 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropic Riemannian Neural Optimal Transport
May 05, 2026Many machine learning problems involve data supported on curved spaces such as spheres, rotation groups, hyperbolic spaces, and general Riemannian manifolds, where Euclidean geometry can distort distances, averages, and the resulting optimal transport (OT) problem. Existing manifold OT methods have pursued amortized out-of-sample maps, while entropic regularization has made discrete OT more scalable, but these advantages have remained largely disjoint. We propose Entropic Riemannian Neural Optimal Transport (Entropic RNOT), a unified framework that combines intrinsic entropic OT with amortized out-of-sample evaluation on Riemannian manifolds. Our method learns a single target-side Schrödinger potential through a neural pullback parameterization, recovers the induced Gibbs coupling, and uses the resulting conditional laws to construct intrinsic transport surrogates. These include barycentric projections on Cartan-Hadamard manifolds and heat-smoothed conditional surrogates on stochastically complete manifolds, the latter turning possibly atomic target laws into absolutely continuous ones. For fixed regularization $\varepsilon>0$, we prove that the proposed hypothesis class recovers the entropic optimal coupling in strong probabilistic metrics. As consequences, barycentric surrogates converge in $L^2$, while heat-smoothed surrogates are stable at fixed heat time and asymptotically unbiased as the heat time vanishes. The guarantees hold for compactly supported data on possibly noncompact manifolds. Empirically, our method matches or improves over Euclidean, tangent-space, and log-Euclidean baselines on benchmarks over $\mathbb{S}^2$, $\mathrm{SO}(3)$, $\mathrm{SPD}(3)$, $\mathrm{SE}(3)$, and $\mathbb{H}^2$, scales favorably relative to discrete manifold Sinkhorn, and in a protein-ligand docking application, refines poses on $\mathrm{SE}(3)$ without retraining or per-instance optimization.
GRACE: A Language Model Framework for Explainable Inverse Reinforcement Learning
Oct 02, 2025Inverse Reinforcement Learning aims to recover reward models from expert demonstrations, but traditional methods yield "black-box" models that are difficult to interpret and debug. In this work, we introduce GRACE (Generating Rewards As CodE), a method for using Large Language Models within an evolutionary search to reverse-engineer an interpretable, code-based reward function directly from expert trajectories. The resulting reward function is executable code that can be inspected and verified. We empirically validate GRACE on the BabyAI and AndroidWorld benchmarks, where it efficiently learns highly accurate rewards, even in complex, multi-task settings. Further, we demonstrate that the resulting reward leads to strong policies, compared to both competitive Imitation Learning and online RL approaches with ground-truth rewards. Finally, we show that GRACE is able to build complex reward APIs in multi-task setups.
Programming by Backprop: LLMs Acquire Reusable Algorithmic Abstractions During Code Training
Jun 23, 2025Training large language models (LLMs) on source code significantly enhances their general-purpose reasoning abilities, but the mechanisms underlying this generalisation are poorly understood. In this paper, we propose Programming by Backprop (PBB) as a potential driver of this effect - teaching a model to evaluate a program for inputs by training on its source code alone, without ever seeing I/O examples. To explore this idea, we finetune LLMs on two sets of programs representing simple maths problems and algorithms: one with source code and I/O examples (w/ IO), the other with source code only (w/o IO). We find evidence that LLMs have some ability to evaluate w/o IO programs for inputs in a range of experimental settings, and make several observations. Firstly, PBB works significantly better when programs are provided as code rather than semantically equivalent language descriptions. Secondly, LLMs can produce outputs for w/o IO programs directly, by implicitly evaluating the program within the forward pass, and more reliably when stepping through the program in-context via chain-of-thought. We further show that PBB leads to more robust evaluation of programs across inputs than training on I/O pairs drawn from a distribution that mirrors naturally occurring data. Our findings suggest a mechanism for enhanced reasoning through code training: it allows LLMs to internalise reusable algorithmic abstractions. Significant scope remains for future work to enable LLMs to more effectively learn from symbolic procedures, and progress in this direction opens other avenues like model alignment by training on formal constitutional principles.
The Complexity Dynamics of Grokking
Dec 13, 2024We investigate the phenomenon of generalization through the lens of compression. In particular, we study the complexity dynamics of neural networks to explain grokking, where networks suddenly transition from memorizing to generalizing solutions long after over-fitting the training data. To this end we introduce a new measure of intrinsic complexity for neural networks based on the theory of Kolmogorov complexity. Tracking this metric throughout network training, we find a consistent pattern in training dynamics, consisting of a rise and fall in complexity. We demonstrate that this corresponds to memorization followed by generalization. Based on insights from rate--distortion theory and the minimum description length principle, we lay out a principled approach to lossy compression of neural networks, and connect our complexity measure to explicit generalization bounds. Based on a careful analysis of information capacity in neural networks, we propose a new regularization method which encourages networks towards low-rank representations by penalizing their spectral entropy, and find that our regularizer outperforms baselines in total compression of the dataset.
Learning Loss Landscapes in Preference Optimization
Nov 10, 2024



We present an empirical study investigating how specific properties of preference datasets, such as mixed-quality or noisy data, affect the performance of Preference Optimization (PO) algorithms. Our experiments, conducted in MuJoCo environments, reveal several scenarios where state-of-the-art PO methods experience significant drops in performance. To address this issue, we introduce a novel PO framework based on mirror descent, which can recover existing methods like Direct Preference Optimization (DPO) and Odds-Ratio Preference Optimization (ORPO) for specific choices of the mirror map. Within this framework, we employ evolutionary strategies to discover new loss functions capable of handling the identified problematic scenarios. These new loss functions lead to significant performance improvements over DPO and ORPO across several tasks. Additionally, we demonstrate the generalization capability of our approach by applying the discovered loss functions to fine-tuning large language models using mixed-quality data, where they outperform ORPO.
EvIL: Evolution Strategies for Generalisable Imitation Learning
Jun 15, 2024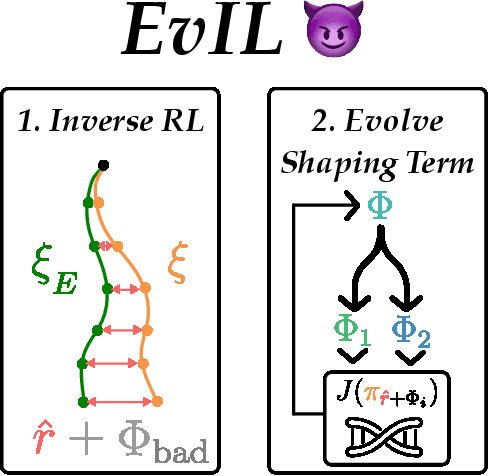
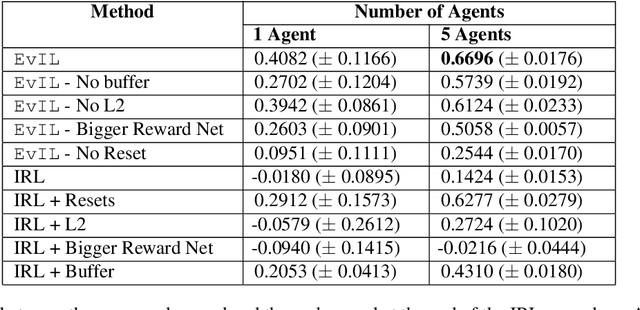


Often times in imitation learning (IL), the environment we collect expert demonstrations in and the environment we want to deploy our learned policy in aren't exactly the same (e.g. demonstrations collected in simulation but deployment in the real world). Compared to policy-centric approaches to IL like behavioural cloning, reward-centric approaches like inverse reinforcement learning (IRL) often better replicate expert behaviour in new environments. This transfer is usually performed by optimising the recovered reward under the dynamics of the target environment. However, (a) we find that modern deep IL algorithms frequently recover rewards which induce policies far weaker than the expert, even in the same environment the demonstrations were collected in. Furthermore, (b) these rewards are often quite poorly shaped, necessitating extensive environment interaction to optimise effectively. We provide simple and scalable fixes to both of these concerns. For (a), we find that reward model ensembles combined with a slightly different training objective significantly improves re-training and transfer performance. For (b), we propose a novel evolution-strategies based method EvIL to optimise for a reward-shaping term that speeds up re-training in the target environment, closing a gap left open by the classical theory of IRL. On a suite of continuous control tasks, we are able to re-train policies in target (and source) environments more interaction-efficiently than prior work.
Meta-learning the mirror map in policy mirror descent
Feb 07, 2024
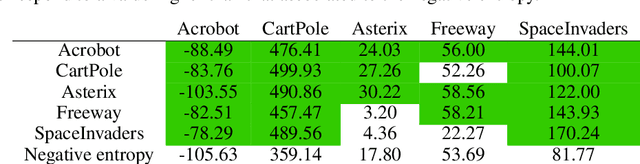
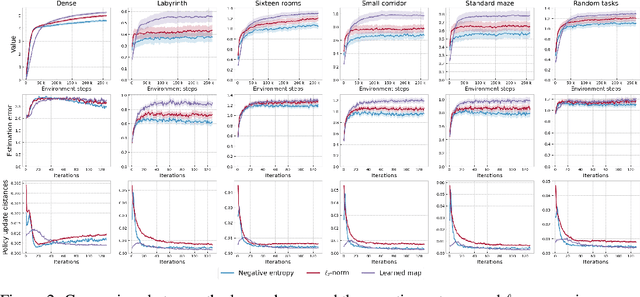
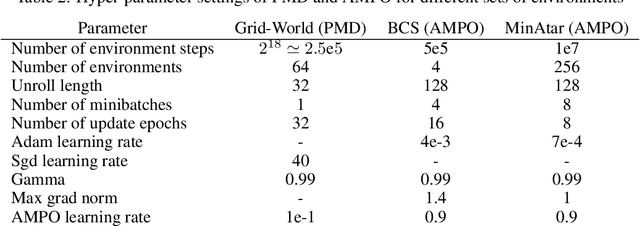
Policy Mirror Descent (PMD) is a popular framework in reinforcement learning, serving as a unifying perspective that encompasses numerous algorithms. These algorithms are derived through the selection of a mirror map and enjoy finite-time convergence guarantees. Despite its popularity, the exploration of PMD's full potential is limited, with the majority of research focusing on a particular mirror map -- namely, the negative entropy -- which gives rise to the renowned Natural Policy Gradient (NPG) method. It remains uncertain from existing theoretical studies whether the choice of mirror map significantly influences PMD's efficacy. In our work, we conduct empirical investigations to show that the conventional mirror map choice (NPG) often yields less-than-optimal outcomes across several standard benchmark environments. By applying a meta-learning approach, we identify more efficient mirror maps that enhance performance, both on average and in terms of best performance achieved along the training trajectory. We analyze the characteristics of these learned mirror maps and reveal shared traits among certain settings. Our results suggest that mirror maps have the potential to be adaptable across various environments, raising questions about how to best match a mirror map to an environment's structure and characteristics.
JAX-LOB: A GPU-Accelerated limit order book simulator to unlock large scale reinforcement learning for trading
Aug 25, 2023

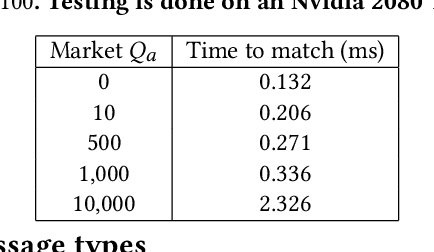
Financial exchanges across the world use limit order books (LOBs) to process orders and match trades. For research purposes it is important to have large scale efficient simulators of LOB dynamics. LOB simulators have previously been implemented in the context of agent-based models (ABMs), reinforcement learning (RL) environments, and generative models, processing order flows from historical data sets and hand-crafted agents alike. For many applications, there is a requirement for processing multiple books, either for the calibration of ABMs or for the training of RL agents. We showcase the first GPU-enabled LOB simulator designed to process thousands of books in parallel, with a notably reduced per-message processing time. The implementation of our simulator - JAX-LOB - is based on design choices that aim to best exploit the powers of JAX without compromising on the realism of LOB-related mechanisms. We integrate JAX-LOB with other JAX packages, to provide an example of how one may address an optimal execution problem with reinforcement learning, and to share some preliminary results from end-to-end RL training on GPUs.
Generative AI for End-to-End Limit Order Book Modelling: A Token-Level Autoregressive Generative Model of Message Flow Using a Deep State Space Network
Aug 23, 2023Developing a generative model of realistic order flow in financial markets is a challenging open problem, with numerous applications for market participants. Addressing this, we propose the first end-to-end autoregressive generative model that generates tokenized limit order book (LOB) messages. These messages are interpreted by a Jax-LOB simulator, which updates the LOB state. To handle long sequences efficiently, the model employs simplified structured state-space layers to process sequences of order book states and tokenized messages. Using LOBSTER data of NASDAQ equity LOBs, we develop a custom tokenizer for message data, converting groups of successive digits to tokens, similar to tokenization in large language models. Out-of-sample results show promising performance in approximating the data distribution, as evidenced by low model perplexity. Furthermore, the mid-price returns calculated from the generated order flow exhibit a significant correlation with the data, indicating impressive conditional forecast performance. Due to the granularity of generated data, and the accuracy of the model, it offers new application areas for future work beyond forecasting, e.g. acting as a world model in high-frequency financial reinforcement learning applications. Overall, our results invite the use and extension of the model in the direction of autoregressive large financial models for the generation of high-frequency financial data and we commit to open-sourcing our code to facilitate future research.
Ownership at Large -- Open Problems and Challenges in Ownership Management
Apr 15, 2020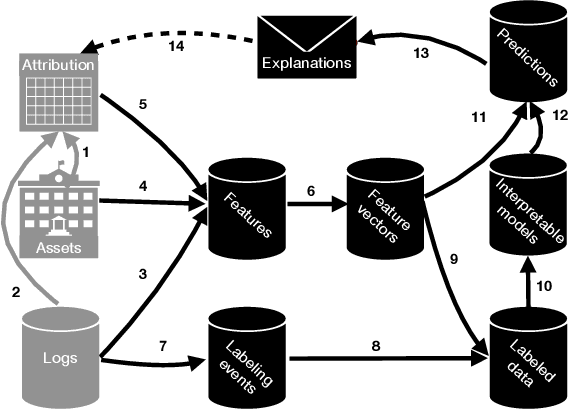
Software-intensive organizations rely on large numbers of software assets of different types, e.g., source-code files, tables in the data warehouse, and software configurations. Who is the most suitable owner of a given asset changes over time, e.g., due to reorganization and individual function changes. New forms of automation can help suggest more suitable owners for any given asset at a given point in time. By such efforts on ownership health, accountability of ownership is increased. The problem of finding the most suitable owners for an asset is essentially a program comprehension problem: how do we automatically determine who would be best placed to understand, maintain, evolve (and thereby assume ownership of) a given asset. This paper introduces the Facebook Ownesty system, which uses a combination of ultra large scale data mining and machine learning and has been deployed at Facebook as part of the company's ownership management approach. Ownesty processes many millions of software assets (e.g., source-code files) and it takes into account workflow and organizational aspects. The paper sets out open problems and challenges on ownership for the research community with advances expected from the fields of software engineering, programming languages, and machine learning.