 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFundamental Challenges in Evaluating Text2SQL Solutions and Detecting Their Limitations
Jan 30, 2025
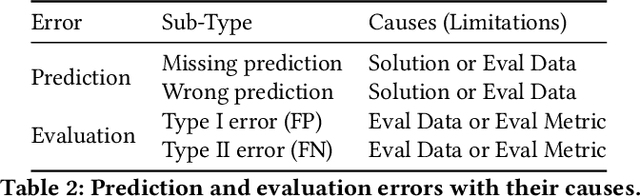
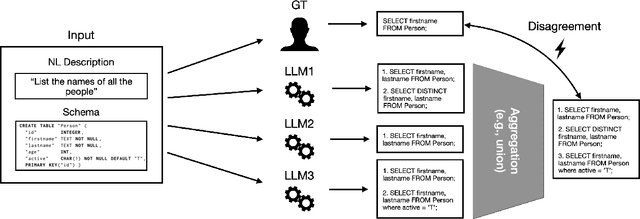
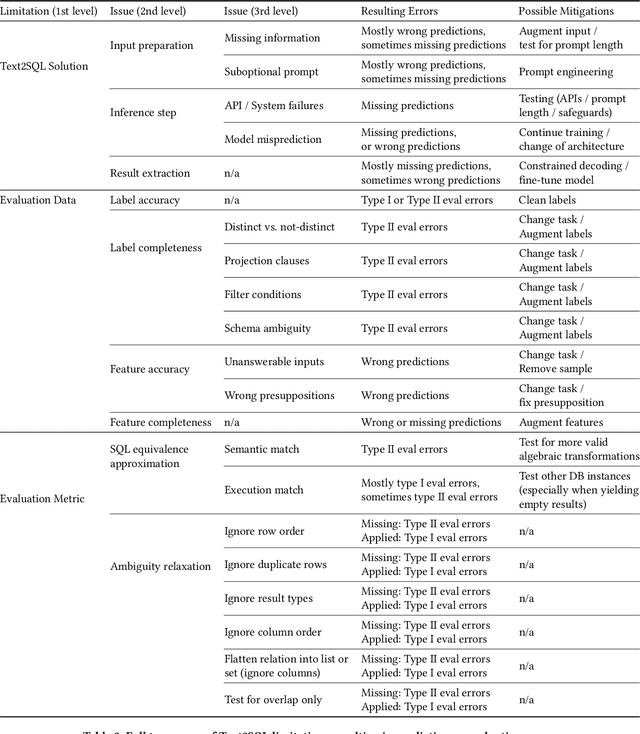
In this work, we dive into the fundamental challenges of evaluating Text2SQL solutions and highlight potential failure causes and the potential risks of relying on aggregate metrics in existing benchmarks. We identify two largely unaddressed limitations in current open benchmarks: (1) data quality issues in the evaluation data, mainly attributed to the lack of capturing the probabilistic nature of translating a natural language description into a structured query (e.g., NL ambiguity), and (2) the bias introduced by using different match functions as approximations for SQL equivalence. To put both limitations into context, we propose a unified taxonomy of all Text2SQL limitations that can lead to both prediction and evaluation errors. We then motivate the taxonomy by providing a survey of Text2SQL limitations using state-of-the-art Text2SQL solutions and benchmarks. We describe the causes of limitations with real-world examples and propose potential mitigation solutions for each category in the taxonomy. We conclude by highlighting the open challenges encountered when deploying such mitigation strategies or attempting to automatically apply the taxonomy.
Incremental IVF Index Maintenance for Streaming Vector Search
Nov 01, 2024

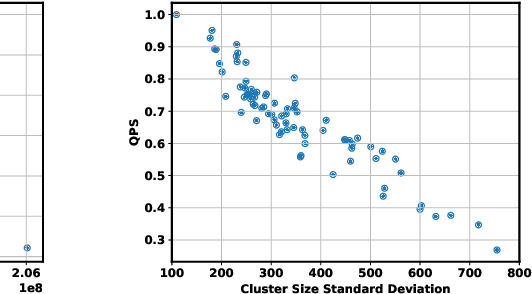

The prevalence of vector similarity search in modern machine learning applications and the continuously changing nature of data processed by these applications necessitate efficient and effective index maintenance techniques for vector search indexes. Designed primarily for static workloads, existing vector search indexes degrade in search quality and performance as the underlying data is updated unless costly index reconstruction is performed. To address this, we introduce Ada-IVF, an incremental indexing methodology for Inverted File (IVF) indexes. Ada-IVF consists of 1) an adaptive maintenance policy that decides which index partitions are problematic for performance and should be repartitioned and 2) a local re-clustering mechanism that determines how to repartition them. Compared with state-of-the-art dynamic IVF index maintenance strategies, Ada-IVF achieves an average of 2x and up to 5x higher update throughput across a range of benchmark workloads.
Co-design Hardware and Algorithm for Vector Search
Jul 06, 2023Vector search has emerged as the foundation for large-scale information retrieval and machine learning systems, with search engines like Google and Bing processing tens of thousands of queries per second on petabyte-scale document datasets by evaluating vector similarities between encoded query texts and web documents. As performance demands for vector search systems surge, accelerated hardware offers a promising solution in the post-Moore's Law era. We introduce \textit{FANNS}, an end-to-end and scalable vector search framework on FPGAs. Given a user-provided recall requirement on a dataset and a hardware resource budget, \textit{FANNS} automatically co-designs hardware and algorithm, subsequently generating the corresponding accelerator. The framework also supports scale-out by incorporating a hardware TCP/IP stack in the accelerator. \textit{FANNS} attains up to 23.0$\times$ and 37.2$\times$ speedup compared to FPGA and CPU baselines, respectively, and demonstrates superior scalability to GPUs, achieving 5.5$\times$ and 7.6$\times$ speedup in median and 95\textsuperscript{th} percentile (P95) latency within an eight-accelerator configuration. The remarkable performance of \textit{FANNS} lays a robust groundwork for future FPGA integration in data centers and AI supercomputers.
Stochastic Gradient Descent without Full Data Shuffle
Jun 12, 2022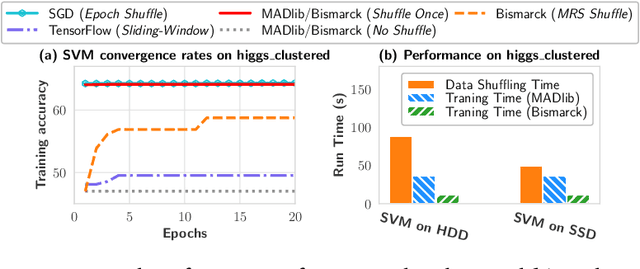

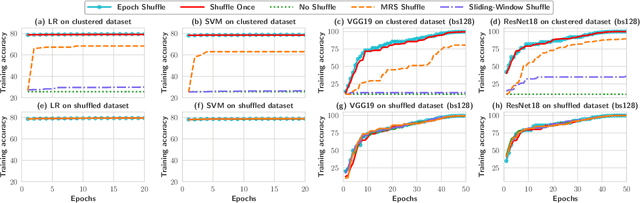
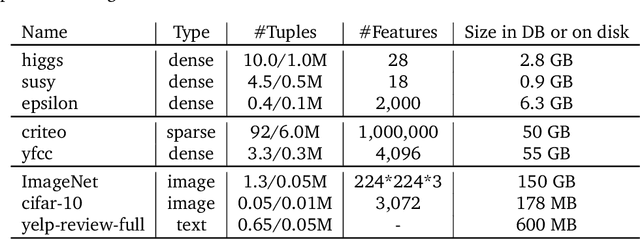
Stochastic gradient descent (SGD) is the cornerstone of modern machine learning (ML) systems. Despite its computational efficiency, SGD requires random data access that is inherently inefficient when implemented in systems that rely on block-addressable secondary storage such as HDD and SSD, e.g., TensorFlow/PyTorch and in-DB ML systems over large files. To address this impedance mismatch, various data shuffling strategies have been proposed to balance the convergence rate of SGD (which favors randomness) and its I/O performance (which favors sequential access). In this paper, we first conduct a systematic empirical study on existing data shuffling strategies, which reveals that all existing strategies have room for improvement -- they all suffer in terms of I/O performance or convergence rate. With this in mind, we propose a simple but novel hierarchical data shuffling strategy, CorgiPile. Compared with existing strategies, CorgiPile avoids a full data shuffle while maintaining comparable convergence rate of SGD as if a full shuffle were performed. We provide a non-trivial theoretical analysis of CorgiPile on its convergence behavior. We further integrate CorgiPile into PyTorch by designing new parallel/distributed shuffle operators inside a new CorgiPileDataSet API. We also integrate CorgiPile into PostgreSQL by introducing three new physical operators with optimizations. Our experimental results show that CorgiPile can achieve comparable convergence rate with the full shuffle based SGD for both deep learning and generalized linear models. For deep learning models on ImageNet dataset, CorgiPile is 1.5X faster than PyTorch with full data shuffle. For in-DB ML with linear models, CorgiPile is 1.6X-12.8X faster than two state-of-the-art in-DB ML systems, Apache MADlib and Bismarck, on both HDD and SSD.
SHiFT: An Efficient, Flexible Search Engine for Transfer Learning
Apr 04, 2022
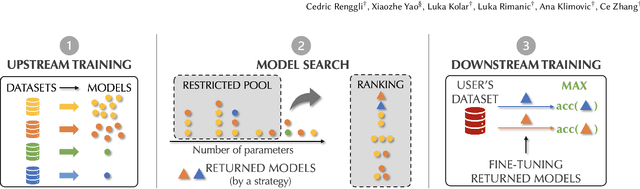
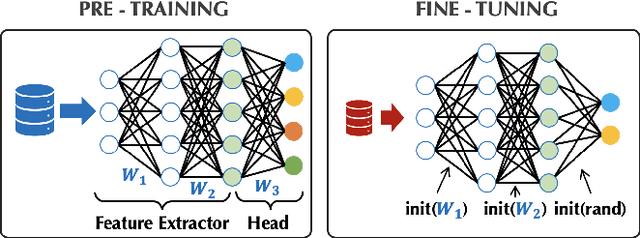
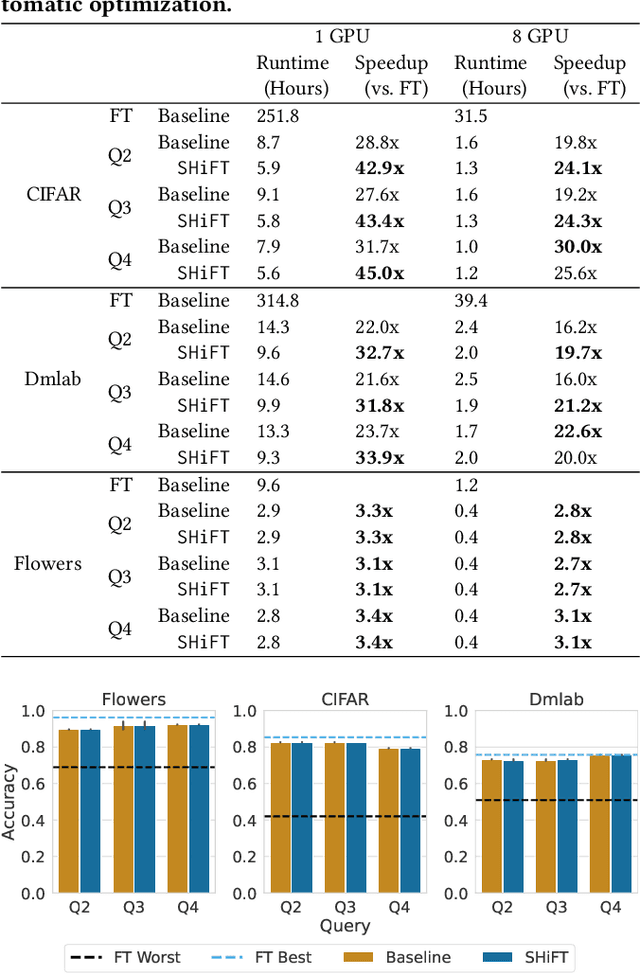
Transfer learning can be seen as a data- and compute-efficient alternative to training models from scratch. The emergence of rich model repositories, such as TensorFlow Hub, enables practitioners and researchers to unleash the potential of these models across a wide range of downstream tasks. As these repositories keep growing exponentially, efficiently selecting a good model for the task at hand becomes paramount. By carefully comparing various selection and search strategies, we realize that no single method outperforms the others, and hybrid or mixed strategies can be beneficial. Therefore, we propose SHiFT, the first downstream task-aware, flexible, and efficient model search engine for transfer learning. These properties are enabled by a custom query language SHiFT-QL together with a cost-based decision maker, which we empirically validate. Motivated by the iterative nature of machine learning development, we further support efficient incremental executions of our queries, which requires a careful implementation when jointly used with our optimizations.
Learning to Merge Tokens in Vision Transformers
Feb 24, 2022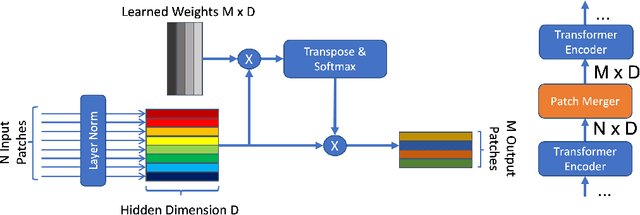
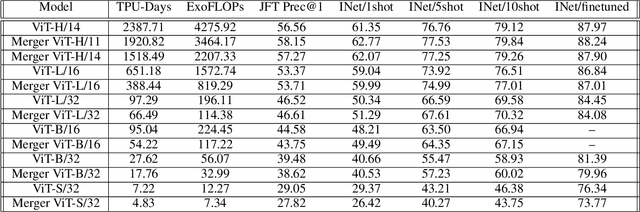
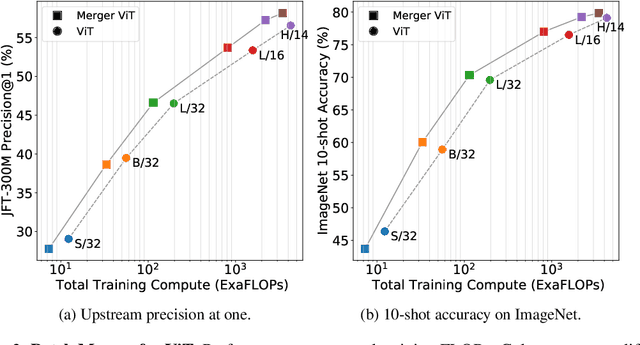
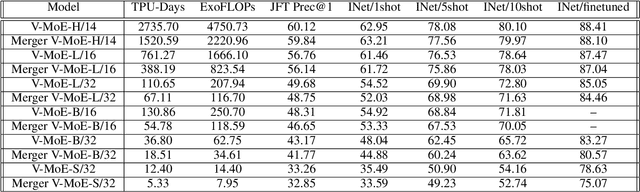
Transformers are widely applied to solve natural language understanding and computer vision tasks. While scaling up these architectures leads to improved performance, it often comes at the expense of much higher computational costs. In order for large-scale models to remain practical in real-world systems, there is a need for reducing their computational overhead. In this work, we present the PatchMerger, a simple module that reduces the number of patches or tokens the network has to process by merging them between two consecutive intermediate layers. We show that the PatchMerger achieves a significant speedup across various model sizes while matching the original performance both upstream and downstream after fine-tuning.
Dynamic Human Evaluation for Relative Model Comparisons
Dec 15, 2021
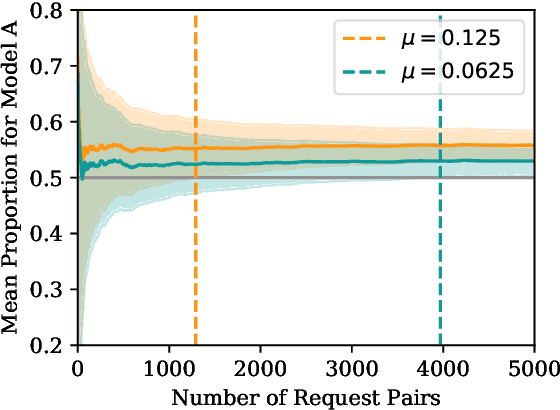
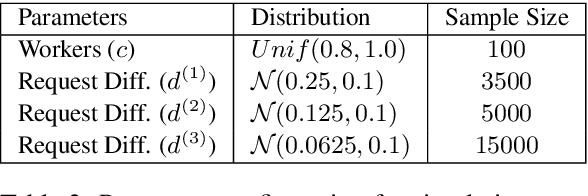
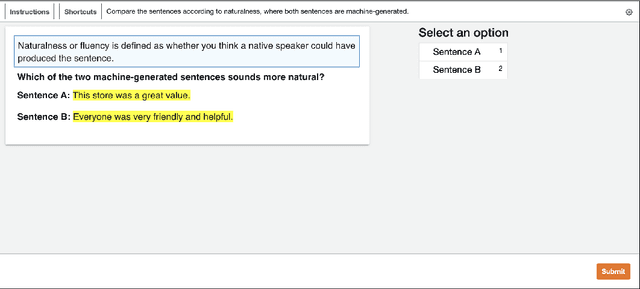
Collecting human judgements is currently the most reliable evaluation method for natural language generation systems. Automatic metrics have reported flaws when applied to measure quality aspects of generated text and have been shown to correlate poorly with human judgements. However, human evaluation is time and cost-intensive, and we lack consensus on designing and conducting human evaluation experiments. Thus there is a need for streamlined approaches for efficient collection of human judgements when evaluating natural language generation systems. Therefore, we present a dynamic approach to measure the required number of human annotations when evaluating generated outputs in relative comparison settings. We propose an agent-based framework of human evaluation to assess multiple labelling strategies and methods to decide the better model in a simulation and a crowdsourcing case study. The main results indicate that a decision about the superior model can be made with high probability across different labelling strategies, where assigning a single random worker per task requires the least overall labelling effort and thus the least cost.
Evaluating Bayes Error Estimators on Read-World Datasets with FeeBee
Aug 30, 2021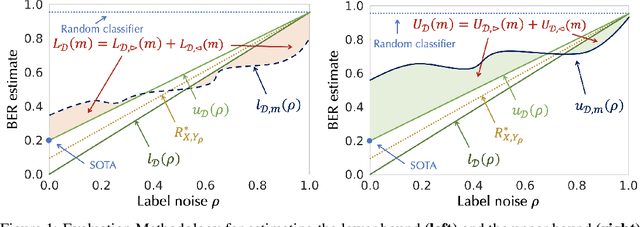
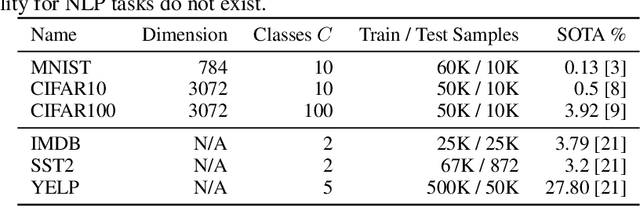
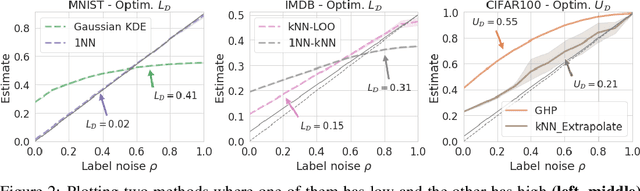
The Bayes error rate (BER) is a fundamental concept in machine learning that quantifies the best possible accuracy any classifier can achieve on a fixed probability distribution. Despite years of research on building estimators of lower and upper bounds for the BER, these were usually compared only on synthetic datasets with known probability distributions, leaving two key questions unanswered: (1) How well do they perform on real-world datasets?, and (2) How practical are they? Answering these is not trivial. Apart from the obvious challenge of an unknown BER for real-world datasets, there are two main aspects any BER estimator needs to overcome in order to be applicable in real-world settings: (1) the computational and sample complexity, and (2) the sensitivity and selection of hyper-parameters. In this work, we propose FeeBee, the first principled framework for analyzing and comparing BER estimators on any modern real-world dataset with unknown probability distribution. We achieve this by injecting a controlled amount of label noise and performing multiple evaluations on a series of different noise levels, supported by a theoretical result which allows drawing conclusions about the evolution of the BER. By implementing and analyzing 7 multi-class BER estimators on 6 commonly used datasets of the computer vision and NLP domains, FeeBee allows a thorough study of these estimators, clearly identifying strengths and weaknesses of each, whilst being easily deployable on any future BER estimator.
Decoding EEG Brain Activity for Multi-Modal Natural Language Processing
Feb 17, 2021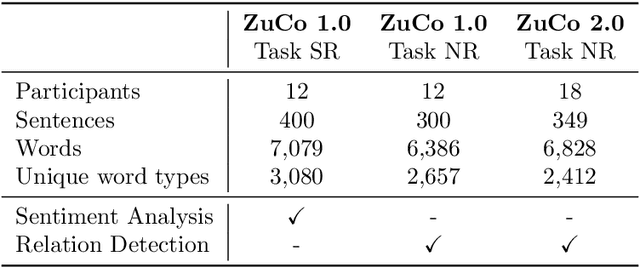
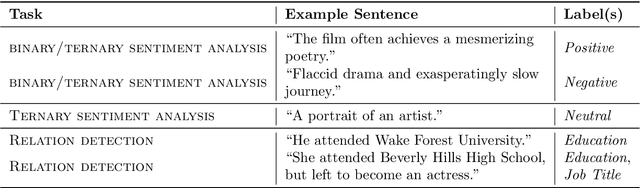
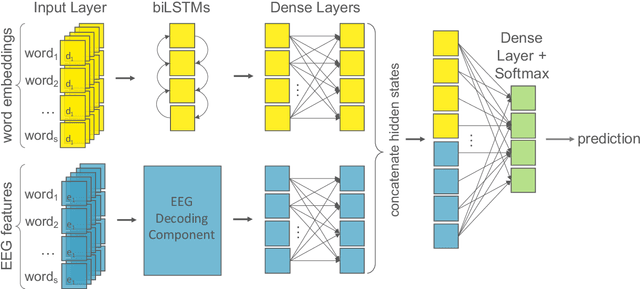
Until recently, human behavioral data from reading has mainly been of interest to researchers to understand human cognition. However, these human language processing signals can also be beneficial in machine learning-based natural language processing tasks. Using EEG brain activity to this purpose is largely unexplored as of yet. In this paper, we present the first large-scale study of systematically analyzing the potential of EEG brain activity data for improving natural language processing tasks, with a special focus on which features of the signal are most beneficial. We present a multi-modal machine learning architecture that learns jointly from textual input as well as from EEG features. We find that filtering the EEG signals into frequency bands is more beneficial than using the broadband signal. Moreover, for a range of word embedding types, EEG data improves binary and ternary sentiment classification and outperforms multiple baselines. For more complex tasks such as relation detection, further research is needed. Finally, EEG data shows to be particularly promising when limited training data is available.
A Data Quality-Driven View of MLOps
Feb 15, 2021
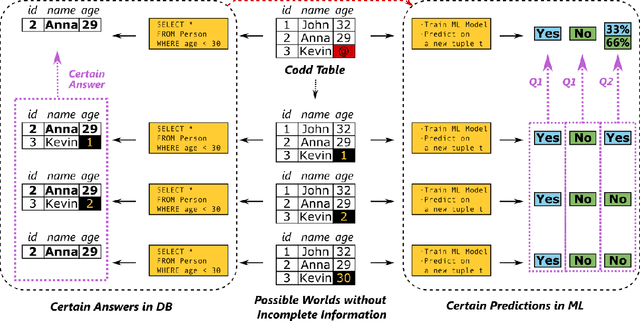

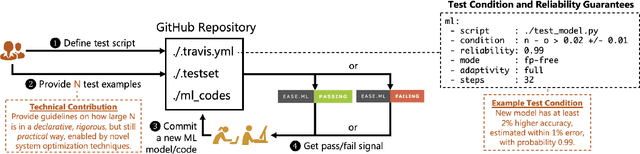
Developing machine learning models can be seen as a process similar to the one established for traditional software development. A key difference between the two lies in the strong dependency between the quality of a machine learning model and the quality of the data used to train or perform evaluations. In this work, we demonstrate how different aspects of data quality propagate through various stages of machine learning development. By performing a joint analysis of the impact of well-known data quality dimensions and the downstream machine learning process, we show that different components of a typical MLOps pipeline can be efficiently designed, providing both a technical and theoretical perspective.