 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tuning Language Models over Slow Networks using Activation Compression with Guarantees
Jun 02, 2022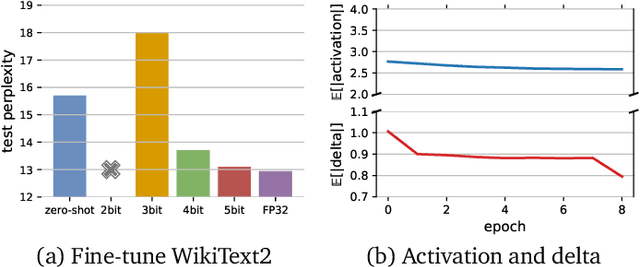

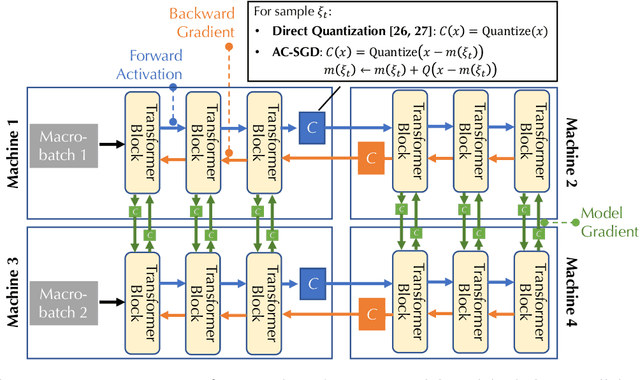

Communication compression is a crucial technique for modern distributed learning systems to alleviate their communication bottlenecks over slower networks. Despite recent intensive studies of gradient compression for data parallel-style training, compressing the activations for models trained with pipeline parallelism is still an open problem. In this paper, we propose AC-SGD, a novel activation compression algorithm for communication-efficient pipeline parallelism training over slow networks. Different from previous efforts in activation compression, instead of compressing activation values directly, AC-SGD compresses the changes of the activations. This allows us to show, to the best of our knowledge for the first time, that one can still achieve $O(1/\sqrt{T})$ convergence rate for non-convex objectives under activation compression, without making assumptions on gradient unbiasedness that do not hold for deep learning models with non-linear activation functions.We then show that AC-SGD can be optimized and implemented efficiently, without additional end-to-end runtime overhead.We evaluated AC-SGD to fine-tune language models with up to 1.5 billion parameters, compressing activations to 2-4 bits.AC-SGD provides up to 4.3X end-to-end speed-up in slower networks, without sacrificing model quality. Moreover, we also show that AC-SGD can be combined with state-of-the-art gradient compression algorithms to enable "end-to-end communication compression: All communications between machines, including model gradients, forward activations, and backward gradients are compressed into lower precision.This provides up to 4.9X end-to-end speed-up, without sacrificing model quality.
SHiFT: An Efficient, Flexible Search Engine for Transfer Learning
Apr 04, 2022
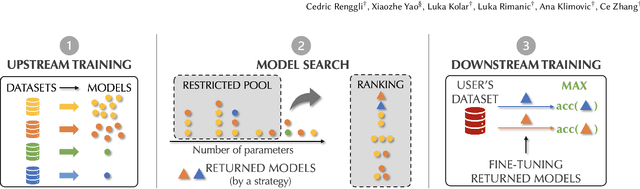
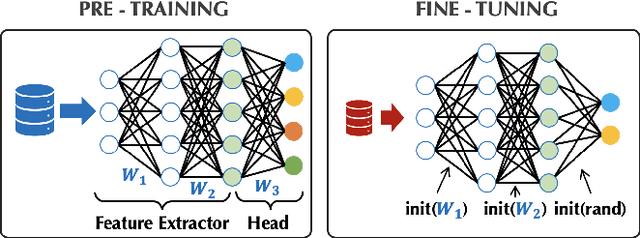
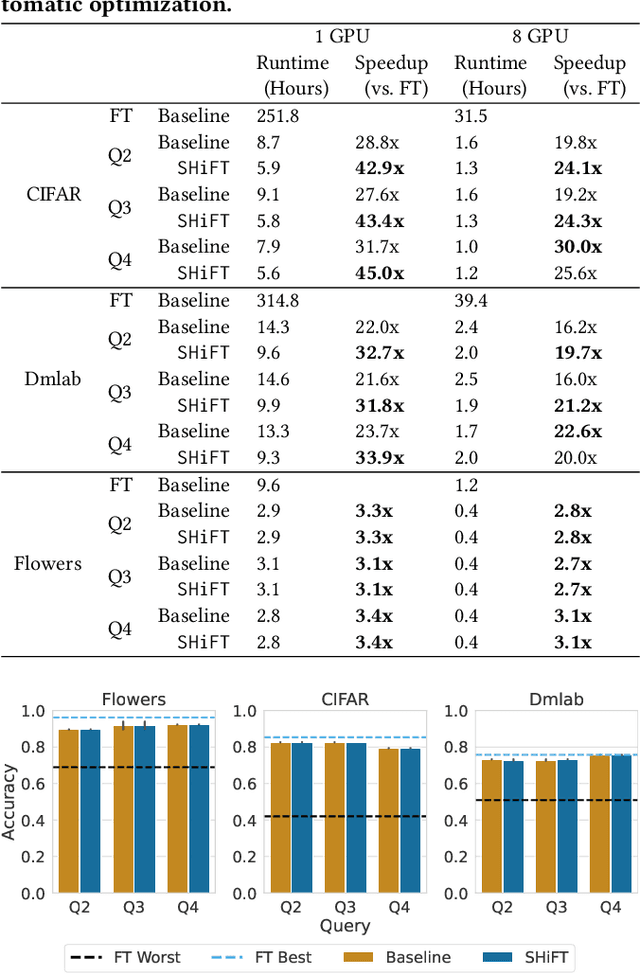
Transfer learning can be seen as a data- and compute-efficient alternative to training models from scratch. The emergence of rich model repositories, such as TensorFlow Hub, enables practitioners and researchers to unleash the potential of these models across a wide range of downstream tasks. As these repositories keep growing exponentially, efficiently selecting a good model for the task at hand becomes paramount. By carefully comparing various selection and search strategies, we realize that no single method outperforms the others, and hybrid or mixed strategies can be beneficial. Therefore, we propose SHiFT, the first downstream task-aware, flexible, and efficient model search engine for transfer learning. These properties are enabled by a custom query language SHiFT-QL together with a cost-based decision maker, which we empirically validate. Motivated by the iterative nature of machine learning development, we further support efficient incremental executions of our queries, which requires a careful implementation when jointly used with our optimizations.
Evaluating Bayes Error Estimators on Read-World Datasets with FeeBee
Aug 30, 2021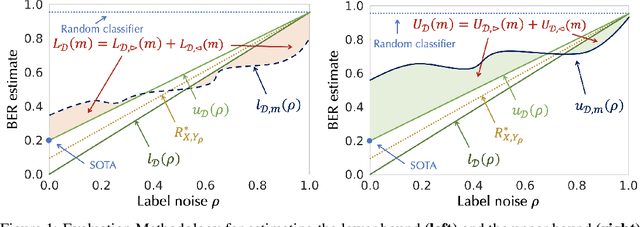
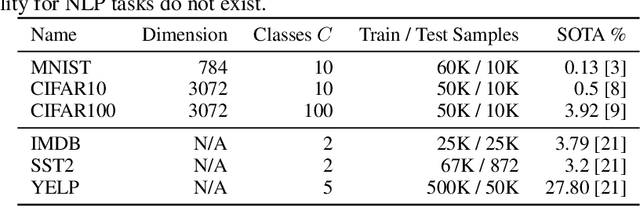
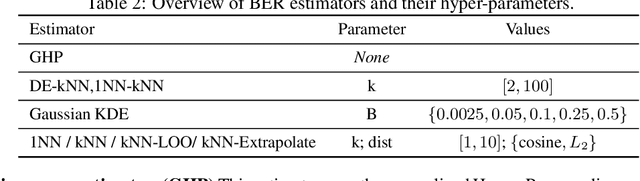
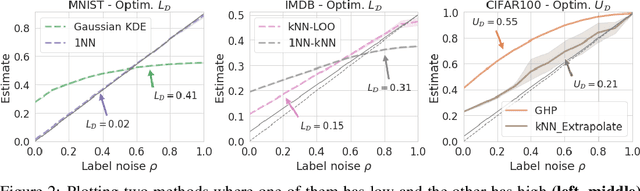
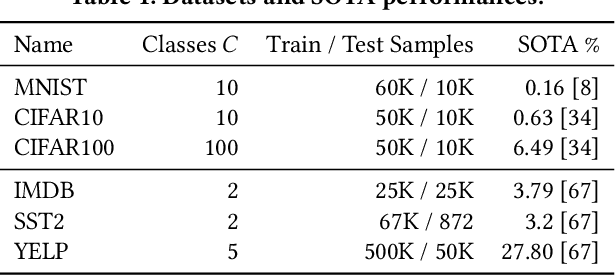
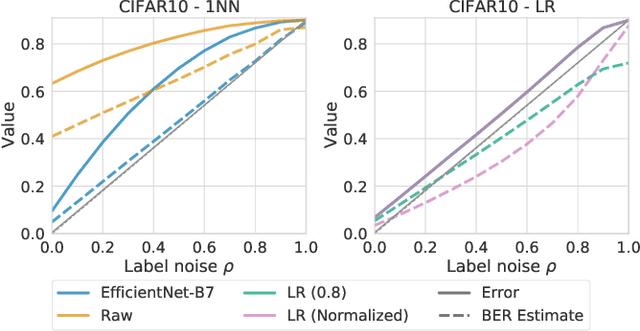
The Bayes error rate (BER) is a fundamental concept in machine learning that quantifies the best possible accuracy any classifier can achieve on a fixed probability distribution. Despite years of research on building estimators of lower and upper bounds for the BER, these were usually compared only on synthetic datasets with known probability distributions, leaving two key questions unanswered: (1) How well do they perform on real-world datasets?, and (2) How practical are they? Answering these is not trivial. Apart from the obvious challenge of an unknown BER for real-world datasets, there are two main aspects any BER estimator needs to overcome in order to be applicable in real-world settings: (1) the computational and sample complexity, and (2) the sensitivity and selection of hyper-parameters. In this work, we propose FeeBee, the first principled framework for analyzing and comparing BER estimators on any modern real-world dataset with unknown probability distribution. We achieve this by injecting a controlled amount of label noise and performing multiple evaluations on a series of different noise levels, supported by a theoretical result which allows drawing conclusions about the evolution of the BER. By implementing and analyzing 7 multi-class BER estimators on 6 commonly used datasets of the computer vision and NLP domains, FeeBee allows a thorough study of these estimators, clearly identifying strengths and weaknesses of each, whilst being easily deployable on any future BER estimator.
Knowledge Enhanced Machine Learning Pipeline against Diverse Adversarial Attacks
Jun 11, 2021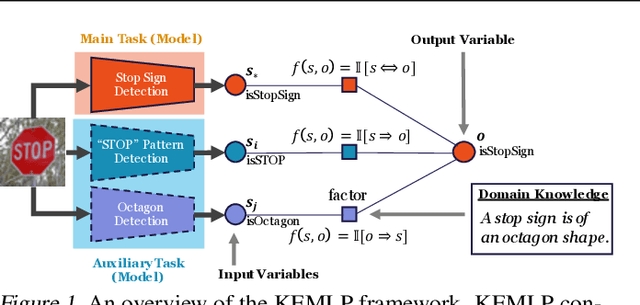
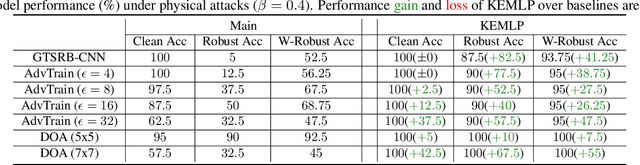
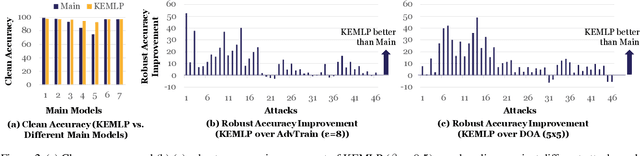
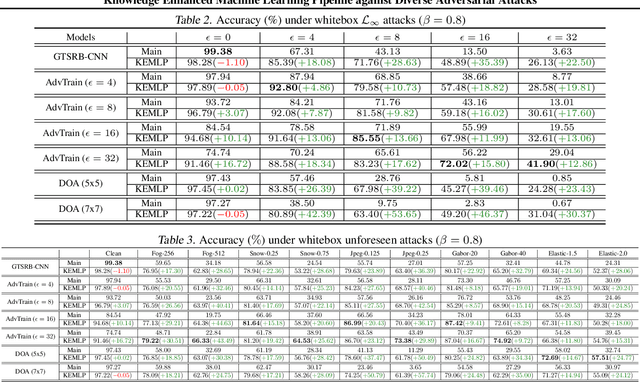
Despite the great successes achieved by deep neural networks (DNNs), recent studies show that they are vulnerable against adversarial examples, which aim to mislead DNNs by adding small adversarial perturbations. Several defenses have been proposed against such attacks, while many of them have been adaptively attacked. In this work, we aim to enhance the ML robustness from a different perspective by leveraging domain knowledge: We propose a Knowledge Enhanced Machine Learning Pipeline (KEMLP) to integrate domain knowledge (i.e., logic relationships among different predictions) into a probabilistic graphical model via first-order logic rules. In particular, we develop KEMLP by integrating a diverse set of weak auxiliary models based on their logical relationships to the main DNN model that performs the target task. Theoretically, we provide convergence results and prove that, under mild conditions, the prediction of KEMLP is more robust than that of the main DNN model. Empirically, we take road sign recognition as an example and leverage the relationships between road signs and their shapes and contents as domain knowledge. We show that compared with adversarial training and other baselines, KEMLP achieves higher robustness against physical attacks, $\mathcal{L}_p$ bounded attacks, unforeseen attacks, and natural corruptions under both whitebox and blackbox settings, while still maintaining high clean accuracy.
DataLens: Scalable Privacy Preserving Training via Gradient Compression and Aggregation
Mar 20, 2021

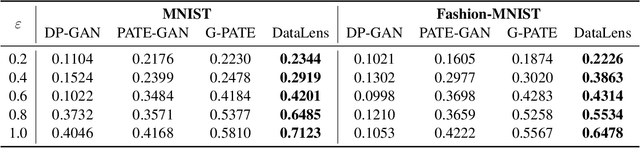
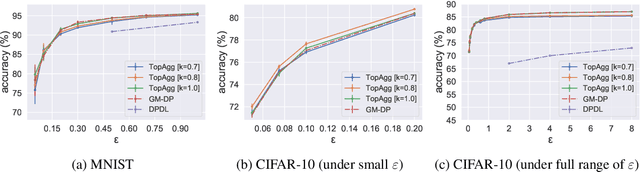
Recent success of deep neural networks (DNNs) hinges on the availability of large-scale dataset; however, training on such dataset often poses privacy risks for sensitive training information. In this paper, we aim to explore the power of generative models and gradient sparsity, and propose a scalable privacy-preserving generative model DATALENS. Comparing with the standard PATE privacy-preserving framework which allows teachers to vote on one-dimensional predictions, voting on the high dimensional gradient vectors is challenging in terms of privacy preservation. As dimension reduction techniques are required, we need to navigate a delicate tradeoff space between (1) the improvement of privacy preservation and (2) the slowdown of SGD convergence. To tackle this, we take advantage of communication efficient learning and propose a novel noise compression and aggregation approach TOPAGG by combining top-k compression for dimension reduction with a corresponding noise injection mechanism. We theoretically prove that the DATALENS framework guarantees differential privacy for its generated data, and provide analysis on its convergence. To demonstrate the practical usage of DATALENS, we conduct extensive experiments on diverse datasets including MNIST, Fashion-MNIST, and high dimensional CelebA, and we show that, DATALENS significantly outperforms other baseline DP generative models. In addition, we adapt the proposed TOPAGG approach, which is one of the key building blocks in DATALENS, to DP SGD training, and show that it is able to achieve higher utility than the state-of-the-art DP SGD approach in most cases.
A Data Quality-Driven View of MLOps
Feb 15, 2021

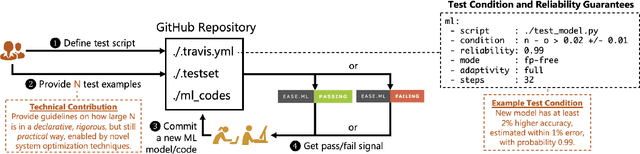
Developing machine learning models can be seen as a process similar to the one established for traditional software development. A key difference between the two lies in the strong dependency between the quality of a machine learning model and the quality of the data used to train or perform evaluations. In this work, we demonstrate how different aspects of data quality propagate through various stages of machine learning development. By performing a joint analysis of the impact of well-known data quality dimensions and the downstream machine learning process, we show that different components of a typical MLOps pipeline can be efficiently designed, providing both a technical and theoretical perspective.
On Automatic Feasibility Study for Machine Learning Application Development with ease.ml/snoopy
Oct 16, 2020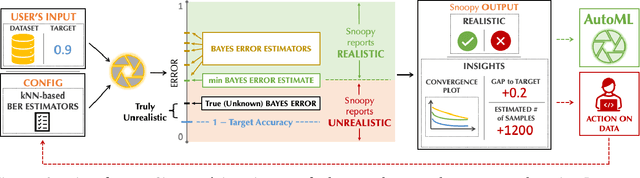

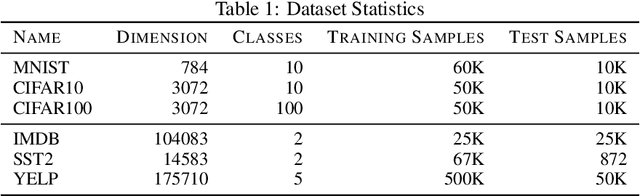
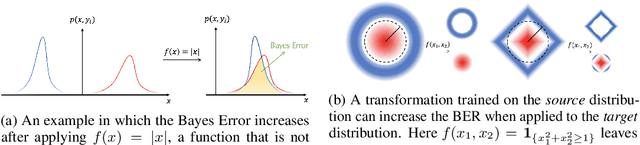
In our experience working with domain experts who are using today's AutoML systems, a common problem we encountered is what we call Unrealistic Expectation: When users have access to very noisy or challenging datasets, whilst being expected to achieve startlingly high accuracy with ML. Consequently, many computationally expensive AutoML runs and labour-intensive ML development processes are predestined to fail from the beginning. In traditional software engineering, this problem is addressed via a feasibility study, an indispensable step before developing any software system. In this paper we present ease.ml/snoopy with the goal of preforming an automatic feasibility study before building ML applications. A user provides inputs in the form of a dataset and a quality target (e.g., expected accuracy $>$ 0.8) and the system returns its deduction on whether this target is achievable using ML given the input data. We formulate this problem as estimating the irreducible error of the underlying task, also known as the Bayes error. The key contribution of this work is the study of this problem from a system's and empirical perspective -- we (1) propose practical "compromises" that enable the application of Bayes error estimators and (2) develop an evaluation framework that compares different estimators empirically on real-world data. We then systematically explore the design space by evaluating a range of estimators, reporting not only the improvements of our proposed estimator but also limitations of both our method and existing estimators.
On Convergence of Nearest Neighbor Classifiers over Feature Transformations
Oct 15, 2020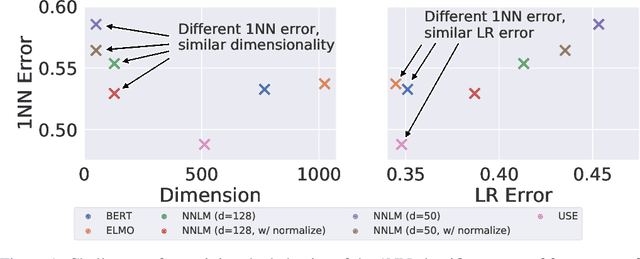
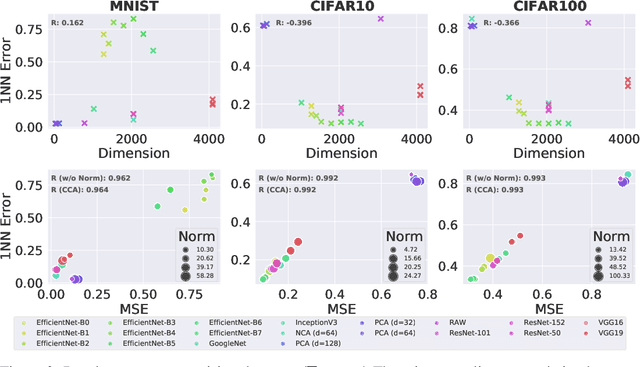
The k-Nearest Neighbors (kNN) classifier is a fundamental non-parametric machine learning algorithm. However, it is well known that it suffers from the curse of dimensionality, which is why in practice one often applies a kNN classifier on top of a (pre-trained) feature transformation. From a theoretical perspective, most, if not all theoretical results aimed at understanding the kNN classifier are derived for the raw feature space. This leads to an emerging gap between our theoretical understanding of kNN and its practical applications. In this paper, we take a first step towards bridging this gap. We provide a novel analysis on the convergence rates of a kNN classifier over transformed features. This analysis requires in-depth understanding of the properties that connect both the transformed space and the raw feature space. More precisely, we build our convergence bound upon two key properties of the transformed space: (1) safety -- how well can one recover the raw posterior from the transformed space, and (2) smoothness -- how complex this recovery function is. Based on our result, we are able to explain why some (pre-trained) feature transformations are better suited for a kNN classifier than other. We empirically validate that both properties have an impact on the kNN convergence on 30 feature transformations with 6 benchmark datasets spanning from the vision to the text domain.
Which Model to Transfer? Finding the Needle in the Growing Haystack
Oct 13, 2020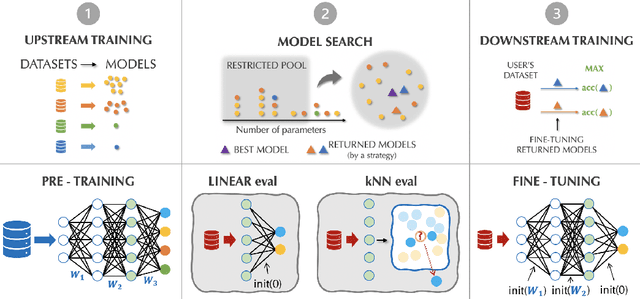
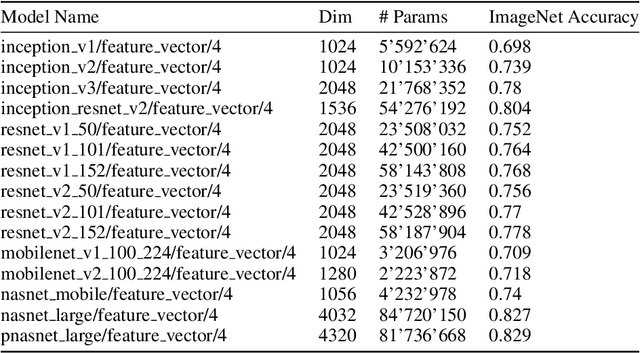
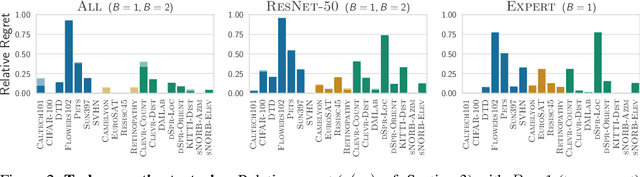
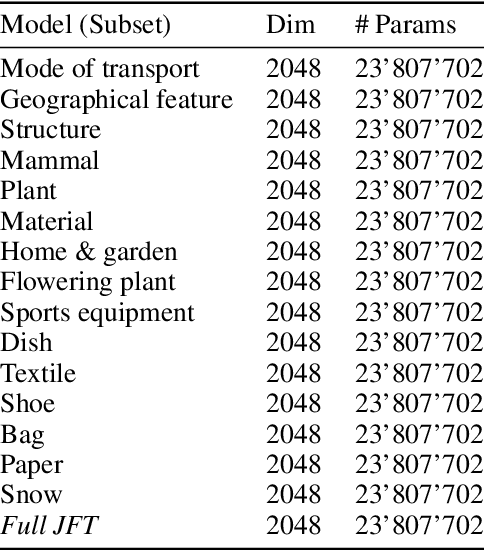
Transfer learning has been recently popularized as a data-efficient alternative to training models from scratch, in particular in vision and NLP where it provides a remarkably solid baseline. The emergence of rich model repositories, such as TensorFlow Hub, enables the practitioners and researchers to unleash the potential of these models across a wide range of downstream tasks. As these repositories keep growing exponentially, efficiently selecting a good model for the task at hand becomes paramount. We provide a formalization of this problem through a familiar notion of regret and introduce the predominant strategies, namely task-agnostic (e.g. picking the highest scoring ImageNet model) and task-aware search strategies (such as linear or kNN evaluation). We conduct a large-scale empirical study and show that both task-agnostic and task-aware methods can yield high regret. We then propose a simple and computationally efficient hybrid search strategy which outperforms the existing approaches. We highlight the practical benefits of the proposed solution on a set of 19 diverse vision tasks.
Provable Robust Learning Based on Transformation-Specific Smoothing
Mar 20, 2020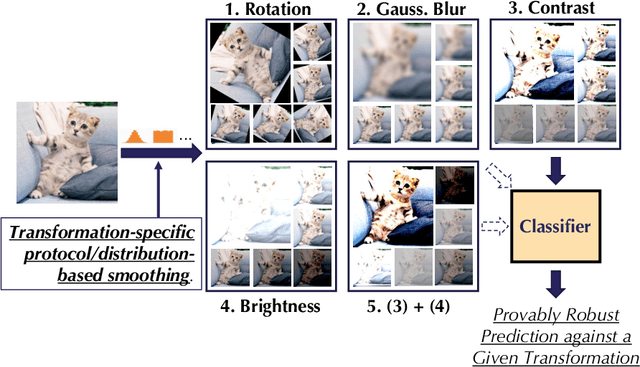

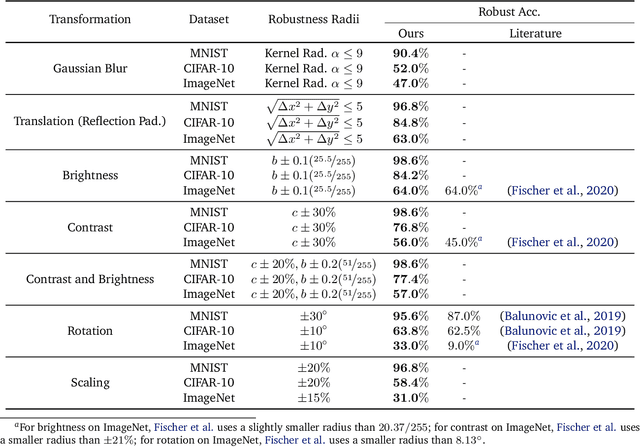
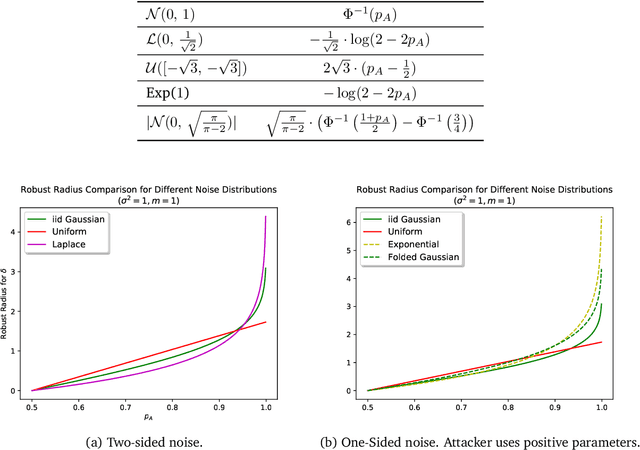
As machine learning systems become pervasive, safeguarding their security is critical. Recent work has demonstrated that motivated adversaries could manipulate the test data to mislead ML systems to make arbitrary mistakes. So far, most research has focused on providing provable robustness guarantees for a specific $\ell_p$ norm bounded adversarial perturbation. However, in practice there are more adversarial transformations that are realistic and of semantic meaning, requiring to be analyzed and ideally certified. In this paper we aim to provide a unified framework for certifying ML model robustness against general adversarial transformations. First, we leverage the function smoothing strategy to certify robustness against a series of adversarial transformations such as rotation, translation, Gaussian blur, etc. We then provide sufficient conditions and strategies for certifying certain transformations. For instance, we propose a novel sampling based interpolation approach with the estimated Lipschitz upper bound to certify the robustness against rotation transformation. In addition, we theoretically optimize the smoothing strategies for certifying the robustness of ML models against different transformations. For instance, we show that smoothing by sampling from exponential distribution provides tighter robustness bound than Gaussian. We also prove two generalization gaps for the proposed framework to understand its theoretic barrier. Extensive experiments show that our proposed unified framework significantly outperforms the state-of-the-art certified robustness approaches on several datasets including ImageNet.