 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLOB-Bench: Benchmarking Generative AI for Finance - an Application to Limit Order Book Data
Feb 13, 2025While financial data presents one of the most challenging and interesting sequence modelling tasks due to high noise, heavy tails, and strategic interactions, progress in this area has been hindered by the lack of consensus on quantitative evaluation paradigms. To address this, we present LOB-Bench, a benchmark, implemented in python, designed to evaluate the quality and realism of generative message-by-order data for limit order books (LOB) in the LOBSTER format. Our framework measures distributional differences in conditional and unconditional statistics between generated and real LOB data, supporting flexible multivariate statistical evaluation. The benchmark also includes features commonly used LOB statistics such as spread, order book volumes, order imbalance, and message inter-arrival times, along with scores from a trained discriminator network. Lastly, LOB-Bench contains "market impact metrics", i.e. the cross-correlations and price response functions for specific events in the data. We benchmark generative autoregressive state-space models, a (C)GAN, as well as a parametric LOB model and find that the autoregressive GenAI approach beats traditional model classes.
JAX-LOB: A GPU-Accelerated limit order book simulator to unlock large scale reinforcement learning for trading
Aug 25, 2023

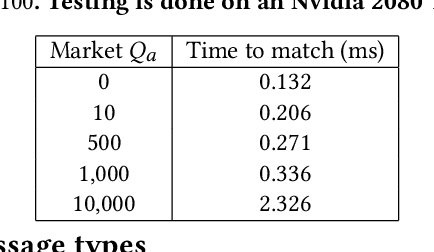
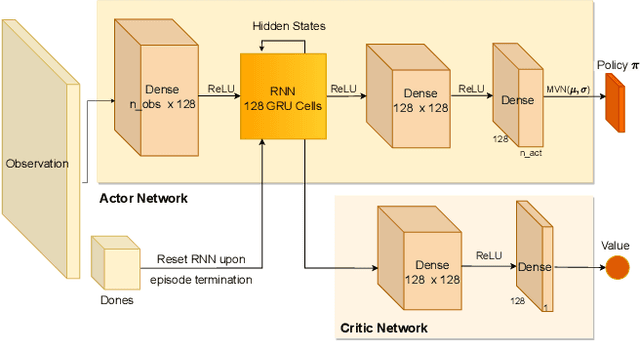
Financial exchanges across the world use limit order books (LOBs) to process orders and match trades. For research purposes it is important to have large scale efficient simulators of LOB dynamics. LOB simulators have previously been implemented in the context of agent-based models (ABMs), reinforcement learning (RL) environments, and generative models, processing order flows from historical data sets and hand-crafted agents alike. For many applications, there is a requirement for processing multiple books, either for the calibration of ABMs or for the training of RL agents. We showcase the first GPU-enabled LOB simulator designed to process thousands of books in parallel, with a notably reduced per-message processing time. The implementation of our simulator - JAX-LOB - is based on design choices that aim to best exploit the powers of JAX without compromising on the realism of LOB-related mechanisms. We integrate JAX-LOB with other JAX packages, to provide an example of how one may address an optimal execution problem with reinforcement learning, and to share some preliminary results from end-to-end RL training on GPUs.
Generative AI for End-to-End Limit Order Book Modelling: A Token-Level Autoregressive Generative Model of Message Flow Using a Deep State Space Network
Aug 23, 2023Developing a generative model of realistic order flow in financial markets is a challenging open problem, with numerous applications for market participants. Addressing this, we propose the first end-to-end autoregressive generative model that generates tokenized limit order book (LOB) messages. These messages are interpreted by a Jax-LOB simulator, which updates the LOB state. To handle long sequences efficiently, the model employs simplified structured state-space layers to process sequences of order book states and tokenized messages. Using LOBSTER data of NASDAQ equity LOBs, we develop a custom tokenizer for message data, converting groups of successive digits to tokens, similar to tokenization in large language models. Out-of-sample results show promising performance in approximating the data distribution, as evidenced by low model perplexity. Furthermore, the mid-price returns calculated from the generated order flow exhibit a significant correlation with the data, indicating impressive conditional forecast performance. Due to the granularity of generated data, and the accuracy of the model, it offers new application areas for future work beyond forecasting, e.g. acting as a world model in high-frequency financial reinforcement learning applications. Overall, our results invite the use and extension of the model in the direction of autoregressive large financial models for the generation of high-frequency financial data and we commit to open-sourcing our code to facilitate future research.
Asynchronous Deep Double Duelling Q-Learning for Trading-Signal Execution in Limit Order Book Markets
Jan 20, 2023



We employ deep reinforcement learning (RL) to train an agent to successfully translate a high-frequency trading signal into a trading strategy that places individual limit orders. Based on the ABIDES limit order book simulator, we build a reinforcement learning OpenAI gym environment and utilise it to simulate a realistic trading environment for NASDAQ equities based on historic order book messages. To train a trading agent that learns to maximise its trading return in this environment, we use Deep Duelling Double Q-learning with the APEX (asynchronous prioritised experience replay) architecture. The agent observes the current limit order book state, its recent history, and a short-term directional forecast. To investigate the performance of RL for adaptive trading independently from a concrete forecasting algorithm, we study the performance of our approach utilising synthetic alpha signals obtained by perturbing forward-looking returns with varying levels of noise. Here, we find that the RL agent learns an effective trading strategy for inventory management and order placing that outperforms a heuristic benchmark trading strategy having access to the same signal.