 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-LLM Collaborative Feature Engineering for Tabular Data
Jan 28, 2026Large language models (LLMs) are increasingly used to automate feature engineering in tabular learning. Given task-specific information, LLMs can propose diverse feature transformation operations to enhance downstream model performance. However, current approaches typically assign the LLM as a black-box optimizer, responsible for both proposing and selecting operations based solely on its internal heuristics, which often lack calibrated estimations of operation utility and consequently lead to repeated exploration of low-yield operations without a principled strategy for prioritizing promising directions. In this paper, we propose a human-LLM collaborative feature engineering framework for tabular learning. We begin by decoupling the transformation operation proposal and selection processes, where LLMs are used solely to generate operation candidates, while the selection is guided by explicitly modeling the utility and uncertainty of each proposed operation. Since accurate utility estimation can be difficult especially in the early rounds of feature engineering, we design a mechanism within the framework that selectively elicits and incorporates human expert preference feedback, comparing which operations are more promising, into the selection process to help identify more effective operations. Our evaluations on both the synthetic study and the real user study demonstrate that the proposed framework improves feature engineering performance across a variety of tabular datasets and reduces users' cognitive load during the feature engineering process.
Evaluation and Incident Prevention in an Enterprise AI Assistant
Apr 11, 2025



Enterprise AI Assistants are increasingly deployed in domains where accuracy is paramount, making each erroneous output a potentially significant incident. This paper presents a comprehensive framework for monitoring, benchmarking, and continuously improving such complex, multi-component systems under active development by multiple teams. Our approach encompasses three key elements: (1) a hierarchical ``severity'' framework for incident detection that identifies and categorizes errors while attributing component-specific error rates, facilitating targeted improvements; (2) a scalable and principled methodology for benchmark construction, evaluation, and deployment, designed to accommodate multiple development teams, mitigate overfitting risks, and assess the downstream impact of system modifications; and (3) a continual improvement strategy leveraging multidimensional evaluation, enabling the identification and implementation of diverse enhancement opportunities. By adopting this holistic framework, organizations can systematically enhance the reliability and performance of their AI Assistants, ensuring their efficacy in critical enterprise environments. We conclude by discussing how this multifaceted evaluation approach opens avenues for various classes of enhancements, paving the way for more robust and trustworthy AI systems.
ECLAIR: Enhanced Clarification for Interactive Responses
Mar 19, 2025



We present ECLAIR (Enhanced CLArification for Interactive Responses), a novel unified and end-to-end framework for interactive disambiguation in enterprise AI assistants. ECLAIR generates clarification questions for ambiguous user queries and resolves ambiguity based on the user's response.We introduce a generalized architecture capable of integrating ambiguity information from multiple downstream agents, enhancing context-awareness in resolving ambiguities and allowing enterprise specific definition of agents. We further define agents within our system that provide domain-specific grounding information. We conduct experiments comparing ECLAIR to few-shot prompting techniques and demonstrate ECLAIR's superior performance in clarification question generation and ambiguity resolution.
Text-to-SQL Domain Adaptation via Human-LLM Collaborative Data Annotation
Feb 21, 2025Text-to-SQL models, which parse natural language (NL) questions to executable SQL queries, are increasingly adopted in real-world applications. However, deploying such models in the real world often requires adapting them to the highly specialized database schemas used in specific applications. We find that existing text-to-SQL models experience significant performance drops when applied to new schemas, primarily due to the lack of domain-specific data for fine-tuning. This data scarcity also limits the ability to effectively evaluate model performance in new domains. Continuously obtaining high-quality text-to-SQL data for evolving schemas is prohibitively expensive in real-world scenarios. To bridge this gap, we propose SQLsynth, a human-in-the-loop text-to-SQL data annotation system. SQLsynth streamlines the creation of high-quality text-to-SQL datasets through human-LLM collaboration in a structured workflow. A within-subjects user study comparing SQLsynth with manual annotation and ChatGPT shows that SQLsynth significantly accelerates text-to-SQL data annotation, reduces cognitive load, and produces datasets that are more accurate, natural, and diverse. Our code is available at https://github.com/adobe/nl_sql_analyzer.
Comprehensive Evaluation for a Large Scale Knowledge Graph Question Answering Service
Jan 28, 2025



Question answering systems for knowledge graph (KGQA), answer factoid questions based on the data in the knowledge graph. KGQA systems are complex because the system has to understand the relations and entities in the knowledge-seeking natural language queries and map them to structured queries against the KG to answer them. In this paper, we introduce Chronos, a comprehensive evaluation framework for KGQA at industry scale. It is designed to evaluate such a multi-component system comprehensively, focusing on (1) end-to-end and component-level metrics, (2) scalable to diverse datasets and (3) a scalable approach to measure the performance of the system prior to release. In this paper, we discuss the unique challenges associated with evaluating KGQA systems at industry scale, review the design of Chronos, and how it addresses these challenges. We will demonstrate how it provides a base for data-driven decisions and discuss the challenges of using it to measure and improve a real-world KGQA system.
Federated Retrieval Augmented Generation for Multi-Product Question Answering
Jan 25, 2025



Recent advancements in Large Language Models and Retrieval-Augmented Generation have boosted interest in domain-specific question-answering for enterprise products. However, AI Assistants often face challenges in multi-product QA settings, requiring accurate responses across diverse domains. Existing multi-domain RAG-QA approaches either query all domains indiscriminately, increasing computational costs and LLM hallucinations, or rely on rigid resource selection, which can limit search results. We introduce MKP-QA, a novel multi-product knowledge-augmented QA framework with probabilistic federated search across domains and relevant knowledge. This method enhances multi-domain search quality by aggregating query-domain and query-passage probabilistic relevance. To address the lack of suitable benchmarks for multi-product QAs, we also present new datasets focused on three Adobe products: Adobe Experience Platform, Target, and Customer Journey Analytics. Our experiments show that MKP-QA significantly boosts multi-product RAG-QA performance in terms of both retrieval accuracy and response quality.
KG-TRICK: Unifying Textual and Relational Information Completion of Knowledge for Multilingual Knowledge Graphs
Jan 07, 2025



Multilingual knowledge graphs (KGs) provide high-quality relational and textual information for various NLP applications, but they are often incomplete, especially in non-English languages. Previous research has shown that combining information from KGs in different languages aids either Knowledge Graph Completion (KGC), the task of predicting missing relations between entities, or Knowledge Graph Enhancement (KGE), the task of predicting missing textual information for entities. Although previous efforts have considered KGC and KGE as independent tasks, we hypothesize that they are interdependent and mutually beneficial. To this end, we introduce KG-TRICK, a novel sequence-to-sequence framework that unifies the tasks of textual and relational information completion for multilingual KGs. KG-TRICK demonstrates that: i) it is possible to unify the tasks of KGC and KGE into a single framework, and ii) combining textual information from multiple languages is beneficial to improve the completeness of a KG. As part of our contributions, we also introduce WikiKGE10++, the largest manually-curated benchmark for textual information completion of KGs, which features over 25,000 entities across 10 diverse languages.
Enhancing Discoverability in Enterprise Conversational Systems with Proactive Question Suggestions
Dec 14, 2024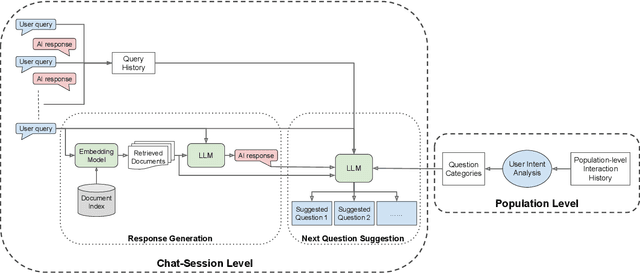

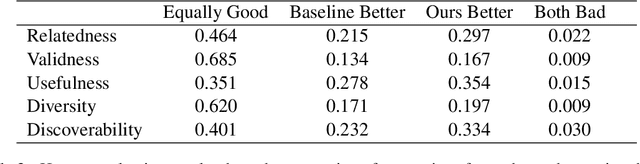

Enterprise conversational AI systems are becoming increasingly popular to assist users in completing daily tasks such as those in marketing and customer management. However, new users often struggle to ask effective questions, especially in emerging systems with unfamiliar or evolving capabilities. This paper proposes a framework to enhance question suggestions in conversational enterprise AI systems by generating proactive, context-aware questions that try to address immediate user needs while improving feature discoverability. Our approach combines periodic user intent analysis at the population level with chat session-based question generation. We evaluate the framework using real-world data from the AI Assistant for Adobe Experience Platform (AEP), demonstrating the improved usefulness and system discoverability of the AI Assistant.
HierTOD: A Task-Oriented Dialogue System Driven by Hierarchical Goals
Nov 11, 2024



Task-Oriented Dialogue (TOD) systems assist users in completing tasks through natural language interactions, often relying on a single-layered workflow structure for slot-filling in public tasks, such as hotel bookings. However, in enterprise environments, which involve rich domain-specific knowledge, TOD systems face challenges due to task complexity and the lack of standardized documentation. In this work, we introduce HierTOD, an enterprise TOD system driven by hierarchical goals and can support composite workflows. By focusing on goal-driven interactions, our system serves a more proactive role, facilitating mixed-initiative dialogue and improving task completion. Equipped with components for natural language understanding, composite goal retriever, dialogue management, and response generation, backed by a well-organized data service with domain knowledge base and retrieval engine, HierTOD delivers efficient task assistance. Furthermore, our system implementation unifies two TOD paradigms: slot-filling for information collection and step-by-step guidance for task execution. Our human study demonstrates the effectiveness and helpfulness of HierTOD in performing both paradigms.
Towards Cross-Cultural Machine Translation with Retrieval-Augmented Generation from Multilingual Knowledge Graphs
Oct 17, 2024



Translating text that contains entity names is a challenging task, as cultural-related references can vary significantly across languages. These variations may also be caused by transcreation, an adaptation process that entails more than transliteration and word-for-word translation. In this paper, we address the problem of cross-cultural translation on two fronts: (i) we introduce XC-Translate, the first large-scale, manually-created benchmark for machine translation that focuses on text that contains potentially culturally-nuanced entity names, and (ii) we propose KG-MT, a novel end-to-end method to integrate information from a multilingual knowledge graph into a neural machine translation model by leveraging a dense retrieval mechanism. Our experiments and analyses show that current machine translation systems and large language models still struggle to translate texts containing entity names, whereas KG-MT outperforms state-of-the-art approaches by a large margin, obtaining a 129% and 62% relative improvement compared to NLLB-200 and GPT-4, respectively.