 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoK: Privacy-Preserving Data Synthesis
Jul 05, 2023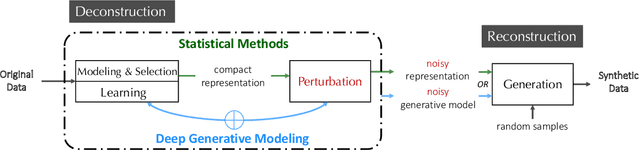
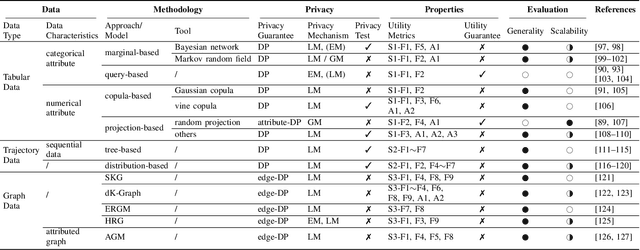
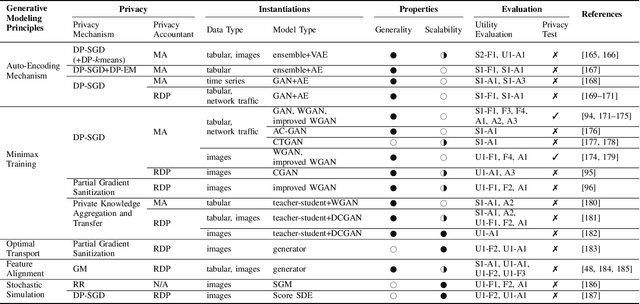
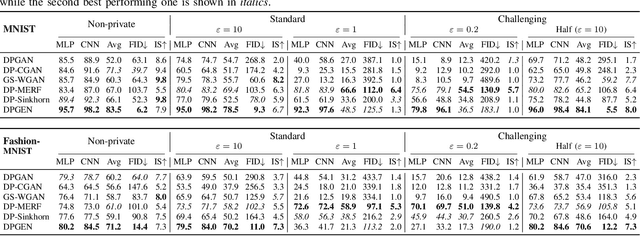
As the prevalence of data analysis grows, safeguarding data privacy has become a paramount concern. Consequently, there has been an upsurge in the development of mechanisms aimed at privacy-preserving data analyses. However, these approaches are task-specific; designing algorithms for new tasks is a cumbersome process. As an alternative, one can create synthetic data that is (ideally) devoid of private information. This paper focuses on privacy-preserving data synthesis (PPDS) by providing a comprehensive overview, analysis, and discussion of the field. Specifically, we put forth a master recipe that unifies two prominent strands of research in PPDS: statistical methods and deep learning (DL)-based methods. Under the master recipe, we further dissect the statistical methods into choices of modeling and representation, and investigate the DL-based methods by different generative modeling principles. To consolidate our findings, we provide comprehensive reference tables, distill key takeaways, and identify open problems in the existing literature. In doing so, we aim to answer the following questions: What are the design principles behind different PPDS methods? How can we categorize these methods, and what are the advantages and disadvantages associated with each category? Can we provide guidelines for method selection in different real-world scenarios? We proceed to benchmark several prominent DL-based methods on the task of private image synthesis and conclude that DP-MERF is an all-purpose approach. Finally, upon systematizing the work over the past decade, we identify future directions and call for actions from researchers.
Uncovering the Connection Between Differential Privacy and Certified Robustness of Federated Learning against Poisoning Attacks
Sep 08, 2022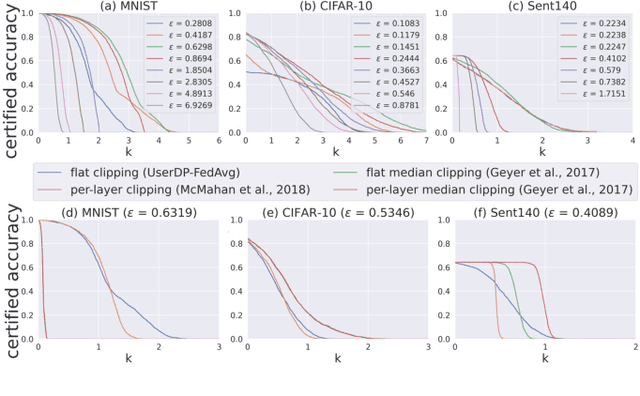


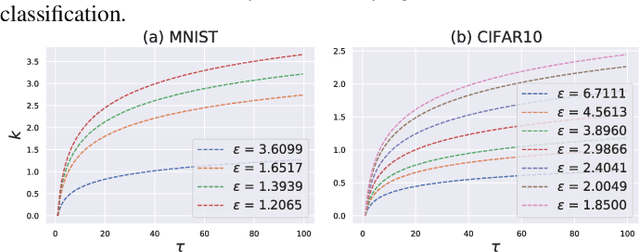
Federated learning (FL) provides an efficient paradigm to jointly train a global model leveraging data from distributed users. As the local training data come from different users who may not be trustworthy, several studies have shown that FL is vulnerable to poisoning attacks. Meanwhile, to protect the privacy of local users, FL is always trained in a differentially private way (DPFL). Thus, in this paper, we ask: Can we leverage the innate privacy property of DPFL to provide certified robustness against poisoning attacks? Can we further improve the privacy of FL to improve such certification? We first investigate both user-level and instance-level privacy of FL and propose novel mechanisms to achieve improved instance-level privacy. We then provide two robustness certification criteria: certified prediction and certified attack cost for DPFL on both levels. Theoretically, we prove the certified robustness of DPFL under a bounded number of adversarial users or instances. Empirically, we conduct extensive experiments to verify our theories under a range of attacks on different datasets. We show that DPFL with a tighter privacy guarantee always provides stronger robustness certification in terms of certified attack cost, but the optimal certified prediction is achieved under a proper balance between privacy protection and utility loss.
Privacy of Autonomous Vehicles: Risks, Protection Methods, and Future Directions
Sep 08, 2022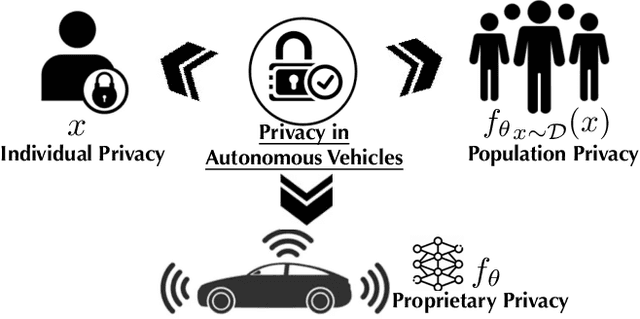
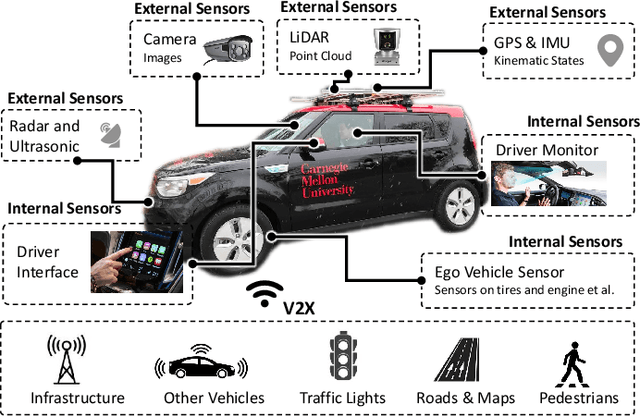
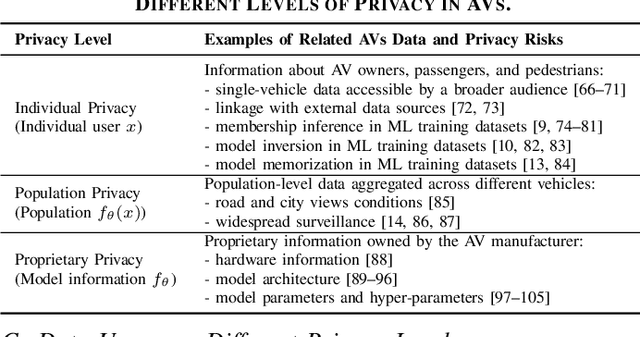
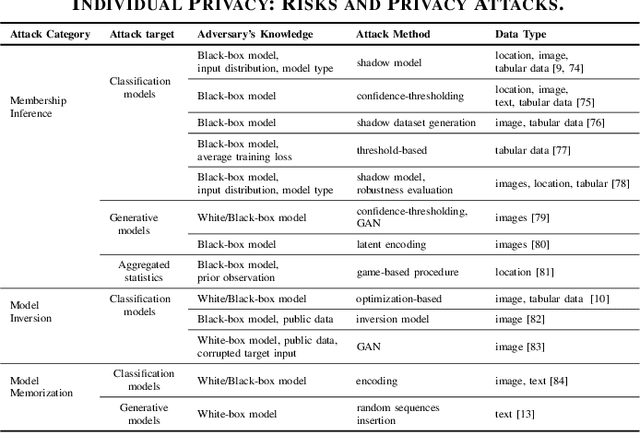
Recent advances in machine learning have enabled its wide application in different domains, and one of the most exciting applications is autonomous vehicles (AVs), which have encouraged the development of a number of ML algorithms from perception to prediction to planning. However, training AVs usually requires a large amount of training data collected from different driving environments (e.g., cities) as well as different types of personal information (e.g., working hours and routes). Such collected large data, treated as the new oil for ML in the data-centric AI era, usually contains a large amount of privacy-sensitive information which is hard to remove or even audit. Although existing privacy protection approaches have achieved certain theoretical and empirical success, there is still a gap when applying them to real-world applications such as autonomous vehicles. For instance, when training AVs, not only can individually identifiable information reveal privacy-sensitive information, but also population-level information such as road construction within a city, and proprietary-level commercial secrets of AVs. Thus, it is critical to revisit the frontier of privacy risks and corresponding protection approaches in AVs to bridge this gap. Following this goal, in this work, we provide a new taxonomy for privacy risks and protection methods in AVs, and we categorize privacy in AVs into three levels: individual, population, and proprietary. We explicitly list out recent challenges to protect each of these levels of privacy, summarize existing solutions to these challenges, discuss the lessons and conclusions, and provide potential future directions and opportunities for both researchers and practitioners. We believe this work will help to shape the privacy research in AV and guide the privacy protection technology design.
SecretGen: Privacy Recovery on Pre-Trained Models via Distribution Discrimination
Jul 25, 2022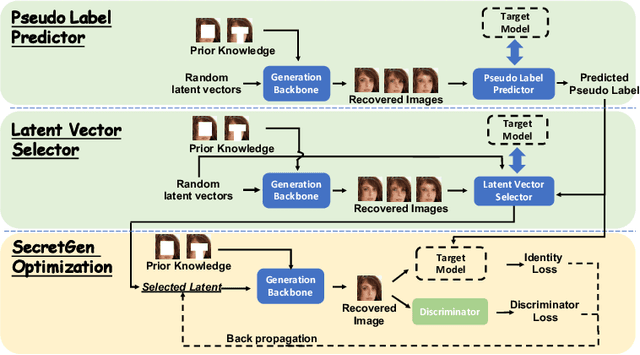

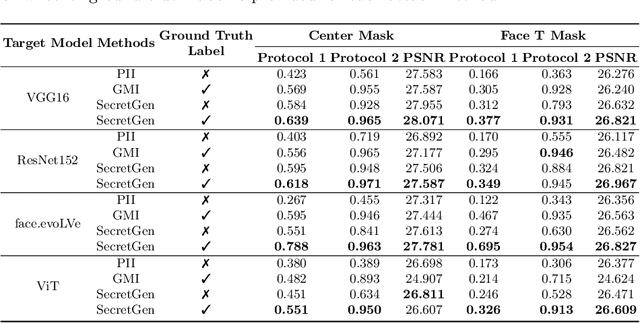
Transfer learning through the use of pre-trained models has become a growing trend for the machine learning community. Consequently, numerous pre-trained models are released online to facilitate further research. However, it raises extensive concerns on whether these pre-trained models would leak privacy-sensitive information of their training data. Thus, in this work, we aim to answer the following questions: "Can we effectively recover private information from these pre-trained models? What are the sufficient conditions to retrieve such sensitive information?" We first explore different statistical information which can discriminate the private training distribution from other distributions. Based on our observations, we propose a novel private data reconstruction framework, SecretGen, to effectively recover private information. Compared with previous methods which can recover private data with the ground true prediction of the targeted recovery instance, SecretGen does not require such prior knowledge, making it more practical. We conduct extensive experiments on different datasets under diverse scenarios to compare SecretGen with other baselines and provide a systematic benchmark to better understand the impact of different auxiliary information and optimization operations. We show that without prior knowledge about true class prediction, SecretGen is able to recover private data with similar performance compared with the ones that leverage such prior knowledge. If the prior knowledge is given, SecretGen will significantly outperform baseline methods. We also propose several quantitative metrics to further quantify the privacy vulnerability of pre-trained models, which will help the model selection for privacy-sensitive applications. Our code is available at: https://github.com/AI-secure/SecretGen.
LinkTeller: Recovering Private Edges from Graph Neural Networks via Influence Analysis
Aug 20, 2021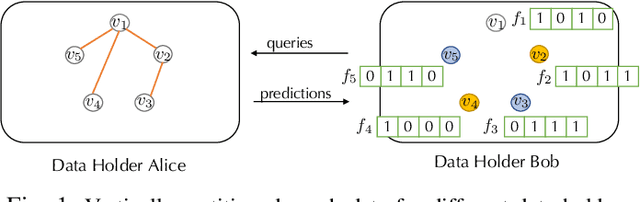
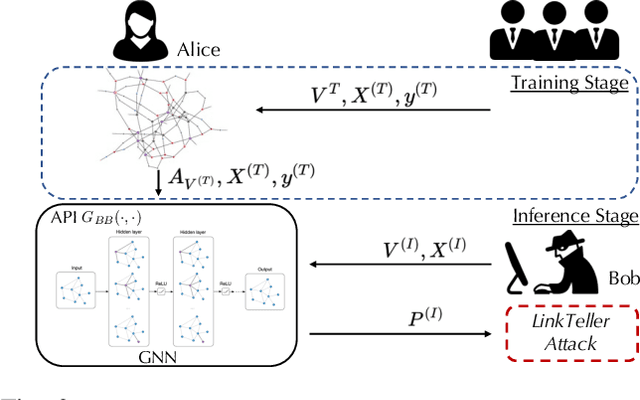
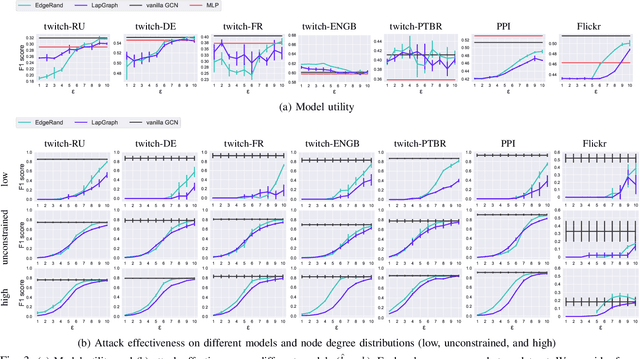
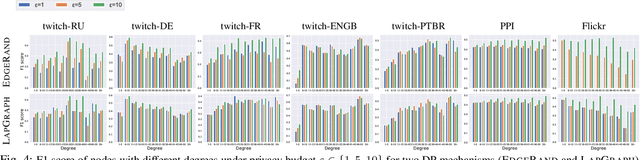
Graph structured data have enabled several successful applications such as recommendation systems and traffic prediction, given the rich node features and edges information. However, these high-dimensional features and high-order adjacency information are usually heterogeneous and held by different data holders in practice. Given such vertical data partition (e.g., one data holder will only own either the node features or edge information), different data holders have to develop efficient joint training protocols rather than directly transfer data to each other due to privacy concerns. In this paper, we focus on the edge privacy, and consider a training scenario where Bob with node features will first send training node features to Alice who owns the adjacency information. Alice will then train a graph neural network (GNN) with the joint information and release an inference API. During inference, Bob is able to provide test node features and query the API to obtain the predictions for test nodes. Under this setting, we first propose a privacy attack LinkTeller via influence analysis to infer the private edge information held by Alice via designing adversarial queries for Bob. We then empirically show that LinkTeller is able to recover a significant amount of private edges, outperforming existing baselines. To further evaluate the privacy leakage, we adapt an existing algorithm for differentially private graph convolutional network (DP GCN) training and propose a new DP GCN mechanism LapGraph. We show that these DP GCN mechanisms are not always resilient against LinkTeller empirically under mild privacy guarantees ($\varepsilon>5$). Our studies will shed light on future research towards designing more resilient privacy-preserving GCN models; in the meantime, provide an in-depth understanding of the tradeoff between GCN model utility and robustness against potential privacy attacks.
DataLens: Scalable Privacy Preserving Training via Gradient Compression and Aggregation
Mar 20, 2021

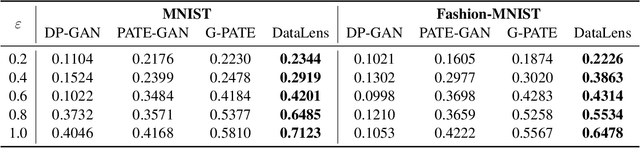
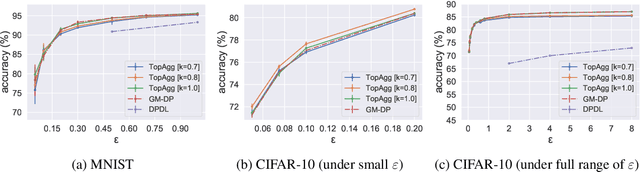
Recent success of deep neural networks (DNNs) hinges on the availability of large-scale dataset; however, training on such dataset often poses privacy risks for sensitive training information. In this paper, we aim to explore the power of generative models and gradient sparsity, and propose a scalable privacy-preserving generative model DATALENS. Comparing with the standard PATE privacy-preserving framework which allows teachers to vote on one-dimensional predictions, voting on the high dimensional gradient vectors is challenging in terms of privacy preservation. As dimension reduction techniques are required, we need to navigate a delicate tradeoff space between (1) the improvement of privacy preservation and (2) the slowdown of SGD convergence. To tackle this, we take advantage of communication efficient learning and propose a novel noise compression and aggregation approach TOPAGG by combining top-k compression for dimension reduction with a corresponding noise injection mechanism. We theoretically prove that the DATALENS framework guarantees differential privacy for its generated data, and provide analysis on its convergence. To demonstrate the practical usage of DATALENS, we conduct extensive experiments on diverse datasets including MNIST, Fashion-MNIST, and high dimensional CelebA, and we show that, DATALENS significantly outperforms other baseline DP generative models. In addition, we adapt the proposed TOPAGG approach, which is one of the key building blocks in DATALENS, to DP SGD training, and show that it is able to achieve higher utility than the state-of-the-art DP SGD approach in most cases.
Scalable Differentially Private Generative Student Model via PATE
Jun 21, 2019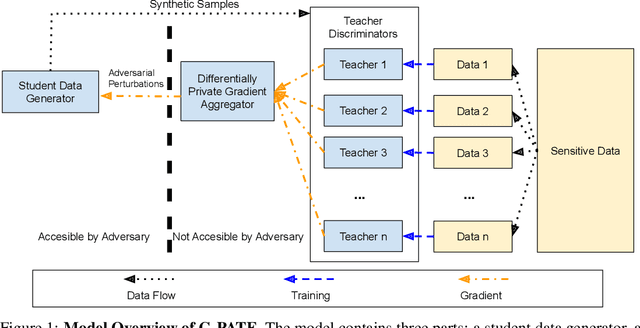
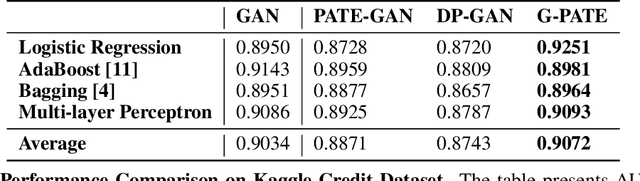
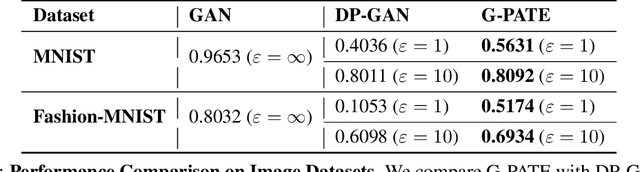

Recent rapid development of machine learning is largely due to algorithmic breakthroughs, computation resource development, and especially the access to a large amount of training data. However, though data sharing has the great potential of improving machine learning models and enabling new applications, there have been increasing concerns about the privacy implications of data collection. In this work, we present a novel approach for training differentially private data generator G-PATE. The generator can be used to produce synthetic datasets with strong privacy guarantee while preserving high data utility. Our approach leverages generative adversarial nets (GAN) to generate data and protect data privacy based on the Private Aggregation of Teacher Ensembles (PATE) framework. Our approach improves the use of privacy budget by only ensuring differential privacy for the generator, which is the part of the model that actually needs to be published for private data generation. To achieve this, we connect a student generator with an ensemble of teacher discriminators. We also propose a private gradient aggregation mechanism to ensure differential privacy on all the information that flows from the teacher discriminators to the student generator. We empirically show that the G-PATE significantly outperforms prior work on both image and non-image datasets.
CommanderSong: A Systematic Approach for Practical Adversarial Voice Recognition
Jul 02, 2018

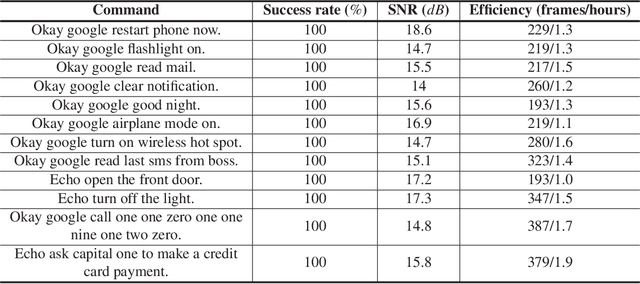
The popularity of ASR (automatic speech recognition) systems, like Google Voice, Cortana, brings in security concerns, as demonstrated by recent attacks. The impacts of such threats, however, are less clear, since they are either less stealthy (producing noise-like voice commands) or requiring the physical presence of an attack device (using ultrasound). In this paper, we demonstrate that not only are more practical and surreptitious attacks feasible but they can even be automatically constructed. Specifically, we find that the voice commands can be stealthily embedded into songs, which, when played, can effectively control the target system through ASR without being noticed. For this purpose, we developed novel techniques that address a key technical challenge: integrating the commands into a song in a way that can be effectively recognized by ASR through the air, in the presence of background noise, while not being detected by a human listener. Our research shows that this can be done automatically against real world ASR applications. We also demonstrate that such CommanderSongs can be spread through Internet (e.g., YouTube) and radio, potentially affecting millions of ASR users. We further present a new mitigation technique that controls this threat.
Understanding Membership Inferences on Well-Generalized Learning Models
Feb 13, 2018
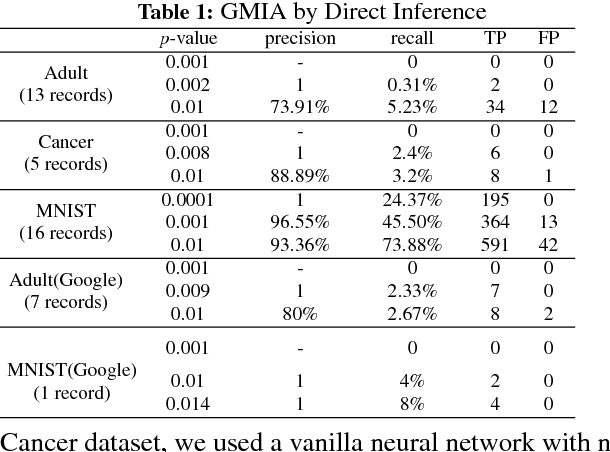
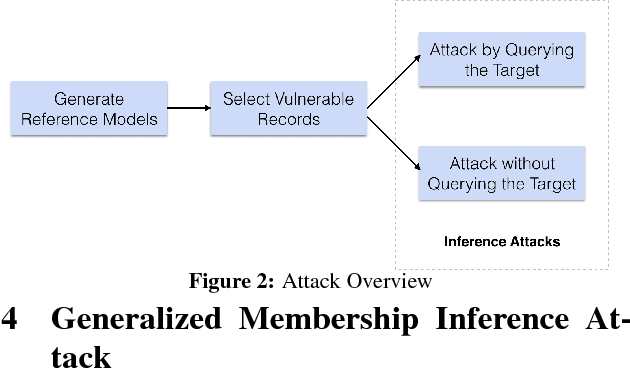
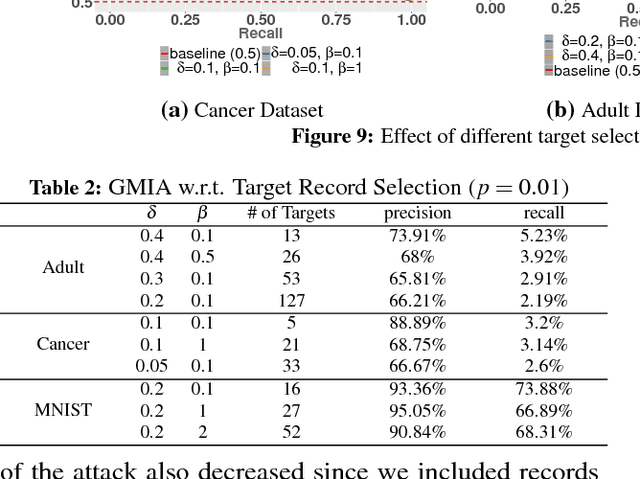
Membership Inference Attack (MIA) determines the presence of a record in a machine learning model's training data by querying the model. Prior work has shown that the attack is feasible when the model is overfitted to its training data or when the adversary controls the training algorithm. However, when the model is not overfitted and the adversary does not control the training algorithm, the threat is not well understood. In this paper, we report a study that discovers overfitting to be a sufficient but not a necessary condition for an MIA to succeed. More specifically, we demonstrate that even a well-generalized model contains vulnerable instances subject to a new generalized MIA (GMIA). In GMIA, we use novel techniques for selecting vulnerable instances and detecting their subtle influences ignored by overfitting metrics. Specifically, we successfully identify individual records with high precision in real-world datasets by querying black-box machine learning models. Further we show that a vulnerable record can even be indirectly attacked by querying other related records and existing generalization techniques are found to be less effective in protecting the vulnerable instances. Our findings sharpen the understanding of the fundamental cause of the problem: the unique influences the training instance may have on the model.