 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFundamental Challenges in Evaluating Text2SQL Solutions and Detecting Their Limitations
Jan 30, 2025
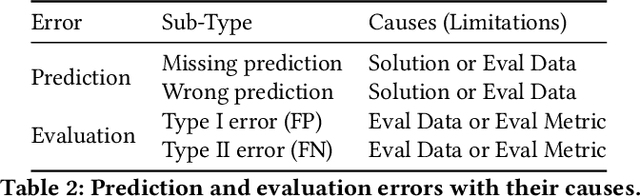
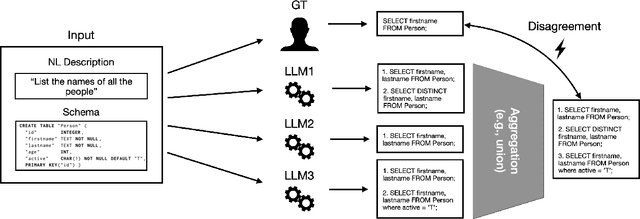
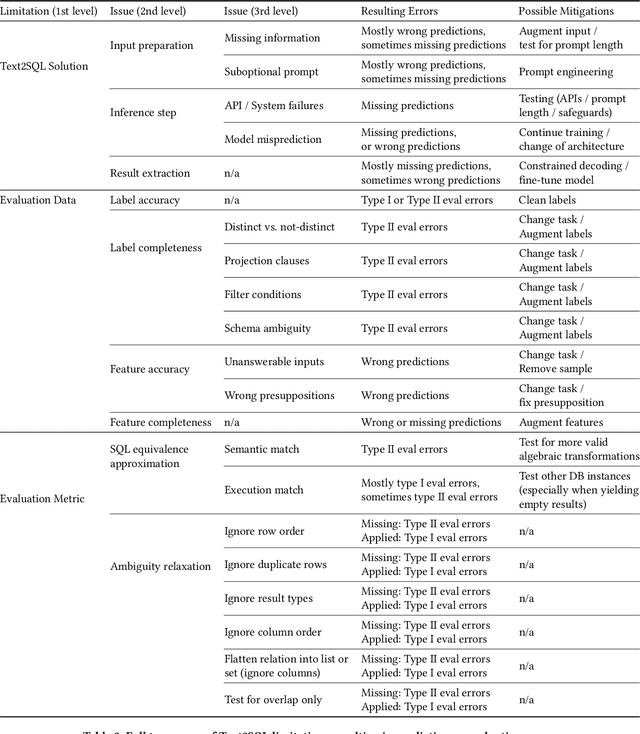
In this work, we dive into the fundamental challenges of evaluating Text2SQL solutions and highlight potential failure causes and the potential risks of relying on aggregate metrics in existing benchmarks. We identify two largely unaddressed limitations in current open benchmarks: (1) data quality issues in the evaluation data, mainly attributed to the lack of capturing the probabilistic nature of translating a natural language description into a structured query (e.g., NL ambiguity), and (2) the bias introduced by using different match functions as approximations for SQL equivalence. To put both limitations into context, we propose a unified taxonomy of all Text2SQL limitations that can lead to both prediction and evaluation errors. We then motivate the taxonomy by providing a survey of Text2SQL limitations using state-of-the-art Text2SQL solutions and benchmarks. We describe the causes of limitations with real-world examples and propose potential mitigation solutions for each category in the taxonomy. We conclude by highlighting the open challenges encountered when deploying such mitigation strategies or attempting to automatically apply the taxonomy.
Incremental IVF Index Maintenance for Streaming Vector Search
Nov 01, 2024

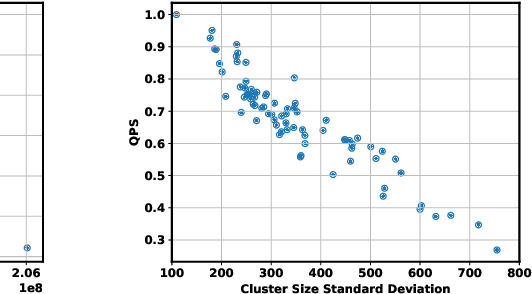

The prevalence of vector similarity search in modern machine learning applications and the continuously changing nature of data processed by these applications necessitate efficient and effective index maintenance techniques for vector search indexes. Designed primarily for static workloads, existing vector search indexes degrade in search quality and performance as the underlying data is updated unless costly index reconstruction is performed. To address this, we introduce Ada-IVF, an incremental indexing methodology for Inverted File (IVF) indexes. Ada-IVF consists of 1) an adaptive maintenance policy that decides which index partitions are problematic for performance and should be repartitioned and 2) a local re-clustering mechanism that determines how to repartition them. Compared with state-of-the-art dynamic IVF index maintenance strategies, Ada-IVF achieves an average of 2x and up to 5x higher update throughput across a range of benchmark workloads.
FLEEK: Factual Error Detection and Correction with Evidence Retrieved from External Knowledge
Oct 26, 2023
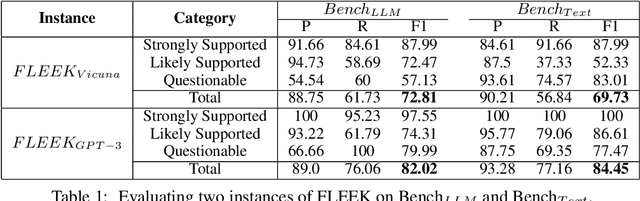
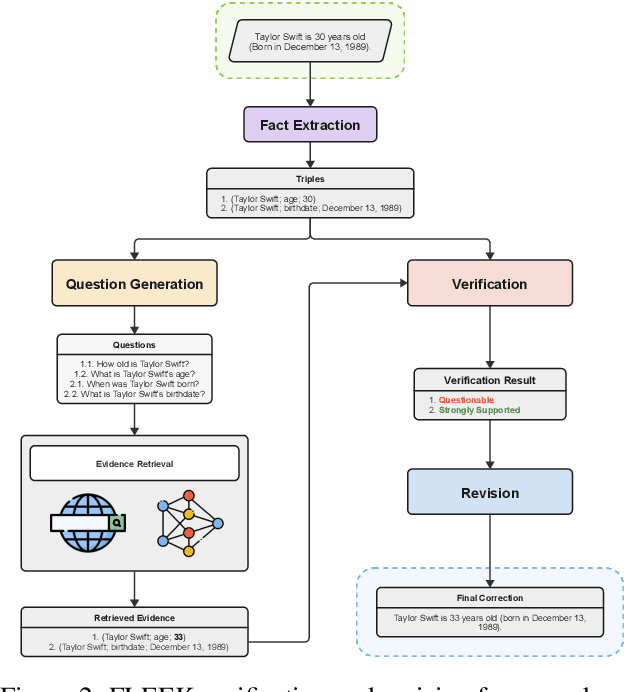
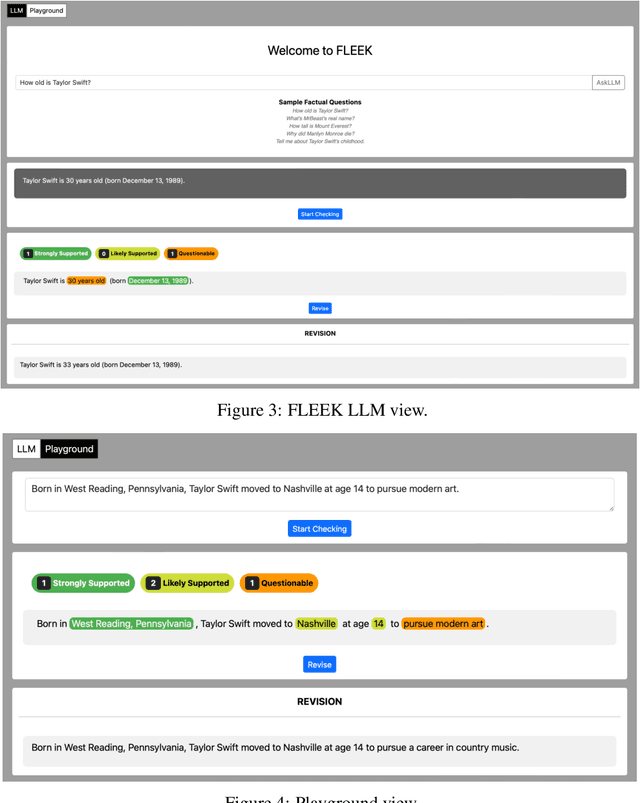
Detecting factual errors in textual information, whether generated by large language models (LLM) or curated by humans, is crucial for making informed decisions. LLMs' inability to attribute their claims to external knowledge and their tendency to hallucinate makes it difficult to rely on their responses. Humans, too, are prone to factual errors in their writing. Since manual detection and correction of factual errors is labor-intensive, developing an automatic approach can greatly reduce human effort. We present FLEEK, a prototype tool that automatically extracts factual claims from text, gathers evidence from external knowledge sources, evaluates the factuality of each claim, and suggests revisions for identified errors using the collected evidence. Initial empirical evaluation on fact error detection (77-85\% F1) shows the potential of FLEEK. A video demo of FLEEK can be found at https://youtu.be/NapJFUlkPdQ.
Growing and Serving Large Open-domain Knowledge Graphs
May 16, 2023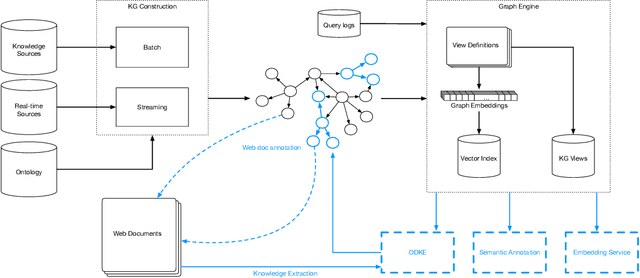
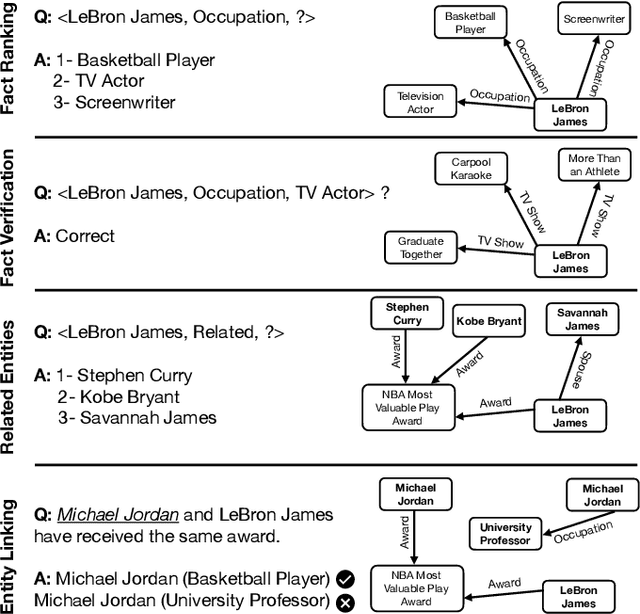
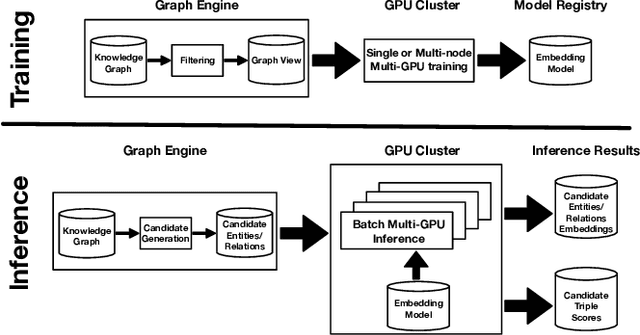
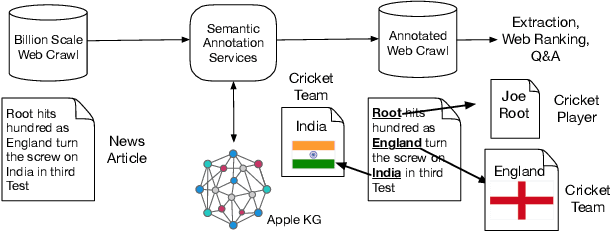
Applications of large open-domain knowledge graphs (KGs) to real-world problems pose many unique challenges. In this paper, we present extensions to Saga our platform for continuous construction and serving of knowledge at scale. In particular, we describe a pipeline for training knowledge graph embeddings that powers key capabilities such as fact ranking, fact verification, a related entities service, and support for entity linking. We then describe how our platform, including graph embeddings, can be leveraged to create a Semantic Annotation service that links unstructured Web documents to entities in our KG. Semantic annotation of the Web effectively expands our knowledge graph with edges to open-domain Web content which can be used in various search and ranking problems. Finally, we leverage annotated Web documents to drive Open-domain Knowledge Extraction. This targeted extraction framework identifies important coverage issues in the KG, then finds relevant data sources for target entities on the Web and extracts missing information to enrich the KG. Finally, we describe adaptations to our knowledge platform needed to construct and serve private personal knowledge on-device. This includes private incremental KG construction, cross-device knowledge sync, and global knowledge enrichment.
High-Throughput Vector Similarity Search in Knowledge Graphs
Apr 04, 2023



There is an increasing adoption of machine learning for encoding data into vectors to serve online recommendation and search use cases. As a result, recent data management systems propose augmenting query processing with online vector similarity search. In this work, we explore vector similarity search in the context of Knowledge Graphs (KGs). Motivated by the tasks of finding related KG queries and entities for past KG query workloads, we focus on hybrid vector similarity search (hybrid queries for short) where part of the query corresponds to vector similarity search and part of the query corresponds to predicates over relational attributes associated with the underlying data vectors. For example, given past KG queries for a song entity, we want to construct new queries for new song entities whose vector representations are close to the vector representation of the entity in the past KG query. But entities in a KG also have non-vector attributes such as a song associated with an artist, a genre, and a release date. Therefore, suggested entities must also satisfy query predicates over non-vector attributes beyond a vector-based similarity predicate. While these tasks are central to KGs, our contributions are generally applicable to hybrid queries. In contrast to prior works that optimize online queries, we focus on enabling efficient batch processing of past hybrid query workloads. We present our system, HQI, for high-throughput batch processing of hybrid queries. We introduce a workload-aware vector data partitioning scheme to tailor the vector index layout to the given workload and describe a multi-query optimization technique to reduce the overhead of vector similarity computations. We evaluate our methods on industrial workloads and demonstrate that HQI yields a 31x improvement in throughput for finding related KG queries compared to existing hybrid query processing approaches.
Saga: A Platform for Continuous Construction and Serving of Knowledge At Scale
Apr 15, 2022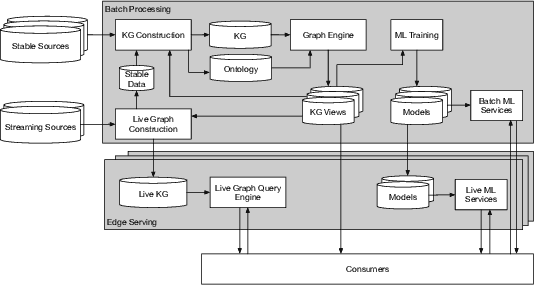
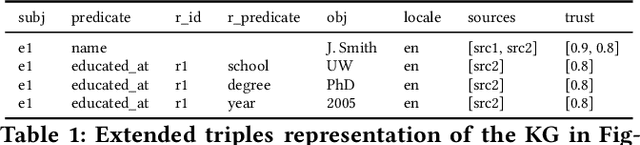
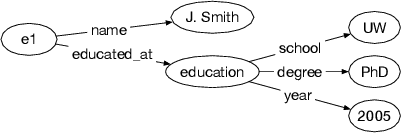
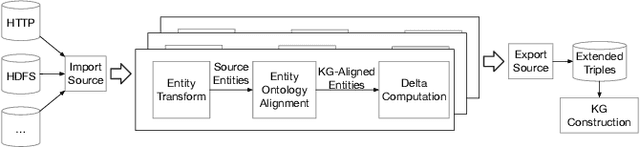
We introduce Saga, a next-generation knowledge construction and serving platform for powering knowledge-based applications at industrial scale. Saga follows a hybrid batch-incremental design to continuously integrate billions of facts about real-world entities and construct a central knowledge graph that supports multiple production use cases with diverse requirements around data freshness, accuracy, and availability. In this paper, we discuss the unique challenges associated with knowledge graph construction at industrial scale, and review the main components of Saga and how they address these challenges. Finally, we share lessons-learned from a wide array of production use cases powered by Saga.
Ember: No-Code Context Enrichment via Similarity-Based Keyless Joins
Jun 02, 2021
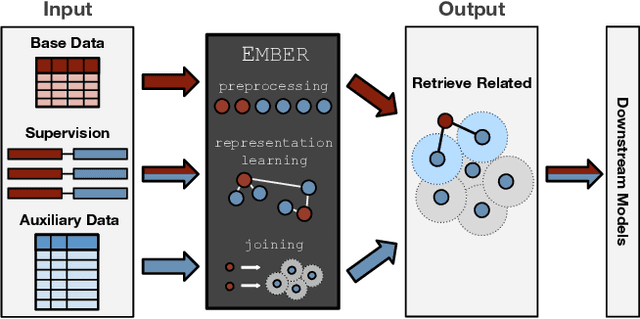
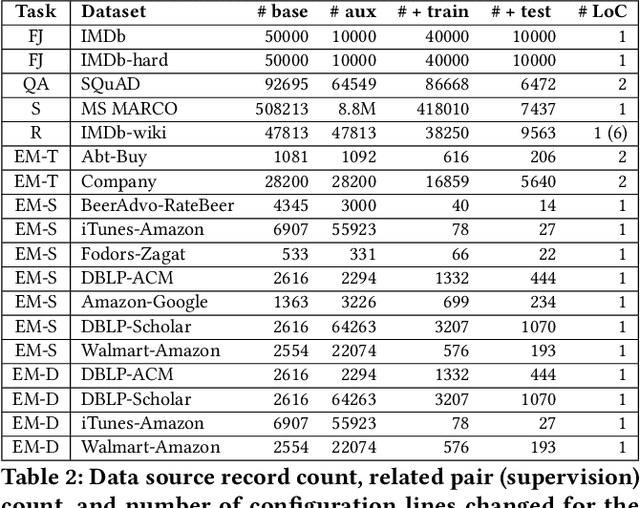
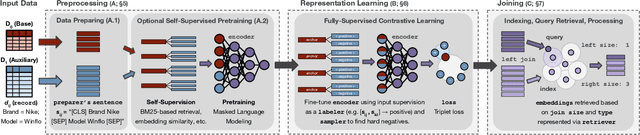
Structured data, or data that adheres to a pre-defined schema, can suffer from fragmented context: information describing a single entity can be scattered across multiple datasets or tables tailored for specific business needs, with no explicit linking keys (e.g., primary key-foreign key relationships or heuristic functions). Context enrichment, or rebuilding fragmented context, using keyless joins is an implicit or explicit step in machine learning (ML) pipelines over structured data sources. This process is tedious, domain-specific, and lacks support in now-prevalent no-code ML systems that let users create ML pipelines using just input data and high-level configuration files. In response, we propose Ember, a system that abstracts and automates keyless joins to generalize context enrichment. Our key insight is that Ember can enable a general keyless join operator by constructing an index populated with task-specific embeddings. Ember learns these embeddings by leveraging Transformer-based representation learning techniques. We describe our core architectural principles and operators when developing Ember, and empirically demonstrate that Ember allows users to develop no-code pipelines for five domains, including search, recommendation and question answering, and can exceed alternatives by up to 39% recall, with as little as a single line configuration change.
Batchwise Probabilistic Incremental Data Cleaning
Nov 09, 2020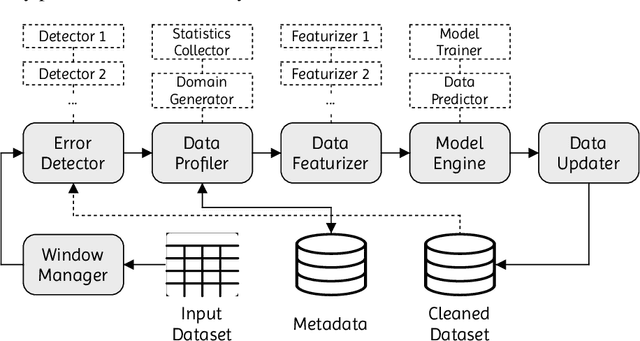
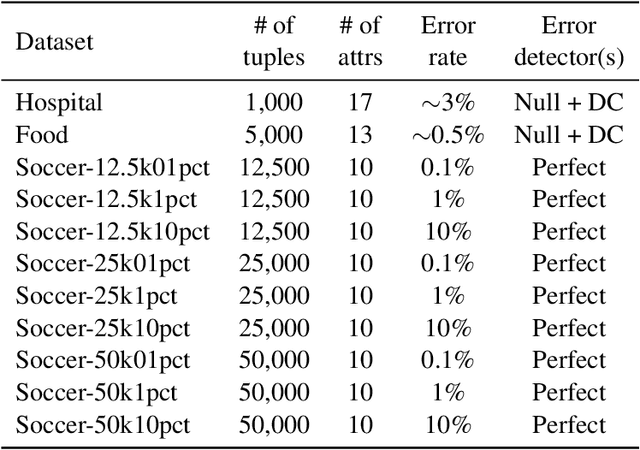
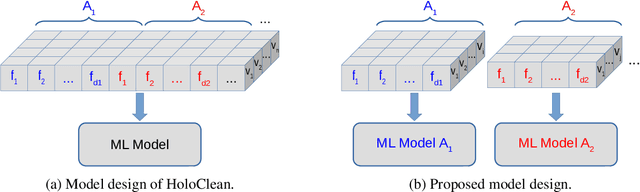
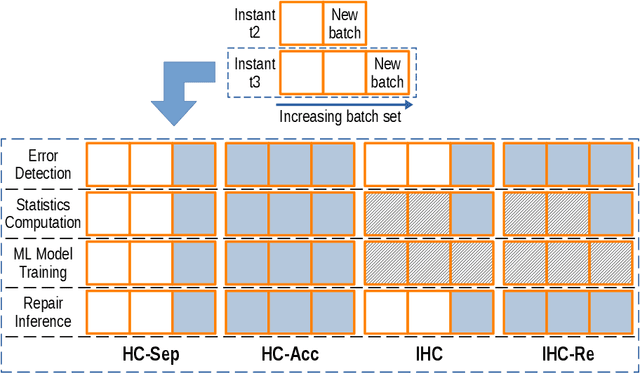
Lack of data and data quality issues are among the main bottlenecks that prevent further artificial intelligence adoption within many organizations, pushing data scientists to spend most of their time cleaning data before being able to answer analytical questions. Hence, there is a need for more effective and efficient data cleaning solutions, which, not surprisingly, is rife with theoretical and engineering problems. This report addresses the problem of performing holistic data cleaning incrementally, given a fixed rule set and an evolving categorical relational dataset acquired in sequential batches. To the best of our knowledge, our contributions compose the first incremental framework that cleans data (i) independently of user interventions, (ii) without requiring knowledge about the incoming dataset, such as the number of classes per attribute, and (iii) holistically, enabling multiple error types to be repaired simultaneously, and thus avoiding conflicting repairs. Extensive experiments show that our approach outperforms the competitors with respect to repair quality, execution time, and memory consumption.
On sampling from data with duplicate records
Aug 24, 2020
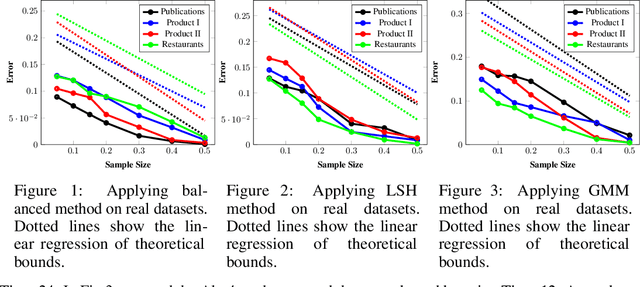
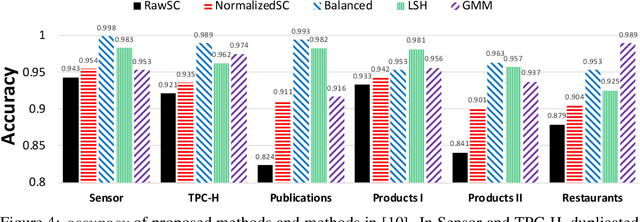
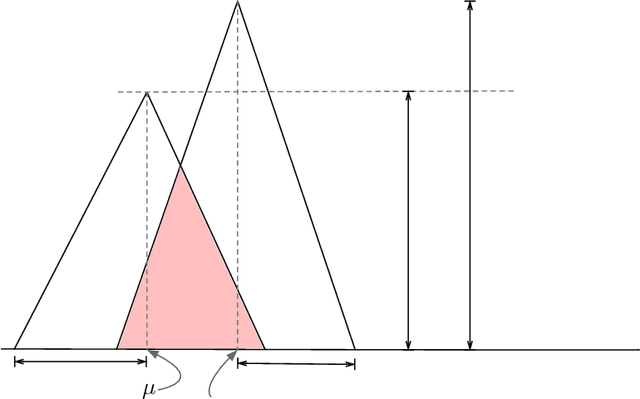
Data deduplication is the task of detecting records in a database that correspond to the same real-world entity. Our goal is to develop a procedure that samples uniformly from the set of entities present in the database in the presence of duplicates. We accomplish this by a two-stage process. In the first step, we estimate the frequencies of all the entities in the database. In the second step, we use rejection sampling to obtain a (approximately) uniform sample from the set of entities. However, efficiently estimating the frequency of all the entities is a non-trivial task and not attainable in the general case. Hence, we consider various natural properties of the data under which such frequency estimation (and consequently uniform sampling) is possible. Under each of those assumptions, we provide sampling algorithms and give proofs of the complexity (both statistical and computational) of our approach. We complement our study by conducting extensive experiments on both real and synthetic datasets.
Record fusion: A learning approach
Jun 18, 2020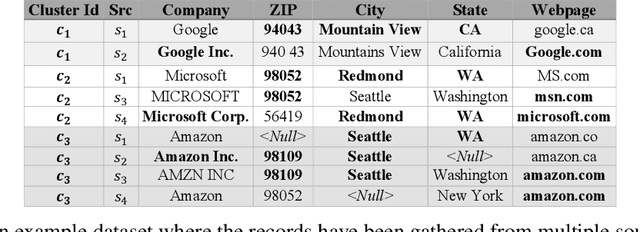
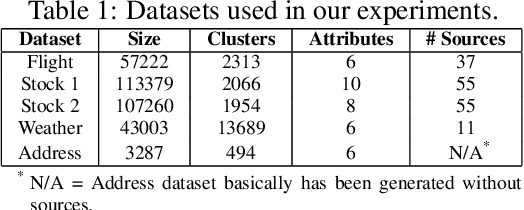
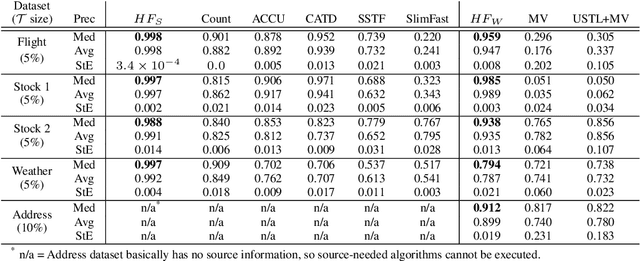
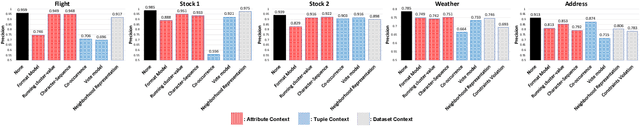
Record fusion is the task of aggregating multiple records that correspond to the same real-world entity in a database. We can view record fusion as a machine learning problem where the goal is to predict the "correct" value for each attribute for each entity. Given a database, we use a combination of attribute-level, recordlevel, and database-level signals to construct a feature vector for each cell (or (row, col)) of that database. We use this feature vector alongwith the ground-truth information to learn a classifier for each of the attributes of the database. Our learning algorithm uses a novel stagewise additive model. At each stage, we construct a new feature vector by combining a part of the original feature vector with features computed by the predictions from the previous stage. We then learn a softmax classifier over the new feature space. This greedy stagewise approach can be viewed as a deep model where at each stage, we are adding more complicated non-linear transformations of the original feature vector. We show that our approach fuses records with an average precision of ~98% when source information of records is available, and ~94% without source information across a diverse array of real-world datasets. We compare our approach to a comprehensive collection of data fusion and entity consolidation methods considered in the literature. We show that our approach can achieve an average precision improvement of ~20%/~45% with/without source information respectively.