 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrowing and Serving Large Open-domain Knowledge Graphs
Paper and Code
May 16, 2023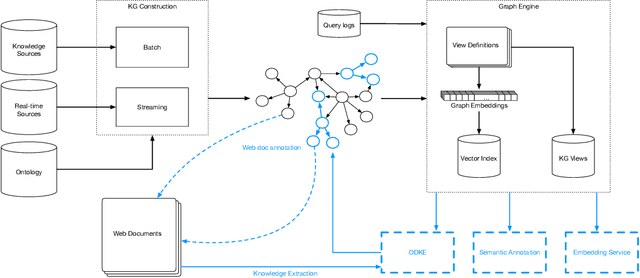
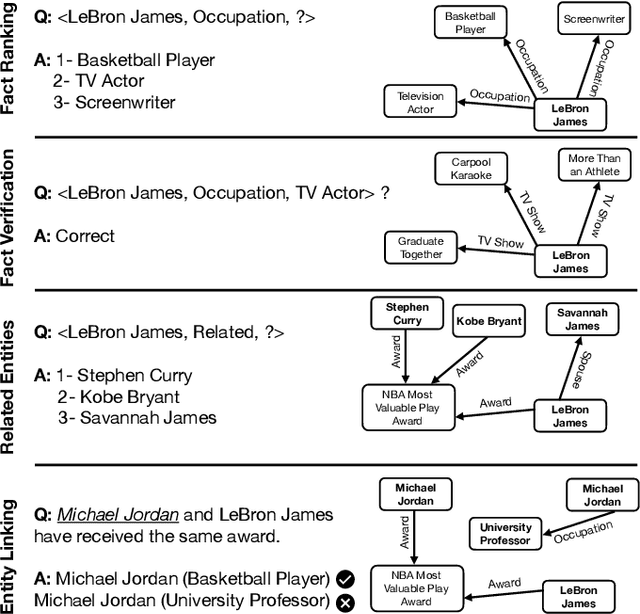
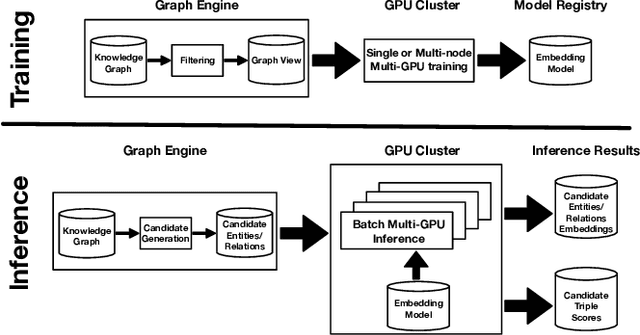
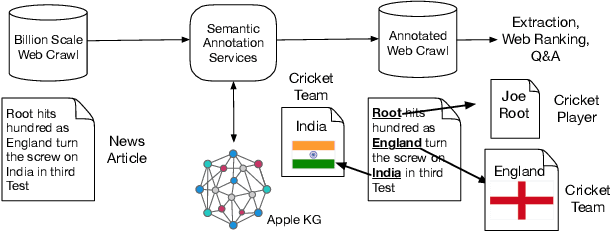
Applications of large open-domain knowledge graphs (KGs) to real-world problems pose many unique challenges. In this paper, we present extensions to Saga our platform for continuous construction and serving of knowledge at scale. In particular, we describe a pipeline for training knowledge graph embeddings that powers key capabilities such as fact ranking, fact verification, a related entities service, and support for entity linking. We then describe how our platform, including graph embeddings, can be leveraged to create a Semantic Annotation service that links unstructured Web documents to entities in our KG. Semantic annotation of the Web effectively expands our knowledge graph with edges to open-domain Web content which can be used in various search and ranking problems. Finally, we leverage annotated Web documents to drive Open-domain Knowledge Extraction. This targeted extraction framework identifies important coverage issues in the KG, then finds relevant data sources for target entities on the Web and extracts missing information to enrich the KG. Finally, we describe adaptations to our knowledge platform needed to construct and serve private personal knowledge on-device. This includes private incremental KG construction, cross-device knowledge sync, and global knowledge enrichment.