 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHiFT: An Efficient, Flexible Search Engine for Transfer Learning
Apr 04, 2022
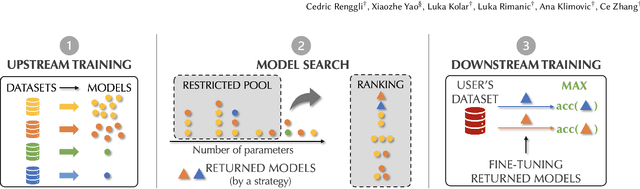
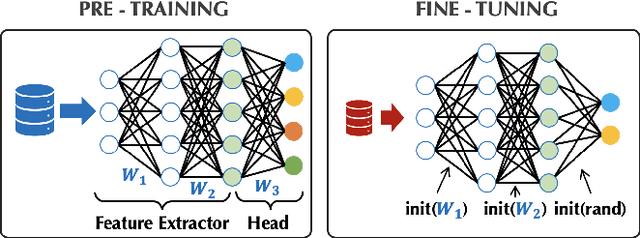
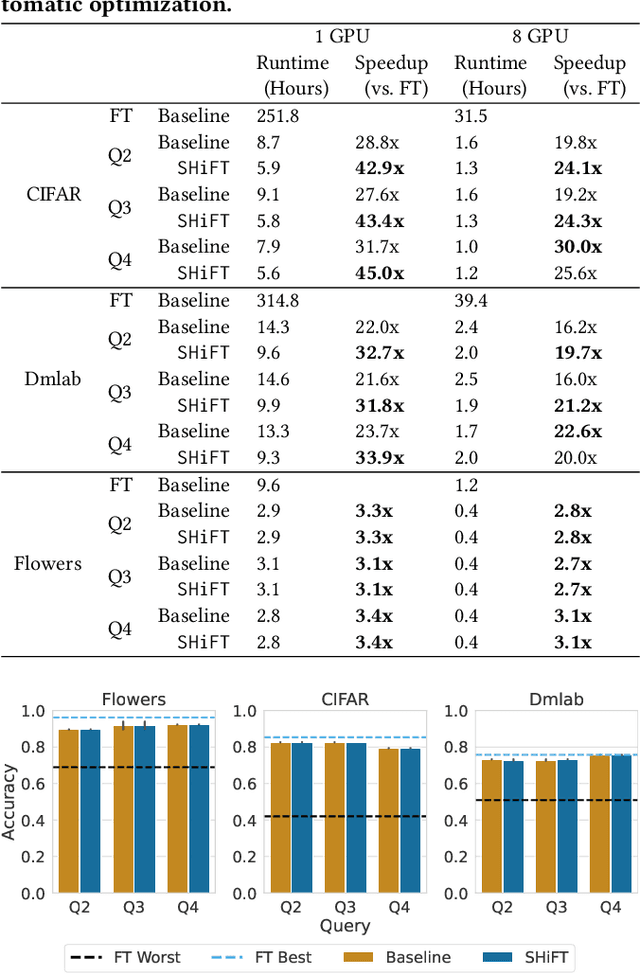
Transfer learning can be seen as a data- and compute-efficient alternative to training models from scratch. The emergence of rich model repositories, such as TensorFlow Hub, enables practitioners and researchers to unleash the potential of these models across a wide range of downstream tasks. As these repositories keep growing exponentially, efficiently selecting a good model for the task at hand becomes paramount. By carefully comparing various selection and search strategies, we realize that no single method outperforms the others, and hybrid or mixed strategies can be beneficial. Therefore, we propose SHiFT, the first downstream task-aware, flexible, and efficient model search engine for transfer learning. These properties are enabled by a custom query language SHiFT-QL together with a cost-based decision maker, which we empirically validate. Motivated by the iterative nature of machine learning development, we further support efficient incremental executions of our queries, which requires a careful implementation when jointly used with our optimizations.
On Automatic Feasibility Study for Machine Learning Application Development with ease.ml/snoopy
Oct 16, 2020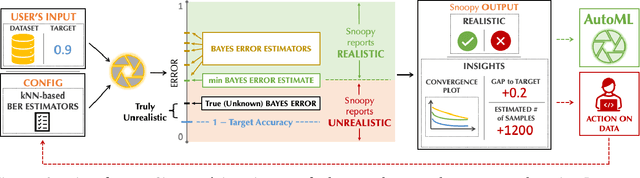
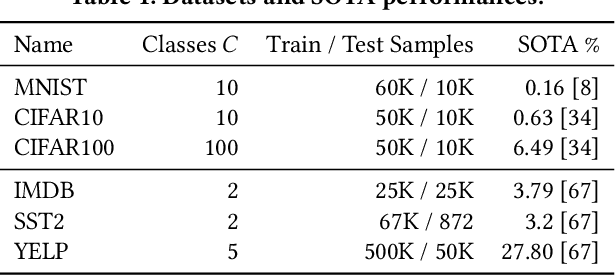
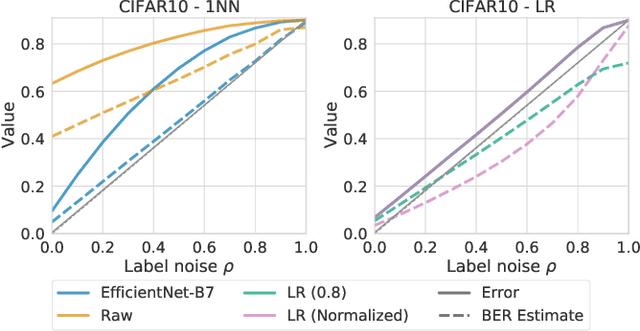

In our experience working with domain experts who are using today's AutoML systems, a common problem we encountered is what we call Unrealistic Expectation: When users have access to very noisy or challenging datasets, whilst being expected to achieve startlingly high accuracy with ML. Consequently, many computationally expensive AutoML runs and labour-intensive ML development processes are predestined to fail from the beginning. In traditional software engineering, this problem is addressed via a feasibility study, an indispensable step before developing any software system. In this paper we present ease.ml/snoopy with the goal of preforming an automatic feasibility study before building ML applications. A user provides inputs in the form of a dataset and a quality target (e.g., expected accuracy $>$ 0.8) and the system returns its deduction on whether this target is achievable using ML given the input data. We formulate this problem as estimating the irreducible error of the underlying task, also known as the Bayes error. The key contribution of this work is the study of this problem from a system's and empirical perspective -- we (1) propose practical "compromises" that enable the application of Bayes error estimators and (2) develop an evaluation framework that compares different estimators empirically on real-world data. We then systematically explore the design space by evaluating a range of estimators, reporting not only the improvements of our proposed estimator but also limitations of both our method and existing estimators.
Iterative Correction of Sensor Degradation and a Bayesian Multi-Sensor Data Fusion Method
Sep 07, 2020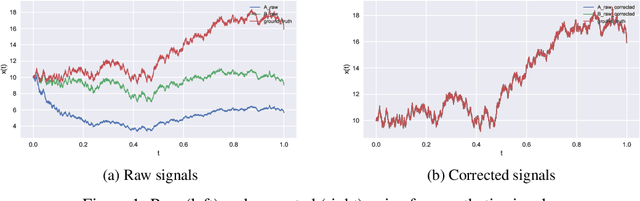
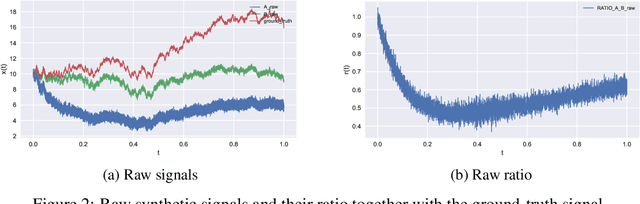
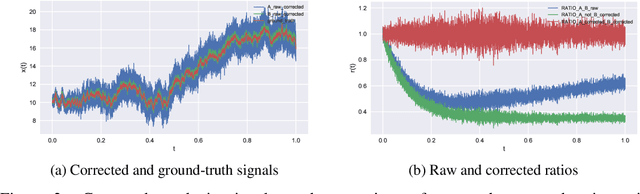
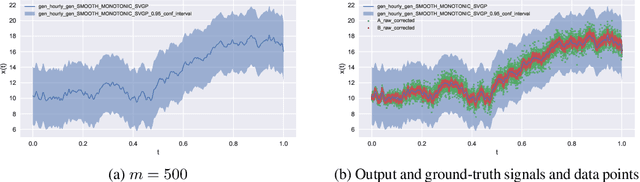
We present a novel method for inferring ground-truth signal from multiple degraded signals, affected by different amounts of sensor exposure. The algorithm learns a multiplicative degradation effect by performing iterative corrections of two signals solely from the ratio between them. The degradation function d should be continuous, satisfy monotonicity, and d(0) = 1. We use smoothed monotonic regression method, where we easily incorporate the aforementioned criteria to the fitting part. We include theoretical analysis and prove convergence to the ground-truth signal for the noiseless measurement model. Lastly, we present an approach to fuse the noisy corrected signals using Gaussian processes. We use sparse Gaussian processes that can be utilized for a large number of measurements together with a specialized kernel that enables the estimation of noise values of all sensors. The data fusion framework naturally handles data gaps and provides a simple and powerful method for observing the signal trends on multiple timescales(long-term and short-term signal properties). The viability of correction method is evaluated on a synthetic dataset with known ground-truth signal.