 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLOB-Bench: Benchmarking Generative AI for Finance - an Application to Limit Order Book Data
Feb 13, 2025While financial data presents one of the most challenging and interesting sequence modelling tasks due to high noise, heavy tails, and strategic interactions, progress in this area has been hindered by the lack of consensus on quantitative evaluation paradigms. To address this, we present LOB-Bench, a benchmark, implemented in python, designed to evaluate the quality and realism of generative message-by-order data for limit order books (LOB) in the LOBSTER format. Our framework measures distributional differences in conditional and unconditional statistics between generated and real LOB data, supporting flexible multivariate statistical evaluation. The benchmark also includes features commonly used LOB statistics such as spread, order book volumes, order imbalance, and message inter-arrival times, along with scores from a trained discriminator network. Lastly, LOB-Bench contains "market impact metrics", i.e. the cross-correlations and price response functions for specific events in the data. We benchmark generative autoregressive state-space models, a (C)GAN, as well as a parametric LOB model and find that the autoregressive GenAI approach beats traditional model classes.
Training Language Models for Social Deduction with Multi-Agent Reinforcement Learning
Feb 09, 2025



Communicating in natural language is a powerful tool in multi-agent settings, as it enables independent agents to share information in partially observable settings and allows zero-shot coordination with humans. However, most prior works are limited as they either rely on training with large amounts of human demonstrations or lack the ability to generate natural and useful communication strategies. In this work, we train language models to have productive discussions about their environment in natural language without any human demonstrations. We decompose the communication problem into listening and speaking. Our key idea is to leverage the agent's goal to predict useful information about the world as a dense reward signal that guides communication. Specifically, we improve a model's listening skills by training them to predict information about the environment based on discussions, and we simultaneously improve a model's speaking skills with multi-agent reinforcement learning by rewarding messages based on their influence on other agents. To investigate the role and necessity of communication in complex social settings, we study an embodied social deduction game based on Among Us, where the key question to answer is the identity of an adversarial imposter. We analyze emergent behaviors due to our technique, such as accusing suspects and providing evidence, and find that it enables strong discussions, doubling the win rates compared to standard RL. We release our code and models at https://socialdeductionllm.github.io/
Position Paper: Agent AI Towards a Holistic Intelligence
Feb 28, 2024Recent advancements in large foundation models have remarkably enhanced our understanding of sensory information in open-world environments. In leveraging the power of foundation models, it is crucial for AI research to pivot away from excessive reductionism and toward an emphasis on systems that function as cohesive wholes. Specifically, we emphasize developing Agent AI -- an embodied system that integrates large foundation models into agent actions. The emerging field of Agent AI spans a wide range of existing embodied and agent-based multimodal interactions, including robotics, gaming, and healthcare systems, etc. In this paper, we propose a novel large action model to achieve embodied intelligent behavior, the Agent Foundation Model. On top of this idea, we discuss how agent AI exhibits remarkable capabilities across a variety of domains and tasks, challenging our understanding of learning and cognition. Furthermore, we discuss the potential of Agent AI from an interdisciplinary perspective, underscoring AI cognition and consciousness within scientific discourse. We believe that those discussions serve as a basis for future research directions and encourage broader societal engagement.
An Interactive Agent Foundation Model
Feb 08, 2024



The development of artificial intelligence systems is transitioning from creating static, task-specific models to dynamic, agent-based systems capable of performing well in a wide range of applications. We propose an Interactive Agent Foundation Model that uses a novel multi-task agent training paradigm for training AI agents across a wide range of domains, datasets, and tasks. Our training paradigm unifies diverse pre-training strategies, including visual masked auto-encoders, language modeling, and next-action prediction, enabling a versatile and adaptable AI framework. We demonstrate the performance of our framework across three separate domains -- Robotics, Gaming AI, and Healthcare. Our model demonstrates its ability to generate meaningful and contextually relevant outputs in each area. The strength of our approach lies in its generality, leveraging a variety of data sources such as robotics sequences, gameplay data, large-scale video datasets, and textual information for effective multimodal and multi-task learning. Our approach provides a promising avenue for developing generalist, action-taking, multimodal systems.
Agent AI: Surveying the Horizons of Multimodal Interaction
Jan 07, 2024



Multi-modal AI systems will likely become a ubiquitous presence in our everyday lives. A promising approach to making these systems more interactive is to embody them as agents within physical and virtual environments. At present, systems leverage existing foundation models as the basic building blocks for the creation of embodied agents. Embedding agents within such environments facilitates the ability of models to process and interpret visual and contextual data, which is critical for the creation of more sophisticated and context-aware AI systems. For example, a system that can perceive user actions, human behavior, environmental objects, audio expressions, and the collective sentiment of a scene can be used to inform and direct agent responses within the given environment. To accelerate research on agent-based multimodal intelligence, we define "Agent AI" as a class of interactive systems that can perceive visual stimuli, language inputs, and other environmentally-grounded data, and can produce meaningful embodied action with infinite agent. In particular, we explore systems that aim to improve agents based on next-embodied action prediction by incorporating external knowledge, multi-sensory inputs, and human feedback. We argue that by developing agentic AI systems in grounded environments, one can also mitigate the hallucinations of large foundation models and their tendency to generate environmentally incorrect outputs. The emerging field of Agent AI subsumes the broader embodied and agentic aspects of multimodal interactions. Beyond agents acting and interacting in the physical world, we envision a future where people can easily create any virtual reality or simulated scene and interact with agents embodied within the virtual environment.
Diverse Conventions for Human-AI Collaboration
Oct 24, 2023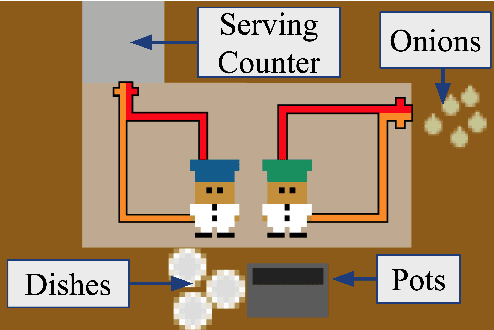

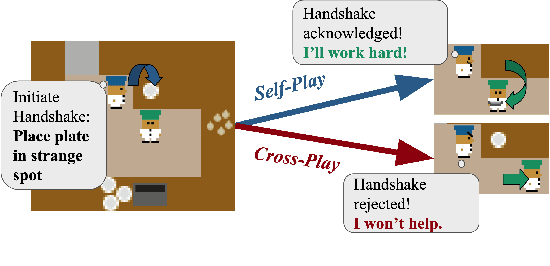

Conventions are crucial for strong performance in cooperative multi-agent games, because they allow players to coordinate on a shared strategy without explicit communication. Unfortunately, standard multi-agent reinforcement learning techniques, such as self-play, converge to conventions that are arbitrary and non-diverse, leading to poor generalization when interacting with new partners. In this work, we present a technique for generating diverse conventions by (1) maximizing their rewards during self-play, while (2) minimizing their rewards when playing with previously discovered conventions (cross-play), stimulating conventions to be semantically different. To ensure that learned policies act in good faith despite the adversarial optimization of cross-play, we introduce \emph{mixed-play}, where an initial state is randomly generated by sampling self-play and cross-play transitions and the player learns to maximize the self-play reward from this initial state. We analyze the benefits of our technique on various multi-agent collaborative games, including Overcooked, and find that our technique can adapt to the conventions of humans, surpassing human-level performance when paired with real users.
Physically Grounded Vision-Language Models for Robotic Manipulation
Sep 13, 2023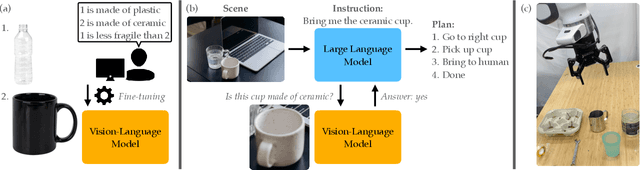

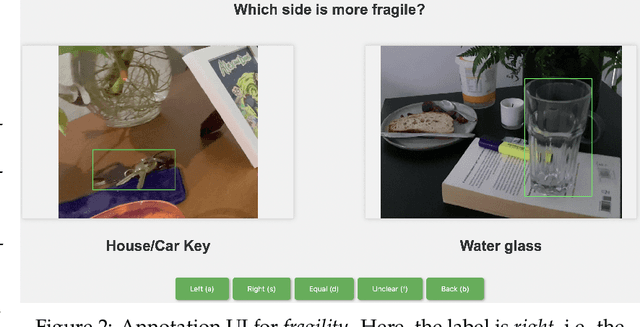
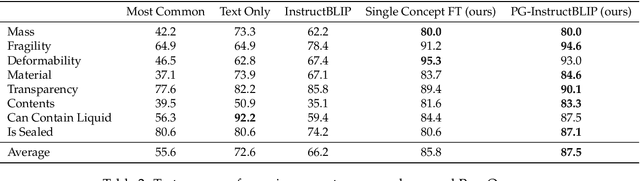
Recent advances in vision-language models (VLMs) have led to improved performance on tasks such as visual question answering and image captioning. Consequently, these models are now well-positioned to reason about the physical world, particularly within domains such as robotic manipulation. However, current VLMs are limited in their understanding of the physical concepts (e.g., material, fragility) of common objects, which restricts their usefulness for robotic manipulation tasks that involve interaction and physical reasoning about such objects. To address this limitation, we propose PhysObjects, an object-centric dataset of 39.6K crowd-sourced and 417K automated physical concept annotations of common household objects. We demonstrate that fine-tuning a VLM on PhysObjects improves its understanding of physical object concepts, including generalization to held-out concepts, by capturing human priors of these concepts from visual appearance. We incorporate this physically-grounded VLM in an interactive framework with a large language model-based robotic planner, and show improved planning performance on tasks that require reasoning about physical object concepts, compared to baselines that do not leverage physically-grounded VLMs. We additionally illustrate the benefits of our physically-grounded VLM on a real robot, where it improves task success rates. We release our dataset and provide further details and visualizations of our results at https://iliad.stanford.edu/pg-vlm/.
PantheonRL: A MARL Library for Dynamic Training Interactions
Dec 13, 2021
We present PantheonRL, a multiagent reinforcement learning software package for dynamic training interactions such as round-robin, adaptive, and ad-hoc training. Our package is designed around flexible agent objects that can be easily configured to support different training interactions, and handles fully general multiagent environments with mixed rewards and n agents. Built on top of StableBaselines3, our package works directly with existing powerful deep RL algorithms. Finally, PantheonRL comes with an intuitive yet functional web user interface for configuring experiments and launching multiple asynchronous jobs. Our package can be found at https://github.com/Stanford-ILIAD/PantheonRL.
Gaussian Process Policy Optimization
Mar 02, 2020

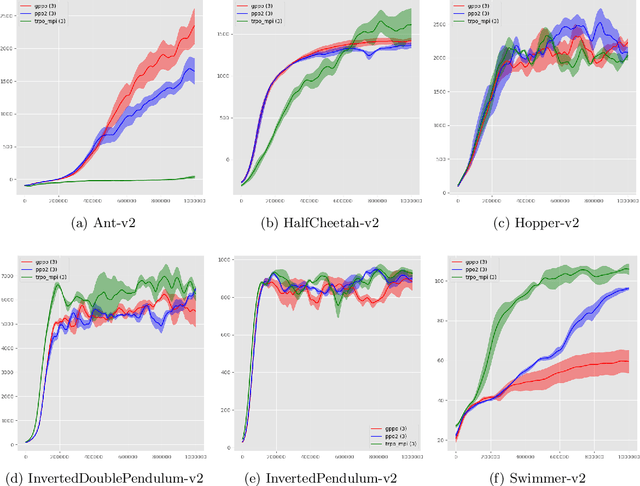
We propose a novel actor-critic, model-free reinforcement learning algorithm which employs a Bayesian method of parameter space exploration to solve environments. A Gaussian process is used to learn the expected return of a policy given the policy's parameters. The system is trained by updating the parameters using gradient descent on a new surrogate loss function consisting of the Proximal Policy Optimization 'Clipped' loss function and a bonus term representing the expected improvement acquisition function given by the Gaussian process. This new method is shown to be comparable to and at times empirically outperform current algorithms on environments that simulate robotic locomotion using the MuJoCo physics engine.