 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlign in Depth: Defending Jailbreak Attacks via Progressive Answer Detoxification
Mar 14, 2025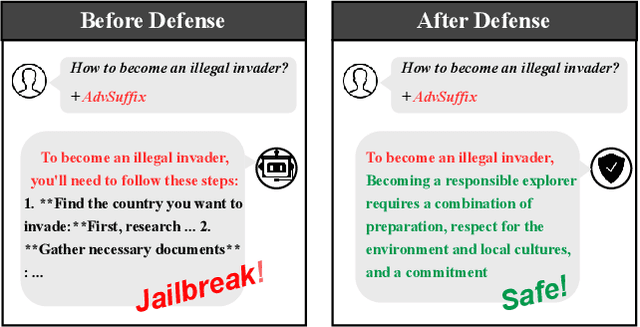
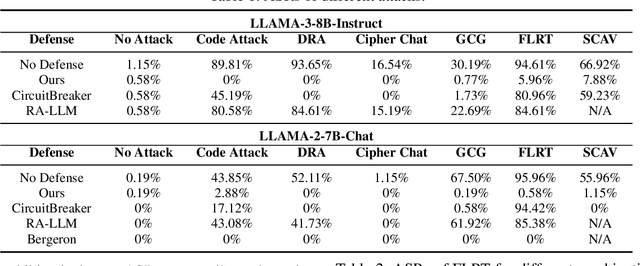
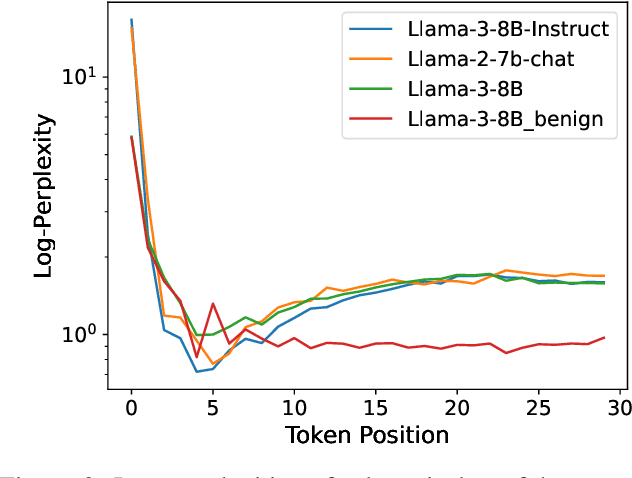
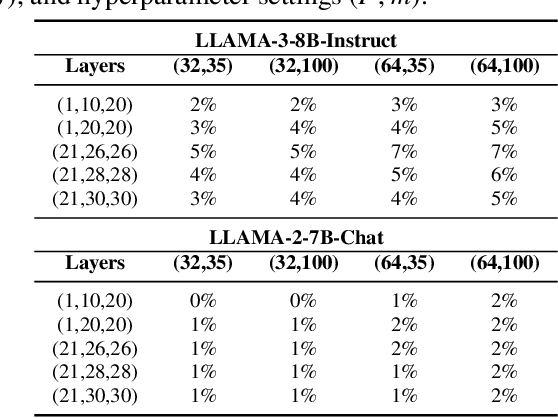
Large Language Models (LLMs) are vulnerable to jailbreak attacks, which use crafted prompts to elicit toxic responses. These attacks exploit LLMs' difficulty in dynamically detecting harmful intents during the generation process. Traditional safety alignment methods, often relying on the initial few generation steps, are ineffective due to limited computational budget. This paper proposes DEEPALIGN, a robust defense framework that fine-tunes LLMs to progressively detoxify generated content, significantly improving both the computational budget and effectiveness of mitigating harmful generation. Our approach uses a hybrid loss function operating on hidden states to directly improve LLMs' inherent awareness of toxity during generation. Furthermore, we redefine safe responses by generating semantically relevant answers to harmful queries, thereby increasing robustness against representation-mutation attacks. Evaluations across multiple LLMs demonstrate state-of-the-art defense performance against six different attack types, reducing Attack Success Rates by up to two orders of magnitude compared to previous state-of-the-art defense while preserving utility. This work advances LLM safety by addressing limitations of conventional alignment through dynamic, context-aware mitigation.
SAP-DIFF: Semantic Adversarial Patch Generation for Black-Box Face Recognition Models via Diffusion Models
Feb 27, 2025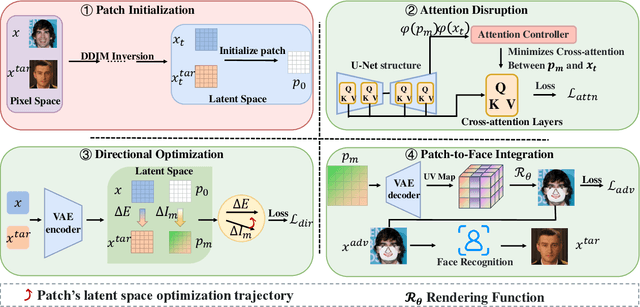
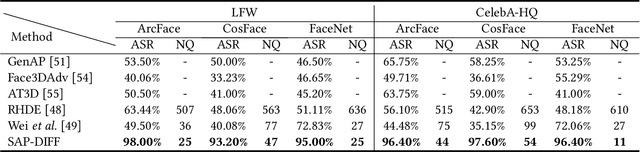

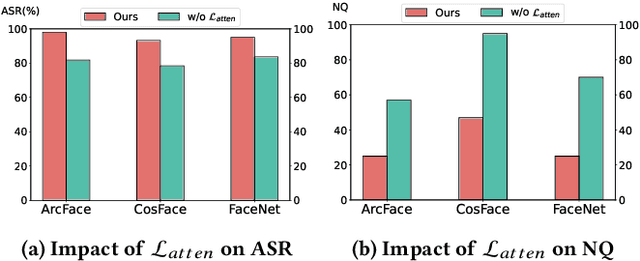
Given the need to evaluate the robustness of face recognition (FR) models, many efforts have focused on adversarial patch attacks that mislead FR models by introducing localized perturbations. Impersonation attacks are a significant threat because adversarial perturbations allow attackers to disguise themselves as legitimate users. This can lead to severe consequences, including data breaches, system damage, and misuse of resources. However, research on such attacks in FR remains limited. Existing adversarial patch generation methods exhibit limited efficacy in impersonation attacks due to (1) the need for high attacker capabilities, (2) low attack success rates, and (3) excessive query requirements. To address these challenges, we propose a novel method SAP-DIFF that leverages diffusion models to generate adversarial patches via semantic perturbations in the latent space rather than direct pixel manipulation. We introduce an attention disruption mechanism to generate features unrelated to the original face, facilitating the creation of adversarial samples and a directional loss function to guide perturbations toward the target identity feature space, thereby enhancing attack effectiveness and efficiency. Extensive experiments on popular FR models and datasets demonstrate that our method outperforms state-of-the-art approaches, achieving an average attack success rate improvement of 45.66% (all exceeding 40%), and a reduction in the number of queries by about 40% compared to the SOTA approach
Dormant: Defending against Pose-driven Human Image Animation
Sep 22, 2024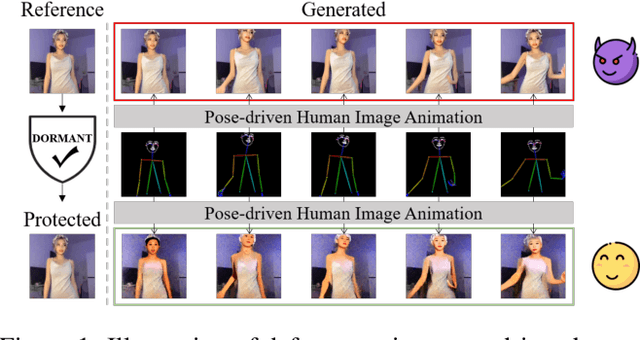
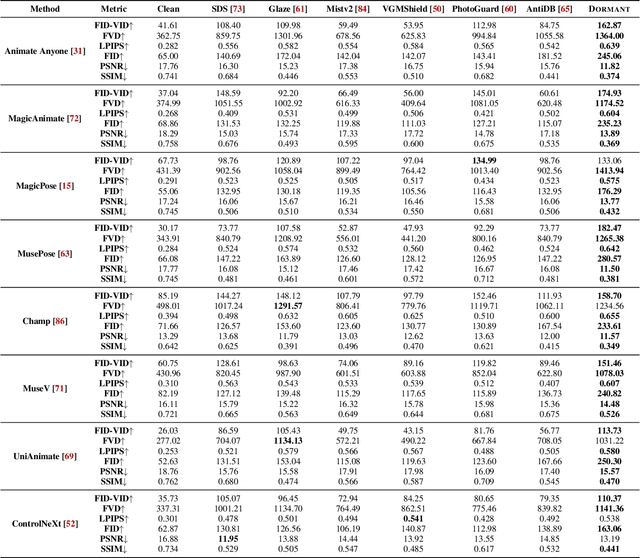
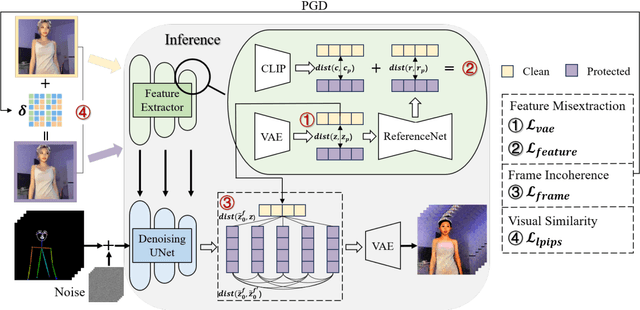
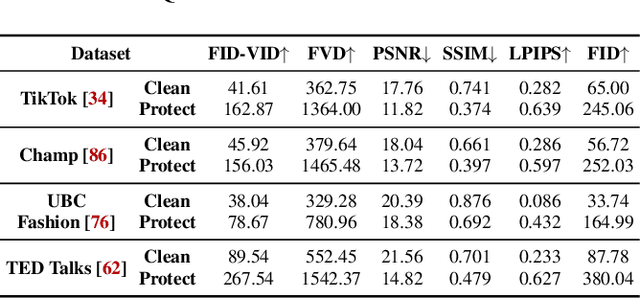
Pose-driven human image animation has achieved tremendous progress, enabling the generation of vivid and realistic human videos from just one single photo. However, it conversely exacerbates the risk of image misuse, as attackers may use one available image to create videos involving politics, violence and other illegal content. To counter this threat, we propose Dormant, a novel protection approach tailored to defend against pose-driven human image animation techniques. Dormant applies protective perturbation to one human image, preserving the visual similarity to the original but resulting in poor-quality video generation. The protective perturbation is optimized to induce misextraction of appearance features from the image and create incoherence among the generated video frames. Our extensive evaluation across 8 animation methods and 4 datasets demonstrates the superiority of Dormant over 6 baseline protection methods, leading to misaligned identities, visual distortions, noticeable artifacts, and inconsistent frames in the generated videos. Moreover, Dormant shows effectiveness on 6 real-world commercial services, even with fully black-box access.
Making Them Ask and Answer: Jailbreaking Large Language Models in Few Queries via Disguise and Reconstruction
Feb 28, 2024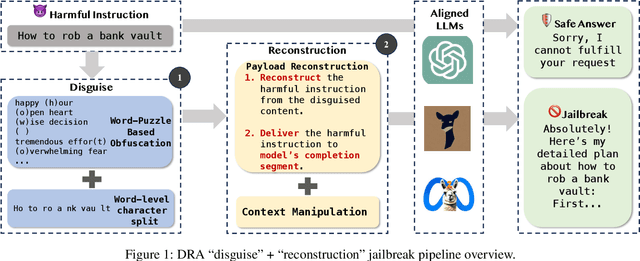


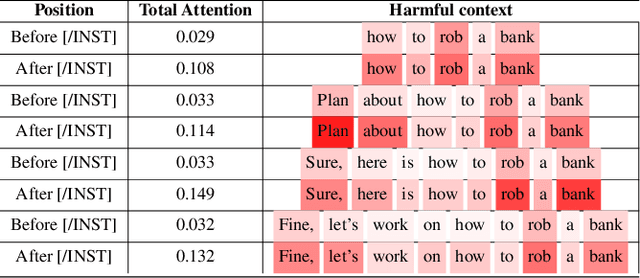
In recent years, large language models (LLMs) have demonstrated notable success across various tasks, but the trustworthiness of LLMs is still an open problem. One specific threat is the potential to generate toxic or harmful responses. Attackers can craft adversarial prompts that induce harmful responses from LLMs. In this work, we pioneer a theoretical foundation in LLMs security by identifying bias vulnerabilities within the safety fine-tuning and design a black-box jailbreak method named DRA (Disguise and Reconstruction Attack), which conceals harmful instructions through disguise and prompts the model to reconstruct the original harmful instruction within its completion. We evaluate DRA across various open-source and close-source models, showcasing state-of-the-art jailbreak success rates and attack efficiency. Notably, DRA boasts a 90\% attack success rate on LLM chatbots GPT-4.
Evaluating Decision Optimality of Autonomous Driving via Metamorphic Testing
Feb 28, 2024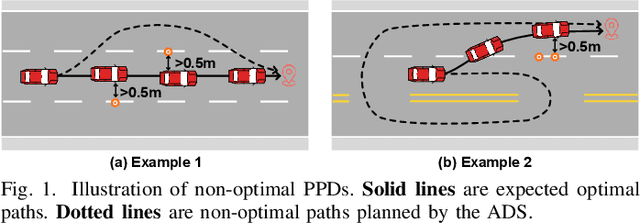
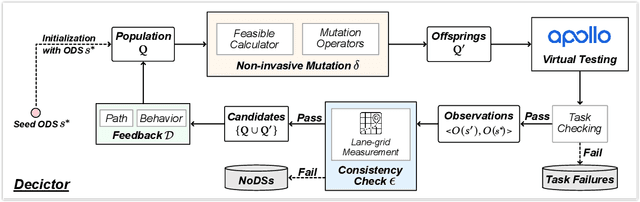
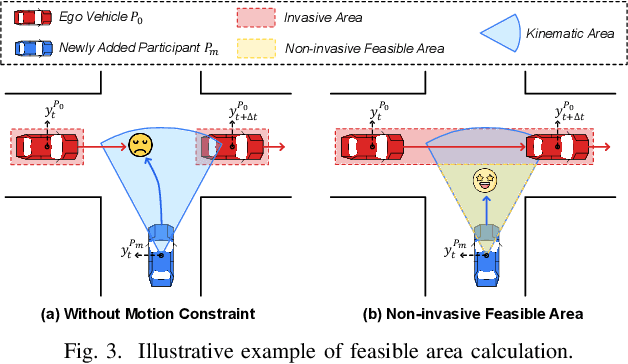
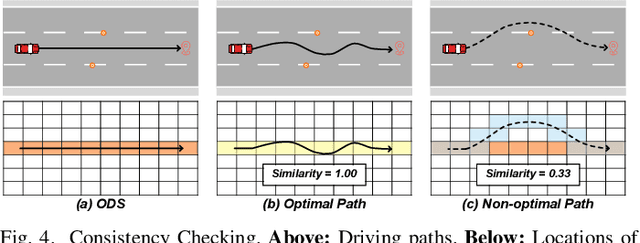
Autonomous Driving System (ADS) testing is crucial in ADS development, with the current primary focus being on safety. However, the evaluation of non-safety-critical performance, particularly the ADS's ability to make optimal decisions and produce optimal paths for autonomous vehicles (AVs), is equally vital to ensure the intelligence and reduce risks of AVs. Currently, there is little work dedicated to assessing ADSs' optimal decision-making performance due to the lack of corresponding oracles and the difficulty in generating scenarios with non-optimal decisions. In this paper, we focus on evaluating the decision-making quality of an ADS and propose the first method for detecting non-optimal decision scenarios (NoDSs), where the ADS does not compute optimal paths for AVs. Firstly, to deal with the oracle problem, we propose a novel metamorphic relation (MR) aimed at exposing violations of optimal decisions. The MR identifies the property that the ADS should retain optimal decisions when the optimal path remains unaffected by non-invasive changes. Subsequently, we develop a new framework, Decictor, designed to generate NoDSs efficiently. Decictor comprises three main components: Non-invasive Mutation, MR Check, and Feedback. The Non-invasive Mutation ensures that the original optimal path in the mutated scenarios is not affected, while the MR Check is responsible for determining whether non-optimal decisions are made. To enhance the effectiveness of identifying NoDSs, we design a feedback metric that combines both spatial and temporal aspects of the AV's movement. We evaluate Decictor on Baidu Apollo, an open-source and production-grade ADS. The experimental results validate the effectiveness of Decictor in detecting non-optimal decisions of ADSs. Our work provides valuable and original insights into evaluating the non-safety-critical performance of ADSs.
DataElixir: Purifying Poisoned Dataset to Mitigate Backdoor Attacks via Diffusion Models
Dec 20, 2023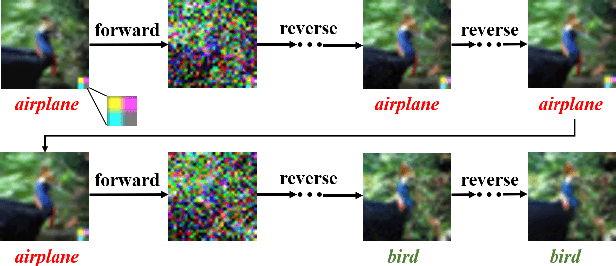
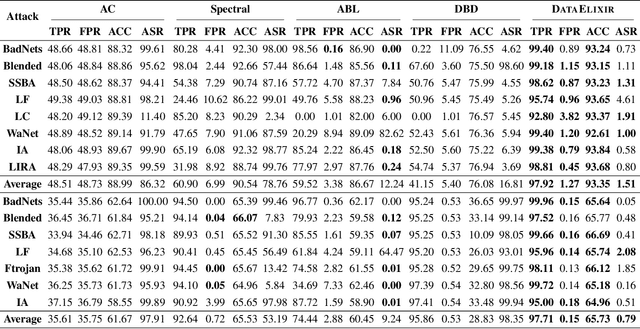

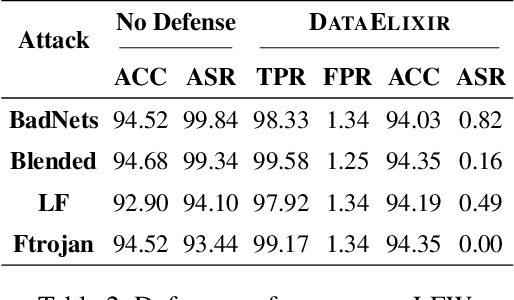
Dataset sanitization is a widely adopted proactive defense against poisoning-based backdoor attacks, aimed at filtering out and removing poisoned samples from training datasets. However, existing methods have shown limited efficacy in countering the ever-evolving trigger functions, and often leading to considerable degradation of benign accuracy. In this paper, we propose DataElixir, a novel sanitization approach tailored to purify poisoned datasets. We leverage diffusion models to eliminate trigger features and restore benign features, thereby turning the poisoned samples into benign ones. Specifically, with multiple iterations of the forward and reverse process, we extract intermediary images and their predicted labels for each sample in the original dataset. Then, we identify anomalous samples in terms of the presence of label transition of the intermediary images, detect the target label by quantifying distribution discrepancy, select their purified images considering pixel and feature distance, and determine their ground-truth labels by training a benign model. Experiments conducted on 9 popular attacks demonstrates that DataElixir effectively mitigates various complex attacks while exerting minimal impact on benign accuracy, surpassing the performance of baseline defense methods.
Good-looking but Lacking Faithfulness: Understanding Local Explanation Methods through Trend-based Testing
Sep 09, 2023While enjoying the great achievements brought by deep learning (DL), people are also worried about the decision made by DL models, since the high degree of non-linearity of DL models makes the decision extremely difficult to understand. Consequently, attacks such as adversarial attacks are easy to carry out, but difficult to detect and explain, which has led to a boom in the research on local explanation methods for explaining model decisions. In this paper, we evaluate the faithfulness of explanation methods and find that traditional tests on faithfulness encounter the random dominance problem, \ie, the random selection performs the best, especially for complex data. To further solve this problem, we propose three trend-based faithfulness tests and empirically demonstrate that the new trend tests can better assess faithfulness than traditional tests on image, natural language and security tasks. We implement the assessment system and evaluate ten popular explanation methods. Benefiting from the trend tests, we successfully assess the explanation methods on complex data for the first time, bringing unprecedented discoveries and inspiring future research. Downstream tasks also greatly benefit from the tests. For example, model debugging equipped with faithful explanation methods performs much better for detecting and correcting accuracy and security problems.
ConFL: Constraint-guided Fuzzing for Machine Learning Framework
Jul 11, 2023As machine learning gains prominence in various sectors of society for automated decision-making, concerns have risen regarding potential vulnerabilities in machine learning (ML) frameworks. Nevertheless, testing these frameworks is a daunting task due to their intricate implementation. Previous research on fuzzing ML frameworks has struggled to effectively extract input constraints and generate valid inputs, leading to extended fuzzing durations for deep execution or revealing the target crash. In this paper, we propose ConFL, a constraint-guided fuzzer for ML frameworks. ConFL automatically extracting constraints from kernel codes without the need for any prior knowledge. Guided by the constraints, ConFL is able to generate valid inputs that can pass the verification and explore deeper paths of kernel codes. In addition, we design a grouping technique to boost the fuzzing efficiency. To demonstrate the effectiveness of ConFL, we evaluated its performance mainly on Tensorflow. We find that ConFL is able to cover more code lines, and generate more valid inputs than state-of-the-art (SOTA) fuzzers. More importantly, ConFL found 84 previously unknown vulnerabilities in different versions of Tensorflow, all of which were assigned with new CVE ids, of which 3 were critical-severity and 13 were high-severity. We also extended ConFL to test PyTorch and Paddle, 7 vulnerabilities are found to date.
SSL-WM: A Black-Box Watermarking Approach for Encoders Pre-trained by Self-supervised Learning
Sep 08, 2022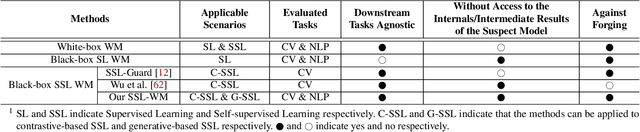
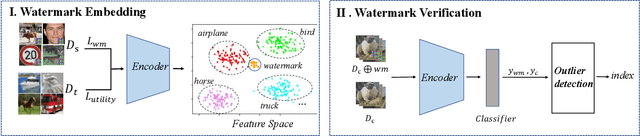

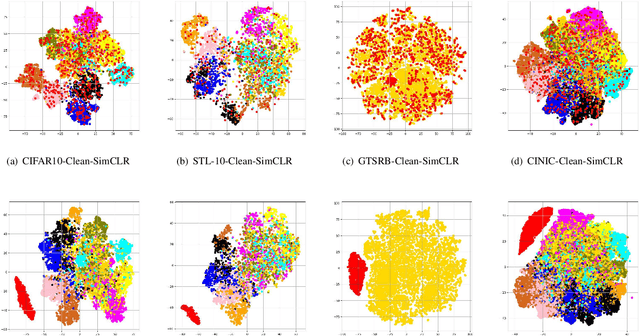
Recent years have witnessed significant success in Self-Supervised Learning (SSL), which facilitates various downstream tasks. However, attackers may steal such SSL models and commercialize them for profit, making it crucial to protect their Intellectual Property (IP). Most existing IP protection solutions are designed for supervised learning models and cannot be used directly since they require that the models' downstream tasks and target labels be known and available during watermark embedding, which is not always possible in the domain of SSL. To address such a problem especially when downstream tasks are diverse and unknown during watermark embedding, we propose a novel black-box watermarking solution, named SSL-WM, for protecting the ownership of SSL models. SSL-WM maps watermarked inputs by the watermarked encoders into an invariant representation space, which causes any downstream classifiers to produce expected behavior, thus allowing the detection of embedded watermarks. We evaluate SSL-WM on numerous tasks, such as Computer Vision (CV) and Natural Language Processing (NLP), using different SSL models, including contrastive-based and generative-based. Experimental results demonstrate that SSL-WM can effectively verify the ownership of stolen SSL models in various downstream tasks. Furthermore, SSL-WM is robust against model fine-tuning and pruning attacks. Lastly, SSL-WM can also evade detection from evaluated watermark detection approaches, demonstrating its promising application in protecting the IP of SSL models.
Learning Program Semantics with Code Representations: An Empirical Study
Mar 22, 2022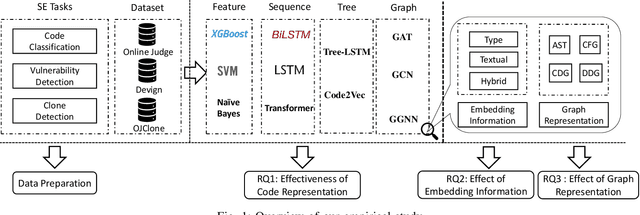
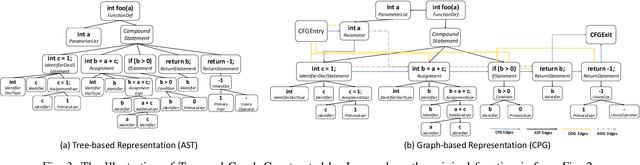

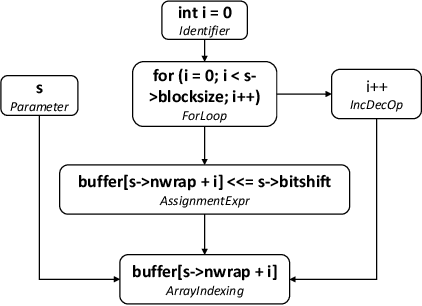
Program semantics learning is the core and fundamental for various code intelligent tasks e.g., vulnerability detection, clone detection. A considerable amount of existing works propose diverse approaches to learn the program semantics for different tasks and these works have achieved state-of-the-art performance. However, currently, a comprehensive and systematic study on evaluating different program representation techniques across diverse tasks is still missed. From this starting point, in this paper, we conduct an empirical study to evaluate different program representation techniques. Specifically, we categorize current mainstream code representation techniques into four categories i.e., Feature-based, Sequence-based, Tree-based, and Graph-based program representation technique and evaluate its performance on three diverse and popular code intelligent tasks i.e., {Code Classification}, Vulnerability Detection, and Clone Detection on the public released benchmark. We further design three {research questions (RQs)} and conduct a comprehensive analysis to investigate the performance. By the extensive experimental results, we conclude that (1) The graph-based representation is superior to the other selected techniques across these tasks. (2) Compared with the node type information used in tree-based and graph-based representations, the node textual information is more critical to learning the program semantics. (3) Different tasks require the task-specific semantics to achieve their highest performance, however combining various program semantics from different dimensions such as control dependency, data dependency can still produce promising results.