 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Defensive Framework Against Adversarial Attacks on Machine Learning-Based Network Intrusion Detection Systems
Feb 21, 2025As cyberattacks become increasingly sophisticated, advanced Network Intrusion Detection Systems (NIDS) are critical for modern network security. Traditional signature-based NIDS are inadequate against zero-day and evolving attacks. In response, machine learning (ML)-based NIDS have emerged as promising solutions; however, they are vulnerable to adversarial evasion attacks that subtly manipulate network traffic to bypass detection. To address this vulnerability, we propose a novel defensive framework that enhances the robustness of ML-based NIDS by simultaneously integrating adversarial training, dataset balancing techniques, advanced feature engineering, ensemble learning, and extensive model fine-tuning. We validate our framework using the NSL-KDD and UNSW-NB15 datasets. Experimental results show, on average, a 35% increase in detection accuracy and a 12.5% reduction in false positives compared to baseline models, particularly under adversarial conditions. The proposed defense against adversarial attacks significantly advances the practical deployment of robust ML-based NIDS in real-world networks.
LoRAGuard: An Effective Black-box Watermarking Approach for LoRAs
Jan 26, 2025LoRA (Low-Rank Adaptation) has achieved remarkable success in the parameter-efficient fine-tuning of large models. The trained LoRA matrix can be integrated with the base model through addition or negation operation to improve performance on downstream tasks. However, the unauthorized use of LoRAs to generate harmful content highlights the need for effective mechanisms to trace their usage. A natural solution is to embed watermarks into LoRAs to detect unauthorized misuse. However, existing methods struggle when multiple LoRAs are combined or negation operation is applied, as these can significantly degrade watermark performance. In this paper, we introduce LoRAGuard, a novel black-box watermarking technique for detecting unauthorized misuse of LoRAs. To support both addition and negation operations, we propose the Yin-Yang watermark technique, where the Yin watermark is verified during negation operation and the Yang watermark during addition operation. Additionally, we propose a shadow-model-based watermark training approach that significantly improves effectiveness in scenarios involving multiple integrated LoRAs. Extensive experiments on both language and diffusion models show that LoRAGuard achieves nearly 100% watermark verification success and demonstrates strong effectiveness.
RAG-WM: An Efficient Black-Box Watermarking Approach for Retrieval-Augmented Generation of Large Language Models
Jan 09, 2025



In recent years, tremendous success has been witnessed in Retrieval-Augmented Generation (RAG), widely used to enhance Large Language Models (LLMs) in domain-specific, knowledge-intensive, and privacy-sensitive tasks. However, attackers may steal those valuable RAGs and deploy or commercialize them, making it essential to detect Intellectual Property (IP) infringement. Most existing ownership protection solutions, such as watermarks, are designed for relational databases and texts. They cannot be directly applied to RAGs because relational database watermarks require white-box access to detect IP infringement, which is unrealistic for the knowledge base in RAGs. Meanwhile, post-processing by the adversary's deployed LLMs typically destructs text watermark information. To address those problems, we propose a novel black-box "knowledge watermark" approach, named RAG-WM, to detect IP infringement of RAGs. RAG-WM uses a multi-LLM interaction framework, comprising a Watermark Generator, Shadow LLM & RAG, and Watermark Discriminator, to create watermark texts based on watermark entity-relationship tuples and inject them into the target RAG. We evaluate RAG-WM across three domain-specific and two privacy-sensitive tasks on four benchmark LLMs. Experimental results show that RAG-WM effectively detects the stolen RAGs in various deployed LLMs. Furthermore, RAG-WM is robust against paraphrasing, unrelated content removal, knowledge insertion, and knowledge expansion attacks. Lastly, RAG-WM can also evade watermark detection approaches, highlighting its promising application in detecting IP infringement of RAG systems.
MEA-Defender: A Robust Watermark against Model Extraction Attack
Jan 26, 2024Recently, numerous highly-valuable Deep Neural Networks (DNNs) have been trained using deep learning algorithms. To protect the Intellectual Property (IP) of the original owners over such DNN models, backdoor-based watermarks have been extensively studied. However, most of such watermarks fail upon model extraction attack, which utilizes input samples to query the target model and obtains the corresponding outputs, thus training a substitute model using such input-output pairs. In this paper, we propose a novel watermark to protect IP of DNN models against model extraction, named MEA-Defender. In particular, we obtain the watermark by combining two samples from two source classes in the input domain and design a watermark loss function that makes the output domain of the watermark within that of the main task samples. Since both the input domain and the output domain of our watermark are indispensable parts of those of the main task samples, the watermark will be extracted into the stolen model along with the main task during model extraction. We conduct extensive experiments on four model extraction attacks, using five datasets and six models trained based on supervised learning and self-supervised learning algorithms. The experimental results demonstrate that MEA-Defender is highly robust against different model extraction attacks, and various watermark removal/detection approaches.
SSL-WM: A Black-Box Watermarking Approach for Encoders Pre-trained by Self-supervised Learning
Sep 08, 2022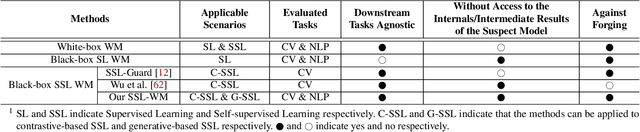
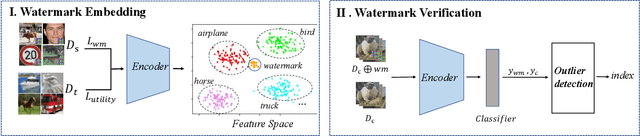

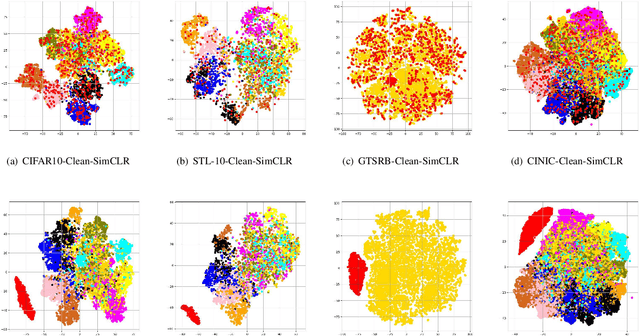
Recent years have witnessed significant success in Self-Supervised Learning (SSL), which facilitates various downstream tasks. However, attackers may steal such SSL models and commercialize them for profit, making it crucial to protect their Intellectual Property (IP). Most existing IP protection solutions are designed for supervised learning models and cannot be used directly since they require that the models' downstream tasks and target labels be known and available during watermark embedding, which is not always possible in the domain of SSL. To address such a problem especially when downstream tasks are diverse and unknown during watermark embedding, we propose a novel black-box watermarking solution, named SSL-WM, for protecting the ownership of SSL models. SSL-WM maps watermarked inputs by the watermarked encoders into an invariant representation space, which causes any downstream classifiers to produce expected behavior, thus allowing the detection of embedded watermarks. We evaluate SSL-WM on numerous tasks, such as Computer Vision (CV) and Natural Language Processing (NLP), using different SSL models, including contrastive-based and generative-based. Experimental results demonstrate that SSL-WM can effectively verify the ownership of stolen SSL models in various downstream tasks. Furthermore, SSL-WM is robust against model fine-tuning and pruning attacks. Lastly, SSL-WM can also evade detection from evaluated watermark detection approaches, demonstrating its promising application in protecting the IP of SSL models.
DBIA: Data-free Backdoor Injection Attack against Transformer Networks
Nov 22, 2021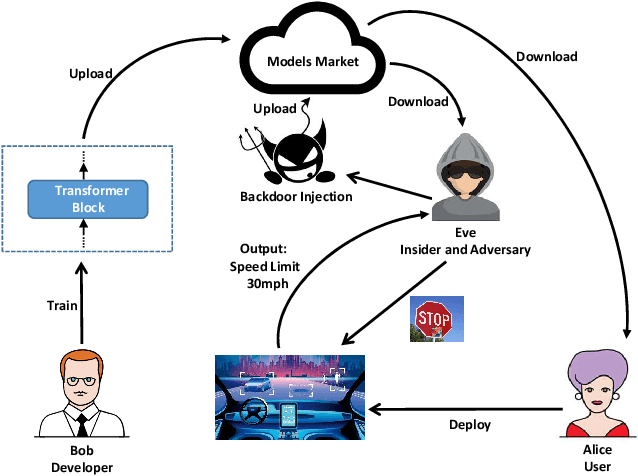

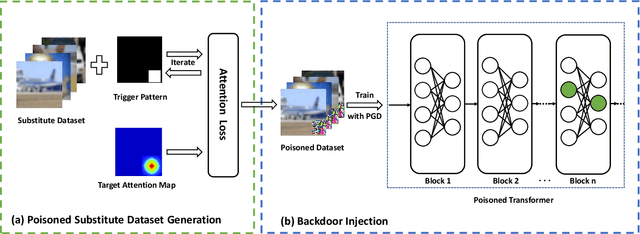
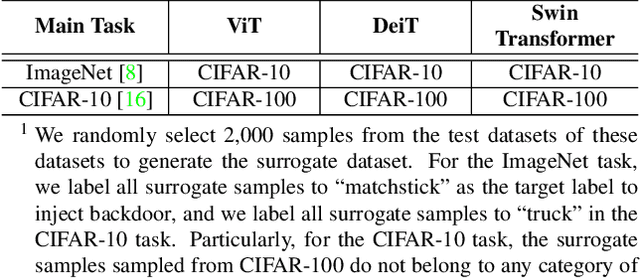
Recently, transformer architecture has demonstrated its significance in both Natural Language Processing (NLP) and Computer Vision (CV) tasks. Though other network models are known to be vulnerable to the backdoor attack, which embeds triggers in the model and controls the model behavior when the triggers are presented, little is known whether such an attack is still valid on the transformer models and if so, whether it can be done in a more cost-efficient manner. In this paper, we propose DBIA, a novel data-free backdoor attack against the CV-oriented transformer networks, leveraging the inherent attention mechanism of transformers to generate triggers and injecting the backdoor using the poisoned surrogate dataset. We conducted extensive experiments based on three benchmark transformers, i.e., ViT, DeiT and Swin Transformer, on two mainstream image classification tasks, i.e., CIFAR10 and ImageNet. The evaluation results demonstrate that, consuming fewer resources, our approach can embed backdoors with a high success rate and a low impact on the performance of the victim transformers. Our code is available at https://anonymous.4open.science/r/DBIA-825D.
HufuNet: Embedding the Left Piece as Watermark and Keeping the Right Piece for Ownership Verification in Deep Neural Networks
Mar 25, 2021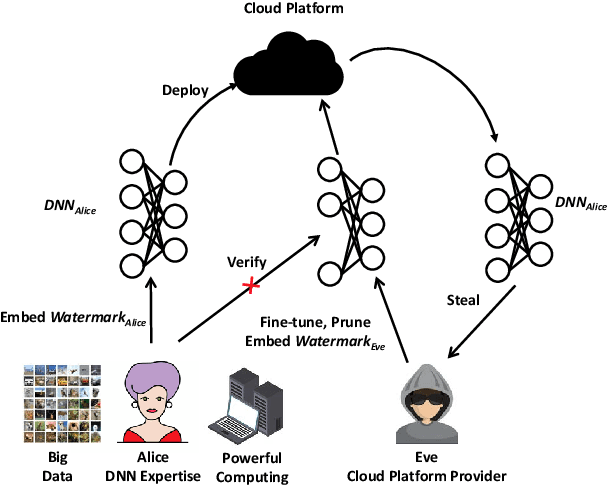
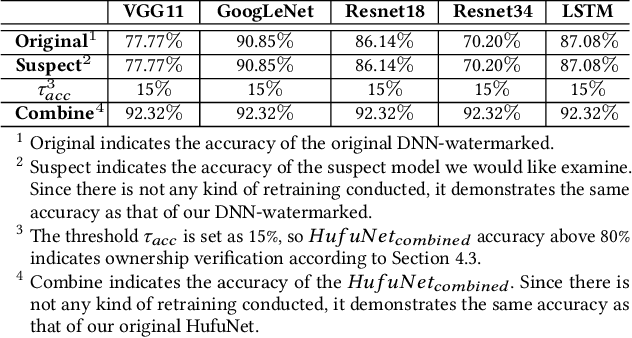
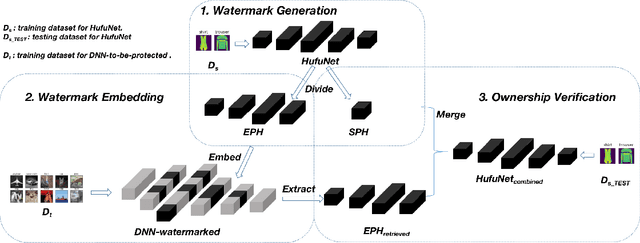
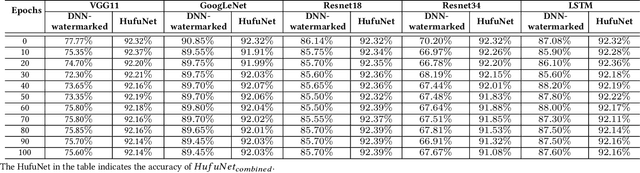
Due to the wide use of highly-valuable and large-scale deep neural networks (DNNs), it becomes crucial to protect the intellectual property of DNNs so that the ownership of disputed or stolen DNNs can be verified. Most existing solutions embed backdoors in DNN model training such that DNN ownership can be verified by triggering distinguishable model behaviors with a set of secret inputs. However, such solutions are vulnerable to model fine-tuning and pruning. They also suffer from fraudulent ownership claim as attackers can discover adversarial samples and use them as secret inputs to trigger distinguishable behaviors from stolen models. To address these problems, we propose a novel DNN watermarking solution, named HufuNet, for protecting the ownership of DNN models. We evaluate HufuNet rigorously on four benchmark datasets with five popular DNN models, including convolutional neural network (CNN) and recurrent neural network (RNN). The experiments demonstrate HufuNet is highly robust against model fine-tuning/pruning, kernels cutoff/supplement, functionality-equivalent attack, and fraudulent ownership claims, thus highly promising to protect large-scale DNN models in the real-world.
SoK: A Modularized Approach to Study the Security of Automatic Speech Recognition Systems
Mar 19, 2021
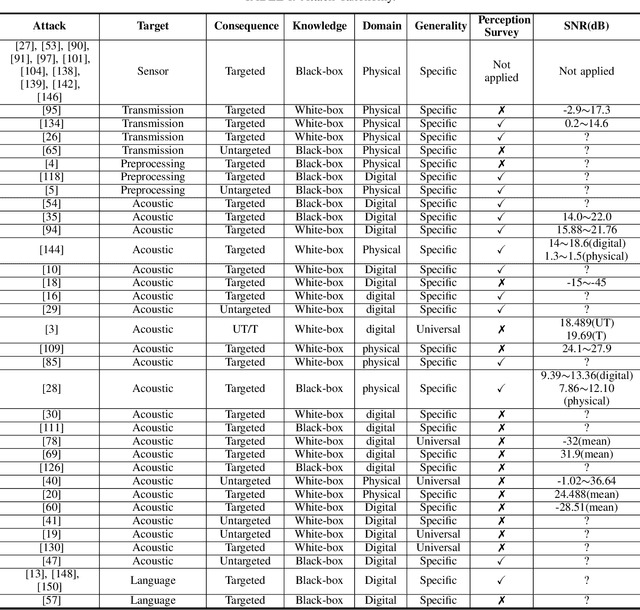

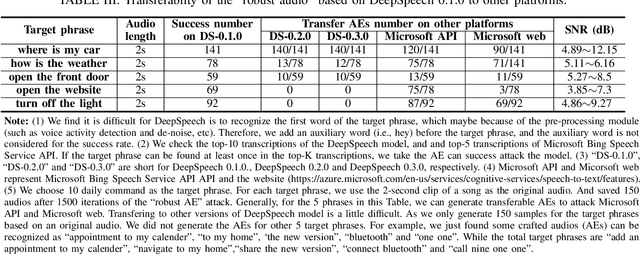
With the wide use of Automatic Speech Recognition (ASR) in applications such as human machine interaction, simultaneous interpretation, audio transcription, etc., its security protection becomes increasingly important. Although recent studies have brought to light the weaknesses of popular ASR systems that enable out-of-band signal attack, adversarial attack, etc., and further proposed various remedies (signal smoothing, adversarial training, etc.), a systematic understanding of ASR security (both attacks and defenses) is still missing, especially on how realistic such threats are and how general existing protection could be. In this paper, we present our systematization of knowledge for ASR security and provide a comprehensive taxonomy for existing work based on a modularized workflow. More importantly, we align the research in this domain with that on security in Image Recognition System (IRS), which has been extensively studied, using the domain knowledge in the latter to help understand where we stand in the former. Generally, both IRS and ASR are perceptual systems. Their similarities allow us to systematically study existing literature in ASR security based on the spectrum of attacks and defense solutions proposed for IRS, and pinpoint the directions of more advanced attacks and the directions potentially leading to more effective protection in ASR. In contrast, their differences, especially the complexity of ASR compared with IRS, help us learn unique challenges and opportunities in ASR security. Particularly, our experimental study shows that transfer learning across ASR models is feasible, even in the absence of knowledge about models (even their types) and training data.
Practical Adversarial Attack Against Object Detector
Dec 26, 2018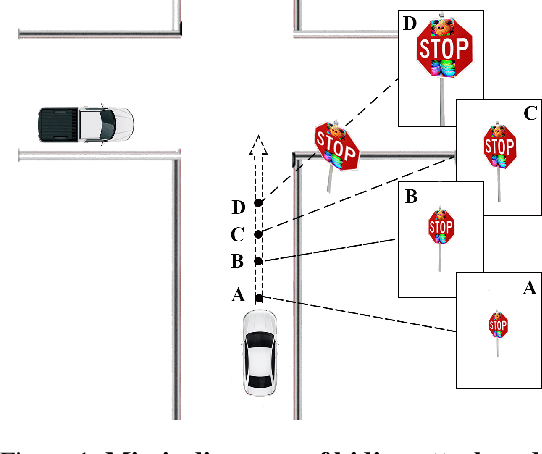

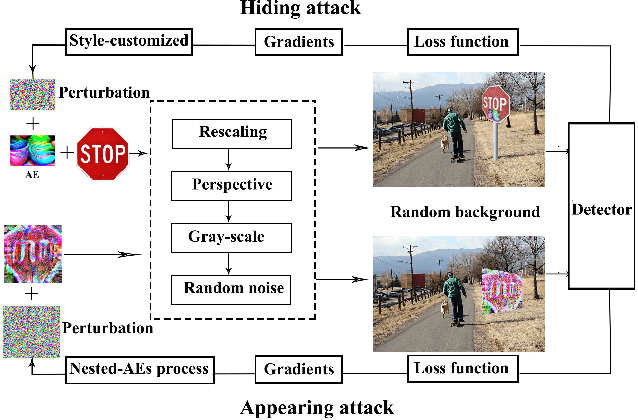

In this paper, we proposed the first practical adversarial attacks against object detectors in realistic situations: the adversarial examples are placed in different angles and distances, especially in the long distance (over 20m) and wide angles 120 degree. To improve the robustness of adversarial examples, we proposed the nested adversarial examples and introduced the image transformation techniques. Transformation methods aim to simulate the variance factors such as distances, angles, illuminations, etc., in the physical world. Two kinds of attacks were implemented on YOLO V3, a state-of-the-art real-time object detector: hiding attack that fools the detector unable to recognize the object, and appearing attack that fools the detector to recognize the non-existent object. The adversarial examples are evaluated in three environments: indoor lab, outdoor environment, and the real road, and demonstrated to achieve the success rate up to 92.4% based on the distance range from 1m to 25m. In particular, the real road testing of hiding attack on a straight road and a crossing road produced the success rate of 75% and 64% respectively, and the appearing attack obtained the success rates of 63% and 81% respectively, which we believe, should catch the attention of the autonomous driving community.
CommanderSong: A Systematic Approach for Practical Adversarial Voice Recognition
Jul 02, 2018

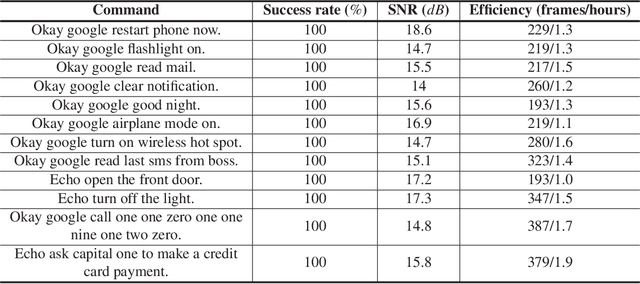
The popularity of ASR (automatic speech recognition) systems, like Google Voice, Cortana, brings in security concerns, as demonstrated by recent attacks. The impacts of such threats, however, are less clear, since they are either less stealthy (producing noise-like voice commands) or requiring the physical presence of an attack device (using ultrasound). In this paper, we demonstrate that not only are more practical and surreptitious attacks feasible but they can even be automatically constructed. Specifically, we find that the voice commands can be stealthily embedded into songs, which, when played, can effectively control the target system through ASR without being noticed. For this purpose, we developed novel techniques that address a key technical challenge: integrating the commands into a song in a way that can be effectively recognized by ASR through the air, in the presence of background noise, while not being detected by a human listener. Our research shows that this can be done automatically against real world ASR applications. We also demonstrate that such CommanderSongs can be spread through Internet (e.g., YouTube) and radio, potentially affecting millions of ASR users. We further present a new mitigation technique that controls this threat.