 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpanding LLM Agent Boundaries with Strategy-Guided Exploration
Mar 02, 2026Reinforcement learning (RL) has demonstrated notable success in post-training large language models (LLMs) as agents for tasks such as computer use, tool calling, and coding. However, exploration remains a central challenge in RL for LLM agents, especially as they operate in language-action spaces with complex observations and sparse outcome rewards. In this work, we address exploration for LLM agents by leveraging the ability of LLMs to plan and reason in language about the environment to shift exploration from low-level actions to higher-level language strategies. We thus propose Strategy-Guided Exploration (SGE), which first generates a concise natural-language strategy that describes what to do to make progress toward the goal, and then generates environment actions conditioned on that strategy. By exploring in the space of strategies rather than the space of actions, SGE induces structured and diverse exploration that targets different environment outcomes. To increase strategy diversity during RL, SGE introduces mixed-temperature sampling, which explores diverse strategies in parallel, along with a strategy reflection process that grounds strategy generation on the outcomes of previous strategies in the environment. Across UI interaction, tool-calling, coding, and embodied agent environments, SGE consistently outperforms exploration-focused RL baselines, improving both learning efficiency and final performance. We show that SGE enables the agent to learn to solve tasks too difficult for the base model.
ASTRA-bench: Evaluating Tool-Use Agent Reasoning and Action Planning with Personal User Context
Mar 02, 2026Next-generation AI must manage vast personal data, diverse tools, and multi-step reasoning, yet most benchmarks remain context-free and single-turn. We present ASTRA-bench (Assistant Skills in Tool-use, Reasoning \& Action-planning), a benchmark that uniquely unifies time-evolving personal context with an interactive toolbox and complex user intents. Our event-driven pipeline generates 2,413 scenarios across four protagonists, grounded in longitudinal life events and annotated by referential, functional, and informational complexity. Evaluation of state-of-the-art models (e.g., Claude-4.5-Opus, DeepSeek-V3.2) reveals significant performance degradation under high-complexity conditions, with argument generation emerging as the primary bottleneck. These findings expose critical limitations in current agents' ability to ground reasoning within messy personal context and orchestrate reliable multi-step plans. We release ASTRA-bench with a full execution environment and evaluation scripts to provide a diagnostic testbed for developing truly context-aware AI assistants.
GRACE: A Language Model Framework for Explainable Inverse Reinforcement Learning
Oct 02, 2025Inverse Reinforcement Learning aims to recover reward models from expert demonstrations, but traditional methods yield "black-box" models that are difficult to interpret and debug. In this work, we introduce GRACE (Generating Rewards As CodE), a method for using Large Language Models within an evolutionary search to reverse-engineer an interpretable, code-based reward function directly from expert trajectories. The resulting reward function is executable code that can be inspected and verified. We empirically validate GRACE on the BabyAI and AndroidWorld benchmarks, where it efficiently learns highly accurate rewards, even in complex, multi-task settings. Further, we demonstrate that the resulting reward leads to strong policies, compared to both competitive Imitation Learning and online RL approaches with ground-truth rewards. Finally, we show that GRACE is able to build complex reward APIs in multi-task setups.
Ferret-UI Lite: Lessons from Building Small On-Device GUI Agents
Sep 30, 2025
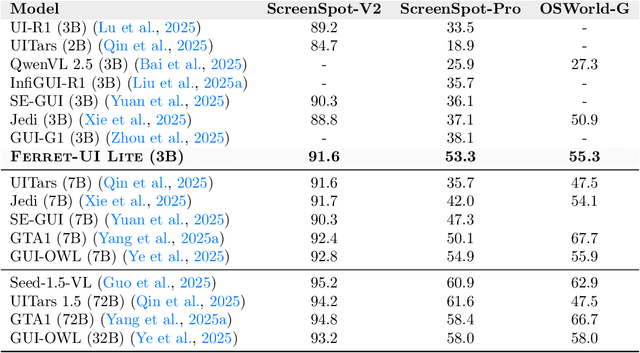
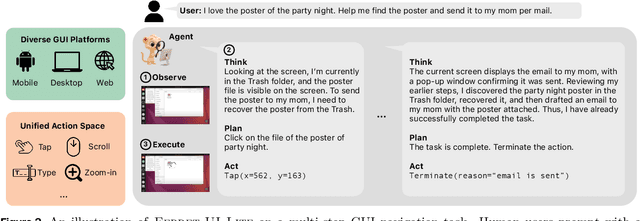
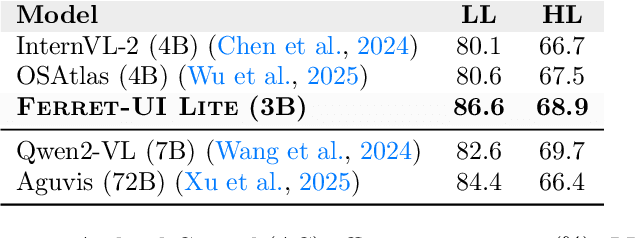
Developing autonomous agents that effectively interact with Graphic User Interfaces (GUIs) remains a challenging open problem, especially for small on-device models. In this paper, we present Ferret-UI Lite, a compact, end-to-end GUI agent that operates across diverse platforms, including mobile, web, and desktop. Utilizing techniques optimized for developing small models, we build our 3B Ferret-UI Lite agent through curating a diverse GUI data mixture from real and synthetic sources, strengthening inference-time performance through chain-of-thought reasoning and visual tool-use, and reinforcement learning with designed rewards. Ferret-UI Lite achieves competitive performance with other small-scale GUI agents. In GUI grounding, Ferret-UI Lite attains scores of $91.6\%$, $53.3\%$, and $61.2\%$ on the ScreenSpot-V2, ScreenSpot-Pro, and OSWorld-G benchmarks, respectively. For GUI navigation, Ferret-UI Lite achieves success rates of $28.0\%$ on AndroidWorld and $19.8\%$ on OSWorld. We share our methods and lessons learned from developing compact, on-device GUI agents.
Comprehensive Evaluation for a Large Scale Knowledge Graph Question Answering Service
Jan 28, 2025



Question answering systems for knowledge graph (KGQA), answer factoid questions based on the data in the knowledge graph. KGQA systems are complex because the system has to understand the relations and entities in the knowledge-seeking natural language queries and map them to structured queries against the KG to answer them. In this paper, we introduce Chronos, a comprehensive evaluation framework for KGQA at industry scale. It is designed to evaluate such a multi-component system comprehensively, focusing on (1) end-to-end and component-level metrics, (2) scalable to diverse datasets and (3) a scalable approach to measure the performance of the system prior to release. In this paper, we discuss the unique challenges associated with evaluating KGQA systems at industry scale, review the design of Chronos, and how it addresses these challenges. We will demonstrate how it provides a base for data-driven decisions and discuss the challenges of using it to measure and improve a real-world KGQA system.
From Multimodal LLMs to Generalist Embodied Agents: Methods and Lessons
Dec 11, 2024We examine the capability of Multimodal Large Language Models (MLLMs) to tackle diverse domains that extend beyond the traditional language and vision tasks these models are typically trained on. Specifically, our focus lies in areas such as Embodied AI, Games, UI Control, and Planning. To this end, we introduce a process of adapting an MLLM to a Generalist Embodied Agent (GEA). GEA is a single unified model capable of grounding itself across these varied domains through a multi-embodiment action tokenizer. GEA is trained with supervised learning on a large dataset of embodied experiences and with online RL in interactive simulators. We explore the data and algorithmic choices necessary to develop such a model. Our findings reveal the importance of training with cross-domain data and online RL for building generalist agents. The final GEA model achieves strong generalization performance to unseen tasks across diverse benchmarks compared to other generalist models and benchmark-specific approaches.
AGRaME: Any-Granularity Ranking with Multi-Vector Embeddings
May 23, 2024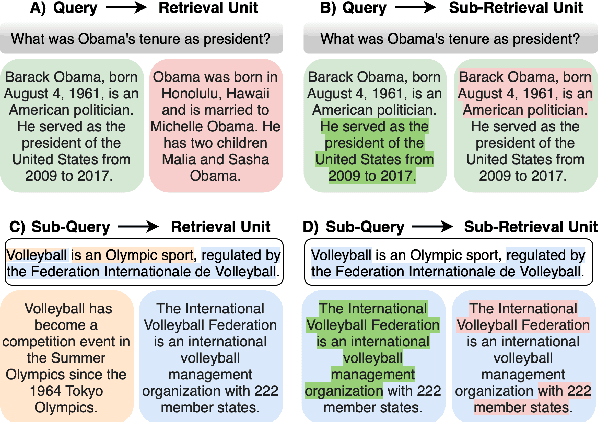


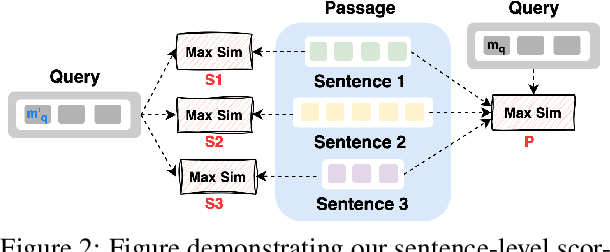
Ranking is a fundamental and popular problem in search. However, existing ranking algorithms usually restrict the granularity of ranking to full passages or require a specific dense index for each desired level of granularity. Such lack of flexibility in granularity negatively affects many applications that can benefit from more granular ranking, such as sentence-level ranking for open-domain question-answering, or proposition-level ranking for attribution. In this work, we introduce the idea of any-granularity ranking, which leverages multi-vector embeddings to rank at varying levels of granularity while maintaining encoding at a single (coarser) level of granularity. We propose a multi-granular contrastive loss for training multi-vector approaches, and validate its utility with both sentences and propositions as ranking units. Finally, we demonstrate the application of proposition-level ranking to post-hoc citation addition in retrieval-augmented generation, surpassing the performance of prompt-driven citation generation.
Entity Disambiguation via Fusion Entity Decoding
Apr 02, 2024
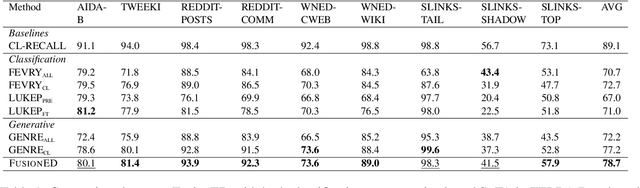


Entity disambiguation (ED), which links the mentions of ambiguous entities to their referent entities in a knowledge base, serves as a core component in entity linking (EL). Existing generative approaches demonstrate improved accuracy compared to classification approaches under the standardized ZELDA benchmark. Nevertheless, generative approaches suffer from the need for large-scale pre-training and inefficient generation. Most importantly, entity descriptions, which could contain crucial information to distinguish similar entities from each other, are often overlooked. We propose an encoder-decoder model to disambiguate entities with more detailed entity descriptions. Given text and candidate entities, the encoder learns interactions between the text and each candidate entity, producing representations for each entity candidate. The decoder then fuses the representations of entity candidates together and selects the correct entity. Our experiments, conducted on various entity disambiguation benchmarks, demonstrate the strong and robust performance of this model, particularly +1.5% in the ZELDA benchmark compared with GENRE. Furthermore, we integrate this approach into the retrieval/reader framework and observe +1.5% improvements in end-to-end entity linking in the GERBIL benchmark compared with EntQA.