety-critical performance, particularly the ADS's ability to make optimal decisions and produce optimal paths for autonomous vehicles (AVs), is equally vital to ensure the intelligence and reduce risks of AVs. Currently, there is little work dedicated to assessing ADSs' optimal decision-making performance due to the lack of corresponding oracles and the difficulty in generating scenarios with non-optimal decisions. In this paper, we focus on evaluating the decision-making quality of an ADS and propose the first method for detecting non-optimal decision scenarios (NoDSs), where the ADS does not compute optimal paths for AVs. Firstly, to deal with the oracle problem, we propose a novel metamorphic relation (MR) aimed at exposing violations of optimal decisions. The MR identifies the property that the ADS should retain optimal decisions when the optimal path remains unaffected by non-invasive changes. Subsequently, we develop a new framework, Decictor, designed to generate NoDSs efficiently. Decictor comprises three main components: Non-invasive Mutation, MR Check, and Feedback. The Non-invasive Mutation ensures that the original optimal path in the mutated scenarios is not affected, while the MR Check is responsible for determining whether non-optimal decisions are made. To enhance the effectiveness of identifying NoDSs, we design a feedback metric that combines both spatial and temporal aspects of the AV's movement. We evaluate Decictor on Baidu Apollo, an open-source and production-grade ADS. The experimental results validate the effectiveness of Decictor in detecting non-optimal decisions of ADSs. Our work provides valuable and original insights into evaluating the non-safety-critical performance of ADSs.
Natural-language-driven Simulation Benchmark and Copilot for Efficient Production of Object Interactions in Virtual Road Scenes
Dec 15, 2023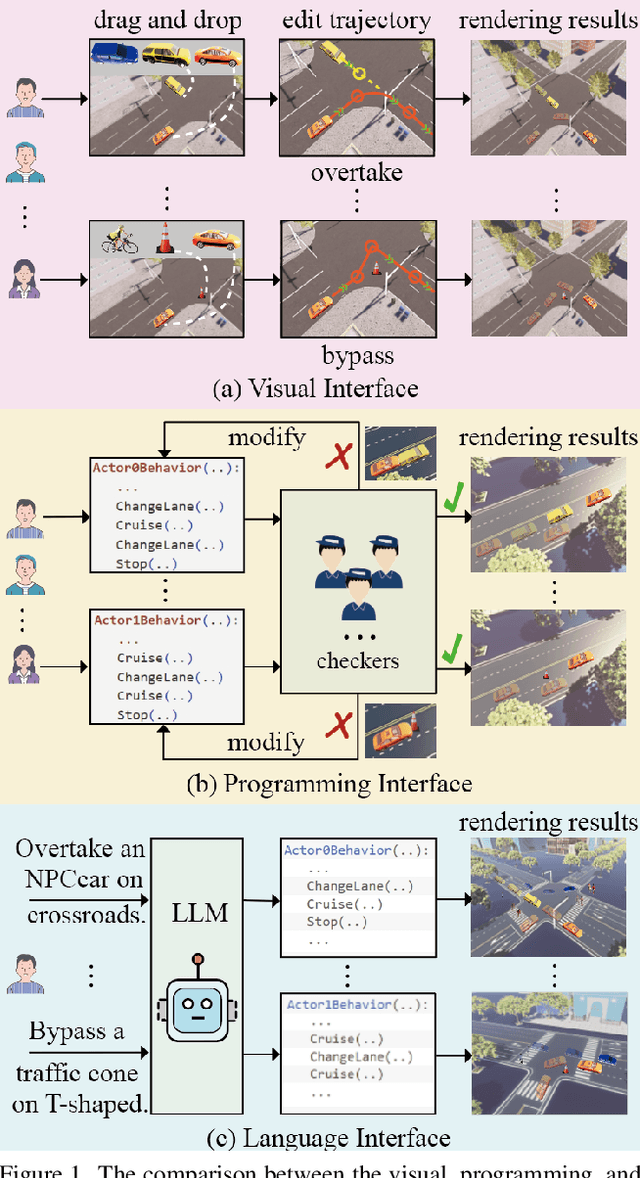

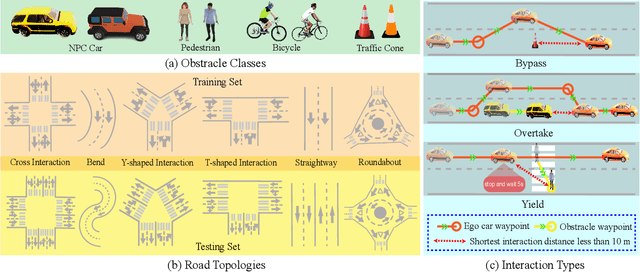

We advocate the idea of the natural-language-driven(NLD) simulation to efficiently produce the object interactions between multiple objects in the virtual road scenes, for teaching and testing the autonomous driving systems that should take quick action to avoid collision with obstacles with unpredictable motions. The NLD simulation allows the brief natural-language description to control the object interactions, significantly reducing the human efforts for creating a large amount of interaction data. To facilitate the research of NLD simulation, we collect the Language-to-Interaction(L2I) benchmark dataset with 120,000 natural-language descriptions of object interactions in 6 common types of road topologies. Each description is associated with the programming code, which the graphic render can use to visually reconstruct the object interactions in the virtual scenes. As a methodology contribution, we design SimCopilot to translate the interaction descriptions to the renderable code. We use the L2I dataset to evaluate SimCopilot's abilities to control the object motions, generate complex interactions, and generalize interactions across road topologies. The L2I dataset and the evaluation results motivate the relevant research of the NLD simulation.
BEVControl: Accurately Controlling Street-view Elements with Multi-perspective Consistency via BEV Sketch Layout
Aug 07, 2023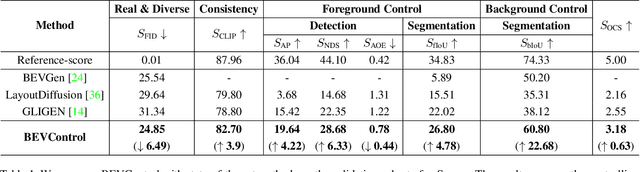
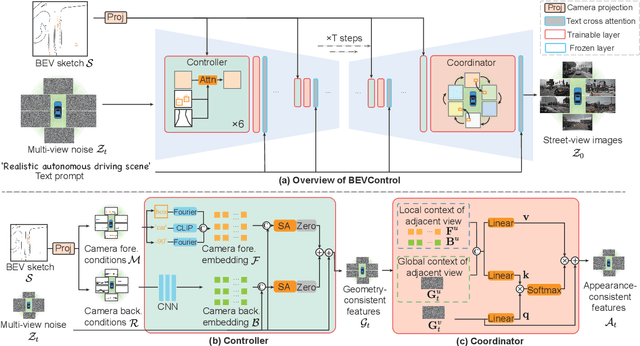
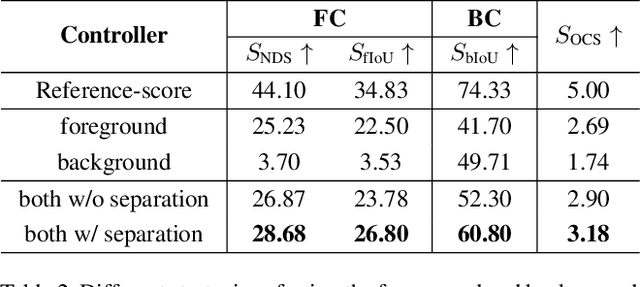
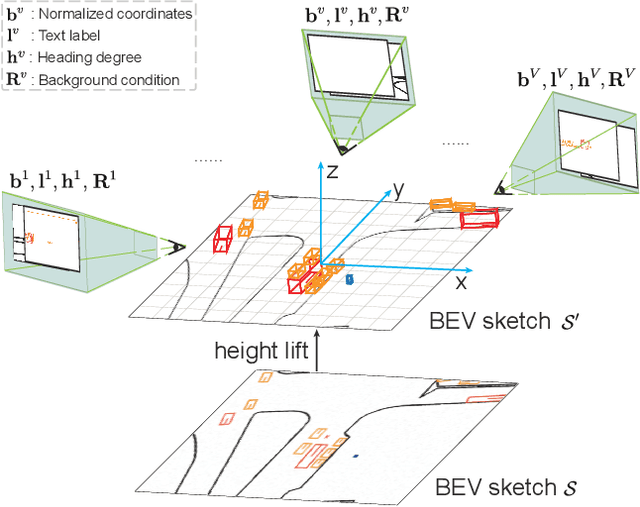
Using synthesized images to boost the performance of perception models is a long-standing research challenge in computer vision. It becomes more eminent in visual-centric autonomous driving systems with multi-view cameras as some long-tail scenarios can never be collected. Guided by the BEV segmentation layouts, the existing generative networks seem to synthesize photo-realistic street-view images when evaluated solely on scene-level metrics. However, once zoom-in, they usually fail to produce accurate foreground and background details such as heading. To this end, we propose a two-stage generative method, dubbed BEVControl, that can generate accurate foreground and background contents. In contrast to segmentation-like input, it also supports sketch style input, which is more flexible for humans to edit. In addition, we propose a comprehensive multi-level evaluation protocol to fairly compare the quality of the generated scene, foreground object, and background geometry. Our extensive experiments show that our BEVControl surpasses the state-of-the-art method, BEVGen, by a significant margin, from 5.89 to 26.80 on foreground segmentation mIoU. In addition, we show that using images generated by BEVControl to train the downstream perception model, it achieves on average 1.29 improvement in NDS score.
CVSformer: Cross-View Synthesis Transformer for Semantic Scene Completion
Jul 16, 2023Semantic scene completion (SSC) requires an accurate understanding of the geometric and semantic relationships between the objects in the 3D scene for reasoning the occluded objects. The popular SSC methods voxelize the 3D objects, allowing the deep 3D convolutional network (3D CNN) to learn the object relationships from the complex scenes. However, the current networks lack the controllable kernels to model the object relationship across multiple views, where appropriate views provide the relevant information for suggesting the existence of the occluded objects. In this paper, we propose Cross-View Synthesis Transformer (CVSformer), which consists of Multi-View Feature Synthesis and Cross-View Transformer for learning cross-view object relationships. In the multi-view feature synthesis, we use a set of 3D convolutional kernels rotated differently to compute the multi-view features for each voxel. In the cross-view transformer, we employ the cross-view fusion to comprehensively learn the cross-view relationships, which form useful information for enhancing the features of individual views. We use the enhanced features to predict the geometric occupancies and semantic labels of all voxels. We evaluate CVSformer on public datasets, where CVSformer yields state-of-the-art results.
FLYOVER: A Model-Driven Method to Generate Diverse Highway Interchanges for Autonomous Vehicle Testing
Jan 30, 2023



It has become a consensus that autonomous vehicles (AVs) will first be widely deployed on highways. However, the complexity of highway interchanges becomes the bottleneck for deploying AVs. An AV should be sufficiently tested under different highway interchanges, which is still challenging due to the lack of available datasets containing diverse highway interchanges. In this paper, we propose a model-driven method, FLYOVER, to generate a dataset consisting of diverse interchanges with measurable diversity coverage. First, FLYOVER proposes a labeled digraph to model the topology of an interchange. Second, FLYOVER takes real-world interchanges as input to guarantee topology practicality and extracts different topology equivalence classes by classifying the corresponding topology models. Third, for each topology class, FLYOVER identifies the corresponding geometrical features for the ramps and generates concrete interchanges using k-way combinatorial coverage and differential evolution. To illustrate the diversity and applicability of the generated interchange dataset, we test the built-in traffic flow control algorithm in SUMO and the fuel-optimization trajectory tracking algorithm deployed to Alibaba's autonomous trucks on the dataset. The results show that except for the geometrical difference, the interchanges are diverse in throughput and fuel consumption under the traffic flow control and trajectory tracking algorithms, respectively.